厦门城乡住房建设厅网站首页wordpress主题如何更换
从功能上描述计算机网络结构
分层结构
每层遵循某个网络协议完成本层功能
基本概念
实体:表示任何可发送或接收信息的硬件或软件进程。
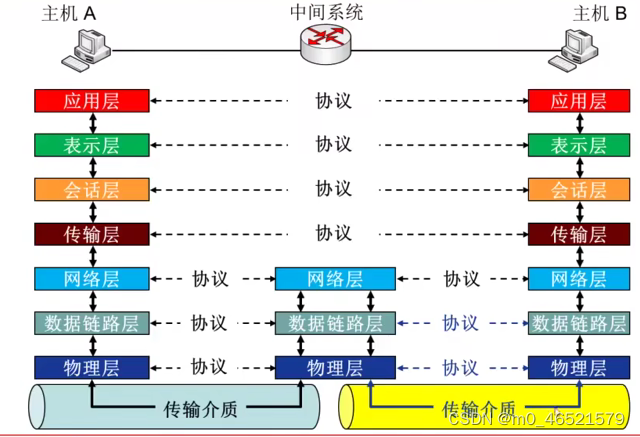
协议是控制两个对等实体进行通信的规则的集合,协议是水平的。
任一层实体需要使用下层服务,遵循本层协议,实现本层功能,向上层提供服务,服务是垂直的。
下一层协议的实现对上层的服务用户是透明的
同系统的相邻层实体间通过接口进行交互,通过服务访问点SAP,交换原语,指定请求的特定服务。

2. OSI参考模型
开放系统互连(OSI)参考模型是由国际标准化组织(ISO)于1984年提出的分层网络体系结构模型。
目的是支持异构网络系统的互联互通。

物理层、数据链路层、网络层、传输层、会话层、表示层、应用层