网站设计名称wordpress设置html代码高亮
1、熟练掌握二进制、十进制和十六进制的转换方法。

多少进制就是多少之间相加,比如十六进制就是十六一次一加;二进制转化十六进制,分成四个一组。
2、C语言变量类型与取值范围,for、while等基本语句的用法。
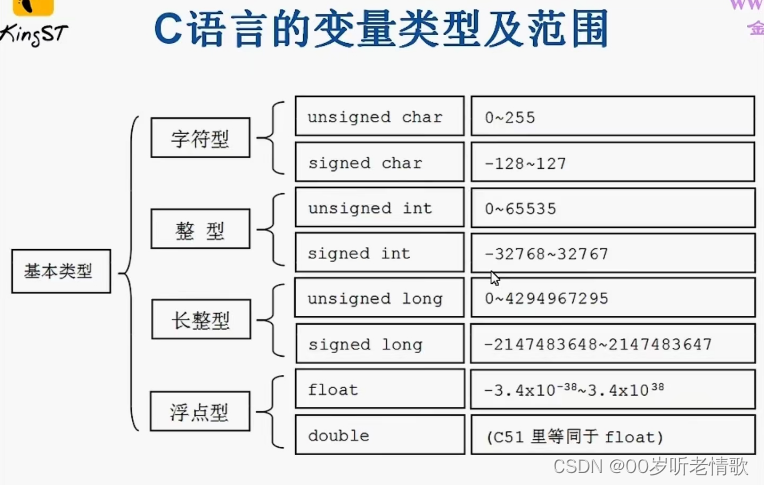
for、while等基本语句的用法教程链接:
https://blog.csdn.net/2301_77479336/article/details/130087491?spm=1001.2014.3001.5501
3、了解函数的基本结构,能够独立进入程序debug,并且多动手操作,熟练Keil软件的基本操作方法。
1)
2)run 全速运行,reset显示运行点。
4,独立成流水灯右移操作。
#include <REGX52.H>
sbit add0 = P1^0;
sbit add1 = P1^1;
sbit add2 = P1^2;
sbit add3 = P1^3;
sbit ENLED = P1^4;
unsigned int cnt = 1,i = 0;
void main()
{ENLED = 0;add3 = 1;add0 = 0;add1 = 1;add2 = 1;while(1)
{P0 = ~(0x80 >> cnt);for(i = 0;i < 20000;i++);cnt++;if(cnt >= 8)cnt = 1;}
}
5、独立完成一个左移到头接着右移,右移到头接着左移的花样流水灯程序。
#include <REGX52.H>
sbit add0 = P1^0;
sbit add1 = P1^1;
sbit add2 = P1^2;
sbit add3 = P1^3;
sbit ENLED = P1^4;
unsigned int cnt = 1,i ,a = 0,arr = 1;
void main()
{ENLED = 0;add3 = 1;add0 = 0;add1 = 1;add2 = 1;while(1)
{P0 = ~(0x80 >> cnt);for(i = 0;i < 20000;i++);cnt++;if(cnt >= 8){for(arr = 1;arr <= 8;arr++){P0 = ~(0x01 << arr);for(a = 0;a < 20000;a++);}if(arr >= 8){arr = 0;cnt = 0;}} }
}