电子商务网站的规划与建设论文网站分哪几种
鸡鸭羊牛鱼养殖用户不少,其规模也有大有小,尤其对一些生态养殖企业,其产品需求度更高,同时他们也有实际的销售需求。
由于具备较为稳定的货源,因此大规模多规格销售属性很足。
通过【雨科】平台搭建农场养殖商城,助力商家线上多平台卖货及客户随时购买,电脑手机端+小程序端打造品牌官网及农货销售平台,商品多规格上架,订单/经营数据直观查看管理,多种营销功能实现获客拉新、品牌传播、促进消费复购等。
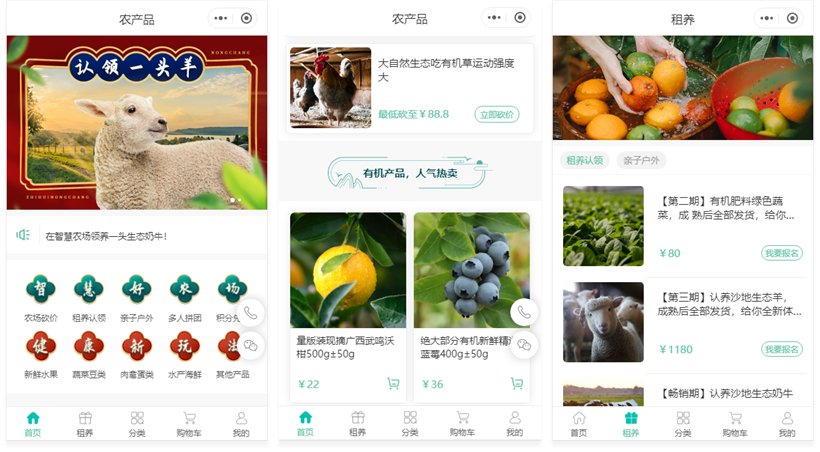
完善的会员系统帮助商家客户管理,分销系统提升生意营收,支持商家直营模式和多商户进驻模式,完善的配送方式及商城经营工具,降低商家经营难度。
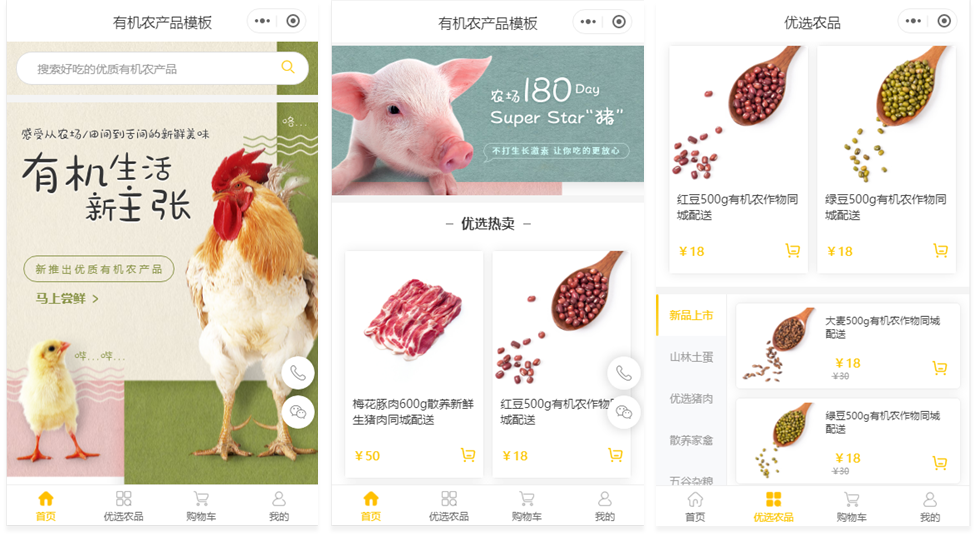
多款商城模板替换修改设计内容即可快速上线使用,无技术要求,多种互动功能,让您快速搭建属于自己的农场农货小程序商城线上经营。
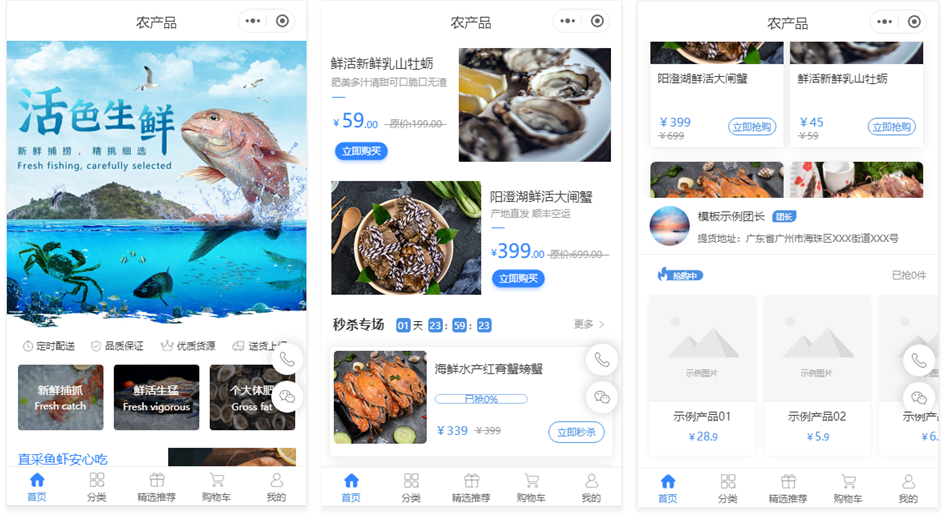
现在就通过【雨科】平台搭建农场农货经营平台吧。
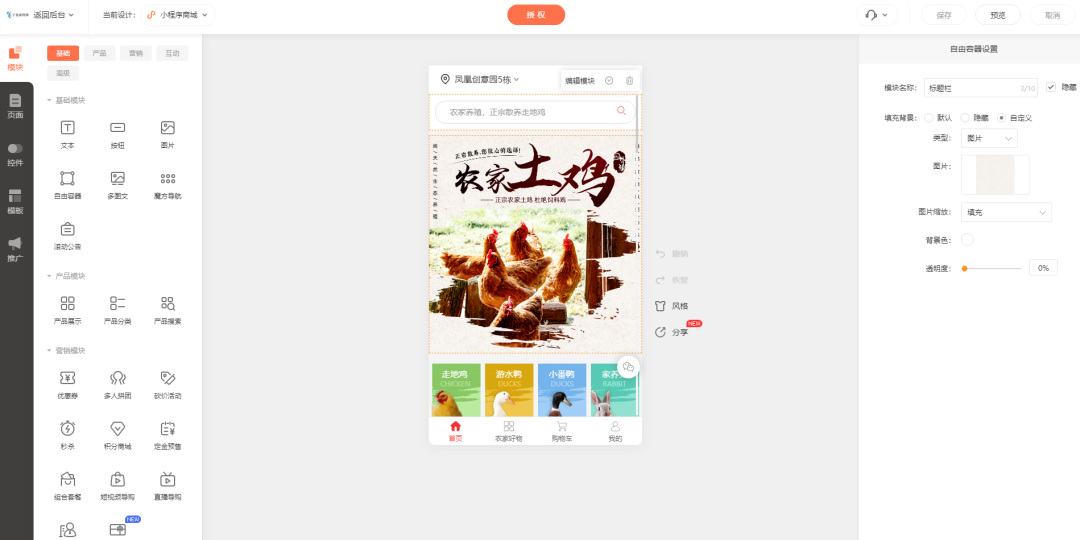
↓↓↓点击官网直达↓↓↓