网站建设知识平台wordpress注册无提示
一、什么是MQ
MQ(MessageQueue)
Message(消息):消息是在不同进程之间传递的数据,这些进程可以在同一台机器上,也可以在不同的机器上。
Queue(队列):队列原意是指一种具有FIFO(先进先出)特性的数据结构,是用来缓存数据的。
我们要学习的MQ产品对接的使用对象是应用程序。
它是一种在应用程序之间传递消息的通信方式,通过将消息发送到中间件(消息队列)来实现解耦和异步处理。消息队列允许发送者将消息放入队列中,而接收者可以从队列中获取消息进行处理。这种方式可以提高系统的可靠性、扩展性和灵活性,同时降低系统之间的依赖性和耦合度。常见的消息队列系统有RabbitMQ、Apache Kafka、RocketMQ。
二、MQ有什么作用
MQ的主要作用包括:
-
异步通信:通过消息队列,发送者和接收者之间的通信可以变为异步方式,发送者将消息放入队列后即可继续处理其他任务,而不需要等待接收者的响应。这能提高系统响应时间

-
解耦合:使用消息队列可以将不同模块或服务之间的耦合度降低。发送者只需要将消息发送到队列中,而不需要关心具体的接收者是谁,接收者也可以从队列中获取消息进行处理,而不需要知道消息的来源。当下游服务出现问题无法提供服务时,不会影响到上游服务继续提供服务,这一点在分布式系统中尤为重要。
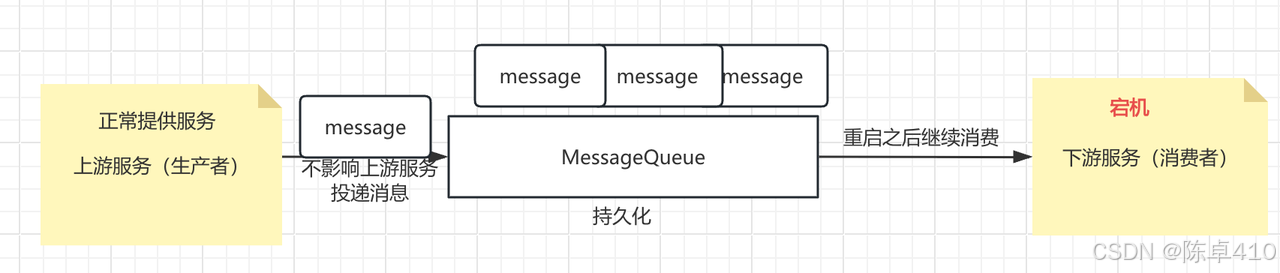
-
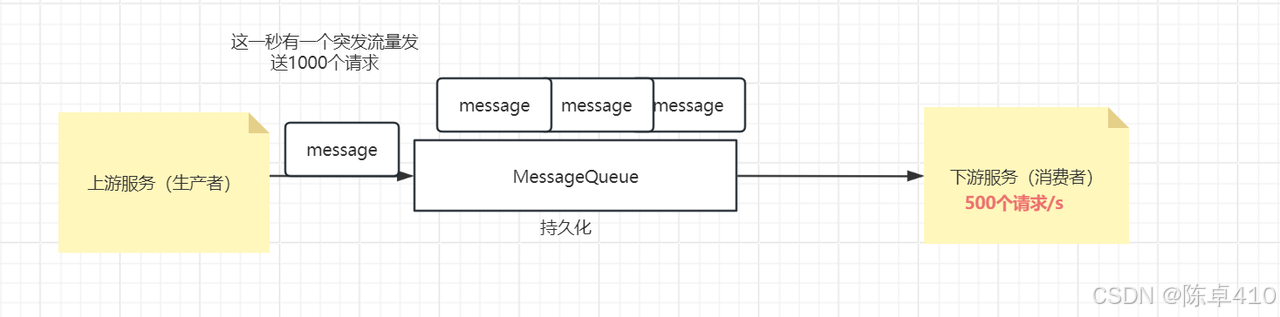
缓冲和削峰:当发送者产生大量请求时,消息队列可以作为缓冲区,暂时存储这些请求,然后由接收者按照自己的处理能力逐个处理。同时,当请求过多导致系统压力过大时,消息队列可以平滑地削峰,避免系统崩溃或性能下降。
三、MQ介绍及选型
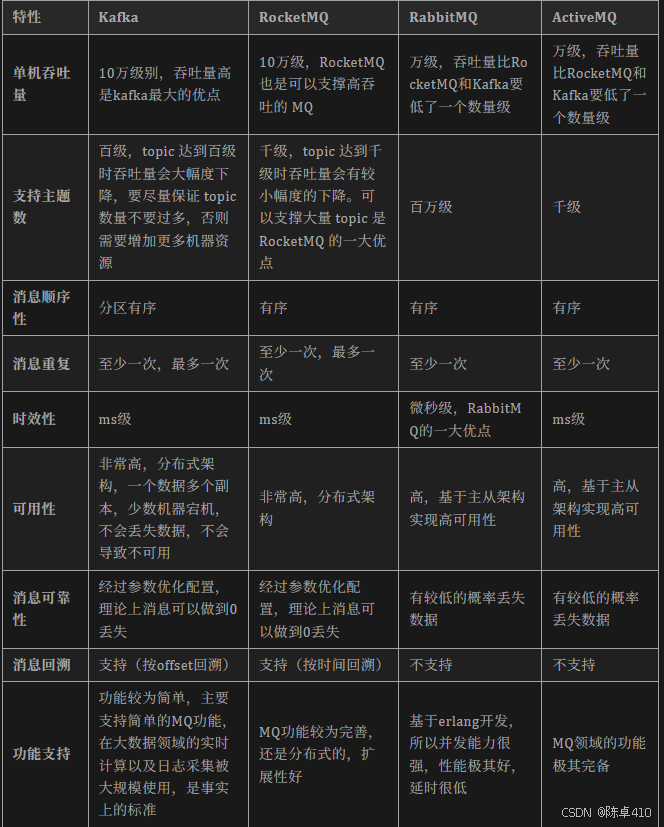
RabbitMQ
- 遵从AMQP协议
AMQP简单来说就是规定好了MQ的各个抽象组件,使得很好被开源框架所集成,比如Spring AMQP专门就是用来操作AMQP架构的中间件的,因此RabbitMQ可以被Spring Boot很方便的集成。 - 丰富的消费模型:Fanout(广播)、direct(精确路由)、topic(模糊路由)
- 消息延迟低(微秒级)
- 吞吐量不高
- 使用erlang语言,使得其根据业务进行二次开发的成本比较高
RocketMQ
RocketMQ出自阿里公司的开源产品,用 Java 语言实现,在设计时参考了 Kafka,并做出了自己的一些改进,消息可靠性上比 Kafka 更好。RocketMQ在阿里集团被广泛应用在订单,交易,充值,流计算,消息推送,日志流式处理,binglog分发等场景。
- 天生的分布式架构
- 消息可靠性和吞吐量都很高,以及丰富的消息消费模式使他适用于大多数业务场景
Kafka
Apache Kafka是一个分布式消息发布订阅系统。它最初由LinkedIn公司基于独特的设计实现为一个分布式的提交日志系统( a distributed commit log),之后成为Apache项目的一部分。Kafka系统快速、可扩展并且可持久化。它的分区特性,可复制和可容错都是其不错的特性。
- Kafka的设计目标是实现高吞吐量的消息传递,适用于处理大量的实时数据流。
- 支持的消费模式比较单一
具体企业开发中使用如何呢?
Kafka 一开始的目的就是用于日志收集和传输,适合有大量数据产生的互联网业务,特别是大数据领域的实时计算、日志采集等场景,用 Kafka 绝对没错,社区活跃度高,业内标准。
RocketMQ 特别适用于金融互联网领域这类对于可靠性要求很高的场景,比如订单交易等,而且 RocketMQ 是阿里出品的,经历过那么多次淘宝双十一的考验,大品牌,在稳定性值得信赖。但如果阿里不再维护这个技术了,社区有可能突然黄掉的风险。因此如果公司对自己的技术实力有自信,基础架构研发实力较强,推荐用 RocketMQ。
RabbitMQ 适用于公司对外提供能力,可能会有很多主题接入的中台业务场景,毕竟它是百万级主题数的。它的时效性是毫秒级的,但实际毫秒级和微秒级在感知上没有什么太大的区别,所以它的这一大优点并不太会作为考量标准。同时,它的功能是比较完善的,开源社区活跃度高,能解决开发中遇到的bug,所以万级别数据量业务场景的小公司可以优先选择功能完善的RabbitMQ。它的缺点就是用 Erlang 语言编写,所以很多开发人员很难去看懂源码并进行二次开发和维护,也就是说对于公司来说可能处于不可控的状态。
RocketMQ的核心部分概述
生产者(Producer)
RocketMQ生产者是消息的发送方,用于向RocketMQ中的主题发布消息。生产者负责将消息发送到指定的主题,并将消息传递给订阅该主题的消费者进行消费。
消费者(Consumer)
RocketMQ消费者是消息的接收方,用于从RocketMQ中的主题订阅消息并进行消费。消费者负责从指定的主题中拉取消息或者监听队列,然后对消息进行处理。
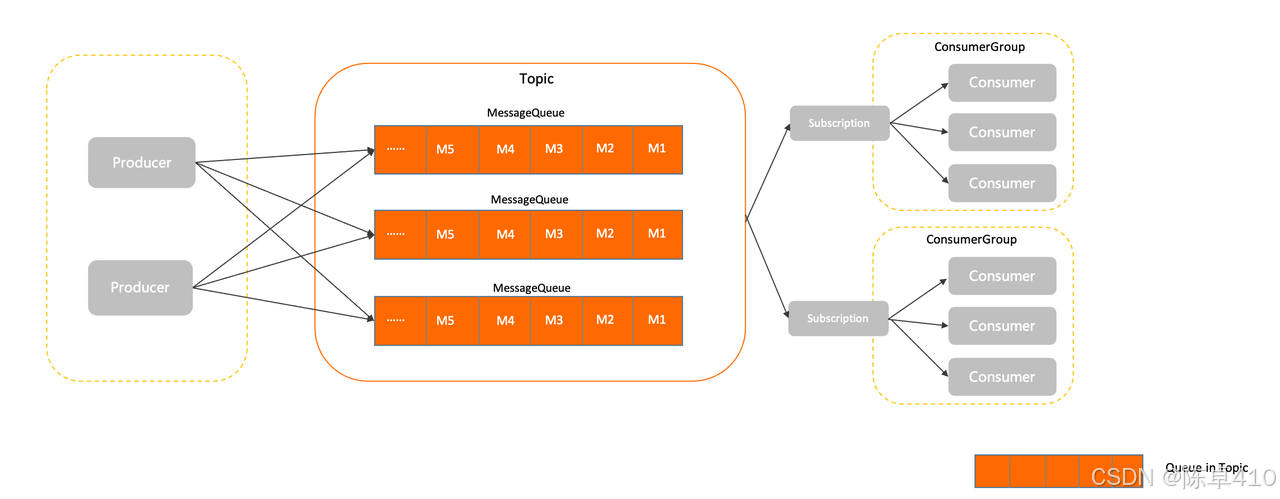
消费者组(ConsumerGroup)
- 为了消费能力的水平扩展,ConsumerGroup的概念应运而生。
RocketMQ消费者组是一组具有相同消费逻辑的消费者实例的集合。在RocketMQ中,一个主题可以由多个消费者组进行订阅和消费。
消费者组的主要作用是实现消息的负载均衡和容错能力。当一个主题有多个消费者组时,RocketMQ会将该主题的消息分配给各个消费者组进行处理。每个消费者组内的消费者实例则共同承担该组内消息的消费任务。这样做的好处是能够提高消息的消费速度和并发处理能力。
主题(Topic)
- 标识消息分类:RocketMQ的主题用于对消息进行分类和组织。通过为不同类型的消息分配不同的主题,可以使消息更具可读性和可管理性。
- 独立的消息队列:每个主题都有自己的消息队列,用于存储该主题下的消息。每个队列都可以并行地接收和处理消息,从而实现高吞吐量和负载均衡。
- 消息路由:生产者在发送消息时指定目标主题,消费者则通过订阅感兴趣的主题来接收对应的消息。RocketMQ根据主题将消息路由到相应的队列上,然后再由消费者消费。
NameServer
RocketMQ的NameServer是一个用于管理和维护消息队列的元数据信息的组件。它是RocketMQ的核心组件之一,负责记录每个Topic的路由信息和Broker的状态信息。
Broker
在RocketMQ中,Broker是消息队列的核心组件之一。它负责存储和转发消息,并提供消息的发布和订阅功能。他是一个物理概念,你可以认为他是一个服务节点。
MessageQueue
定义: 队列是 Apache RocketMQ 中消息存储和传输的实际容器,也是 Apache RocketMQ 消息的最小存储单元。 Apache RocketMQ 的所有主题都是由多个队列组成,以此实现队列数量的水平拆分和队列内部的流式存储。
为了消息写入能力的水平扩展,RocketMQ 对 Topic进行了分区,这种操作被称为队列(MessageQueue)。
对于RocketMQ同一个消费者组下的多个consumer需要与topic下的messagequeue建立对应关系,而一个messagequeue只能被一个consumer进行消费。因此增加的Conusmer实例最多也只能和Topic下的MessageQueue数量相等,如果继续增加就会有消费者空闲。
![[图片]](https://i-blog.csdnimg.cn/direct/2717938711424236b10c755b7111fed3.png)