保定网站建设多少钱哪家好社区推广
安徽工程大学 考研难度(☆)
内容:23考情概况(拟录取和复试分析)、院校概况、23专业目录、23复试详情、各专业考情分析、各科目考情分析。
正文992字,预计阅读:3分钟
2023考情概况
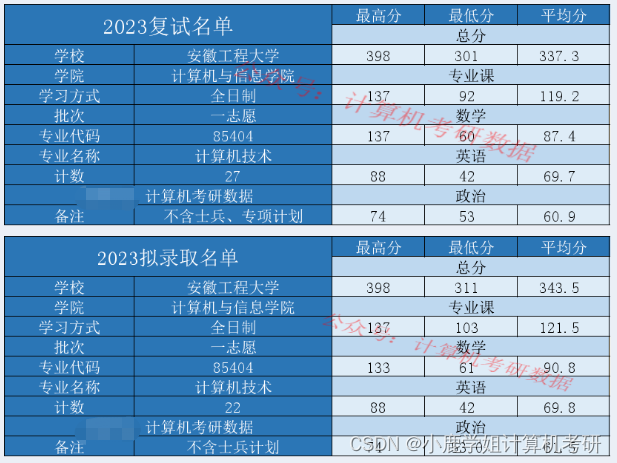
安徽工程大学计算机相关各专业复试和拟录取分析:
083500软件工程一志愿拟录取12人,平均分341.4,最高分365,最低分318;
085404计算机技术一志愿拟录取22人,平均分343.5,最高分398,最低分311。

院校概况
安徽工程大学,位于安徽省芜湖市,是一所以工为主的省属多科性高等院校和安徽省重点建设院校。
在第四轮学科评估中,安徽工程大学软件工程无评级,计算机科学与技术无评级。
安徽工程大学计算机相关院系:
计算机与信息学院
083500 软件工程
085404 计算机技术
安徽工程大学研究生部
https://grs.ahpu.edu.cn/
2023专业目录
计算机与信息学院
083500 软件工程
101思想政治理论
201英语一
302数学二
829数据结构与程序设计
复试科目:软件工程
085404 计算机技术
101思想政治理论
204英语二
302数学二
829数据结构与程序设计
复试科目:软件工程
参考书目:
《C语言程序设计》(第五版),谭浩强,清华大学出版社,2017;
《数据结构(C语言版)》,秦峰,清华大学出版社,2011。
《数据结构(C语言版)》,严蔚敏,2007。
《软件工程》(第四版),张海藩等,人民邮电出版社,2013
2023复试
一、复试分数线
根据教育部《2023年全国硕士研究生招生考试考生进入复试的初试成绩基本要求》,结合学校招生计划情况,按照差额复试比例要求确定一志愿复试名单,差额比例一般不低于120%
二、复试要求
笔试+面试
1.专业笔试。考试时间为2小时。笔试总分100分,笔试科目及要求见公布的招生专业目录。
2.综合面试。主要考核考生政治素质、专业素质、外语听说能力和综合素质等。综合面试总分100分,低于60分为不合格,每位考生综合面试时间一般不低于20分钟。
三、成绩计算
复试成绩=专业笔试成绩×60%+综合面试成绩×40%。
总成绩=(初试成绩÷5)×70%+复试成绩×30%
2023各科目考情分析
各专业复试和拟录取总分:

各专业进入复试和拟录取专业课分数:

各专业进入复试和拟录取政治科目分数:

各专业进入复试和拟录取数学科目分数:

各专业进入复试和拟录取外语科目分数:

2023各专业考情分析
计算机与信息学院
083500 软件工程
一志愿拟录取12人,平均分341.4,最高分365,最低分318;

085404 计算机技术
一志愿拟录取22人,平均分343.5,最高分398,最低分311。