在线定制网站官网金融理财网站建设方案
一、注册百度AI开放平台
使用百度AI服务的步骤为:
- 注册:注册成为百度AI开放平台开发者;
- 创建AI应用:在百度API开放平台上创建相关类型的的AI应用,获得AppID、API Key和Secret Key;
- 调用API:调用相关类型的API,获得AI功能的结果,为开发者的应用服务。
注册的操作步骤:
- 登录百度AI开放平台,百度AI开放平台-全球领先的人工智能服务平台,进入百度大脑│AI开放平台首页,如图所示。
 鼠标点击页面右上角“控制台”,进入登录页面。如果已有百度账号,可以使用账号直接登录;如果没有账号,请点击立即注册,按系统要求输入新用户信息,完成系统注册。
鼠标点击页面右上角“控制台”,进入登录页面。如果已有百度账号,可以使用账号直接登录;如果没有账号,请点击立即注册,按系统要求输入新用户信息,完成系统注册。 - 使用用户名、密码登录平台,并需要进行系统认证,认证通过就成为百度AI开放平台开发者,可以使用系统服务。
二、创建OCR文字识别应用
1、登录进去之后,点击“控制台”,再点击左上角的“三”,如下图
选择人工智能中的“文字识别”

2、领取免费资源:点击下图所示的“去领取”,选择“通用场景OCR”,接口名称勾选“全部”,然后点击左下角的“0元领取”按钮即可完成领取免费资源。

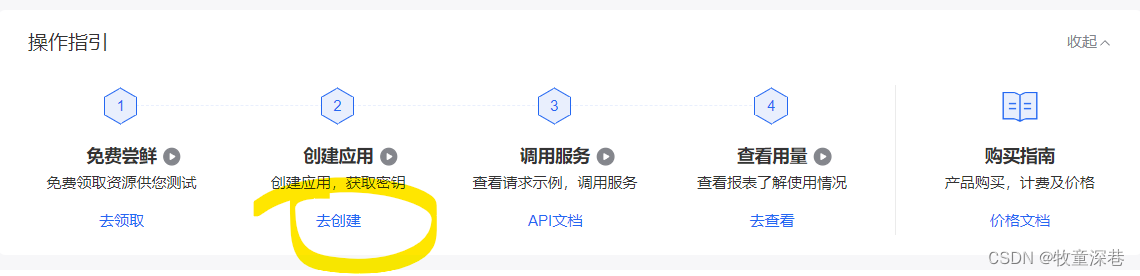
3、点击创建应用下的“去创建”链接,进入页面,必须填写上应用名称以及应用描述,然后单击左下角的“立即创建”。创建成功后点击“应用列表”,即可在应用列表页面看到AppID、API Key、Secret Key的信息,将上述3项百度授权信息复制记录下来,创建“文字识别”的Python应用程序需使用。
三、OCR应用程序实现
1、安装baidu-aip模块:在windows的命令提示符输入pip install baidu-aip,安装百度智能第三方库模块,安装完成后Python的环境配置就设置好了
2、调用应用对图形文件进行识别
from aip import AipOcr #调用百度智能模块中文字识别类方法
#填写个人的 baiinu-ocr aip
APP_ID = '————————'API_KEY = '——————————————————————'SECRET_KEY = '————————————————————————'client = AipOcr(APP_ID,API_KEY,SECRET_KEY)
fp = open(r'——————————.png','rb') #打开所需文字识别的文件
img = fp.read()
message = client.general(img) #调用general方法返回的信息是字典类型的,结果保存在键‘words_result’的值中for i in message['words_result']:print(i['words'])fp.close()注意:我是在windows Python 的IDLE环境下运行的