最牛免费网站建设网站可以几个服务器
由于现在的idea在创建项目时已经不支持Java8版本了,如果我们还想用8版本,可以使用阿里云镜像创建。所以得改变原有的地址为:https://start.aliyun.com

springboot版本选择2开头的任意版本的。

1.配置6个依赖
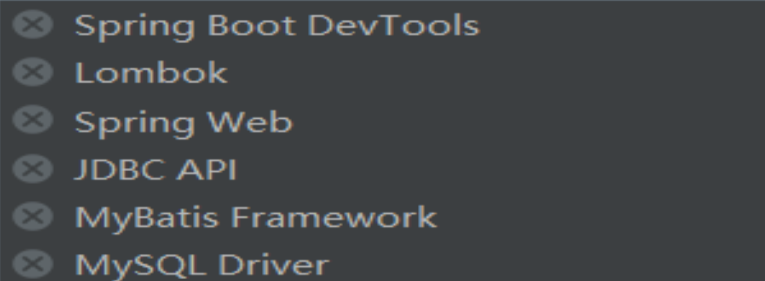
2.改变下载依赖地址
下载依赖默认的是访问国外,为了让下载依赖的速度更快,右键点击pom.xml找到settings.xml,进去将下载地址修改成阿里云的,然后保存并重启idea。
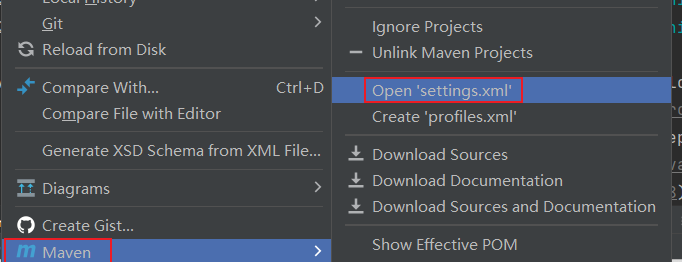
<mirror><id>alimaven</id><name>aliyun maven</name><url>http://maven.aliyun.com/nexus/content/groups/public/</url><mirrorOf>central</mirrorOf>
</mirror>3.下载插件 EditStarters
此插件能让我们在项目建成以后,还能随时随刻在idea内添加依赖,更方便。

下载并启用后,在pom.xml里右键

4.下载插件 Lombok
常用的setter,getter,Data注解。用于Javabean类中。
5.进行全局配置
在resource文件下创建application.yml,或者修改已经存在的后缀。将以下代码写入:
# 配置数据库的连接字符串
spring:
# jackson: # 设置全局的时间格式化 但对类型LocalDate不生效
# date-format: yyyy-MM-dd
# time-zone: GMT+8datasource:url: jdbc:mysql://127.0.0.1/testblog?characterEncoding=utf8username: rootpassword: 123456driver-class-name: com.mysql.cj.jdbc.Driver
# 设置 Mybatis 的 xml 保存路径
mybatis:mapper-locations: classpath:mapper/*Mapper.xmlconfiguration: # 配置打印 MyBatis 执行的 SQLlog-impl: org.apache.ibatis.logging.stdout.StdOutImpl
# 配置打印 MyBatis 执行的 SQL
logging:level:com:example:demo: debug6.打包
项目编写完后,在pom.xml中插入下面代码,注意位置。
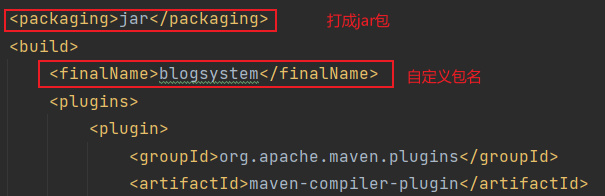
<packaging>war</packaging><build><finalName>blogsystem</finalName></build> 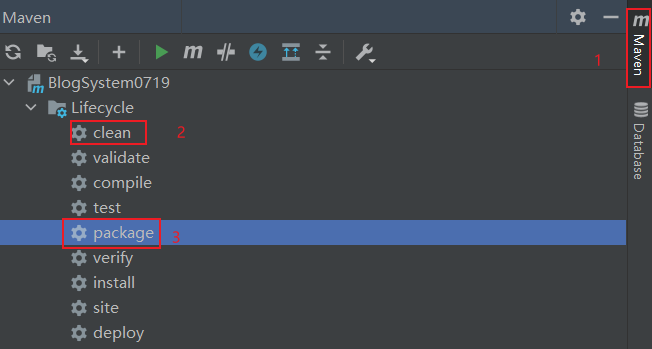
打包成功后,jar包就存在target包里。