晋中网站开发不用购买域名做网站
【LetMeFly】1465.切割后面积最大的蛋糕:纵横分别处理
力扣题目链接:https://leetcode.cn/problems/maximum-area-of-a-piece-of-cake-after-horizontal-and-vertical-cuts/
矩形蛋糕的高度为 h 且宽度为 w,给你两个整数数组 horizontalCuts 和 verticalCuts,其中:
-
horizontalCuts[i]是从矩形蛋糕顶部到第i个水平切口的距离 verticalCuts[j]是从矩形蛋糕的左侧到第j个竖直切口的距离
请你按数组 horizontalCuts 和 verticalCuts 中提供的水平和竖直位置切割后,请你找出 面积最大 的那份蛋糕,并返回其 面积 。由于答案可能是一个很大的数字,因此需要将结果 对 109 + 7 取余 后返回。
示例 1:
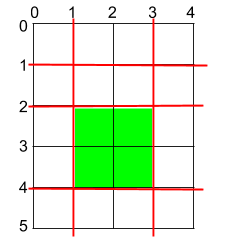
输入:h = 5, w = 4, horizontalCuts = [1,2,4], verticalCuts = [1,3] 输出:4 解释:上图所示的矩阵蛋糕中,红色线表示水平和竖直方向上的切口。切割蛋糕后,绿色的那份蛋糕面积最大。
示例 2:
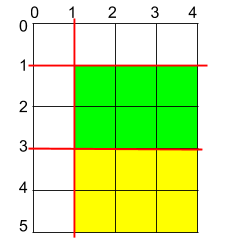
输入:h = 5, w = 4, horizontalCuts = [3,1], verticalCuts = [1] 输出:6 解释:上图所示的矩阵蛋糕中,红色线表示水平和竖直方向上的切口。切割蛋糕后,绿色和黄色的两份蛋糕面积最大。
示例 3:
输入:h = 5, w = 4, horizontalCuts = [3], verticalCuts = [3] 输出:9
提示:
2 <= h, w <= 1091 <= horizontalCuts.length <= min(h - 1, 105)1 <= verticalCuts.length <= min(w - 1, 105)1 <= horizontalCuts[i] < h1 <= verticalCuts[i] < w- 题目数据保证
horizontalCuts中的所有元素各不相同 - 题目数据保证
verticalCuts中的所有元素各不相同
方法一:纵横分别处理
横向的一刀和纵向的一刀之间是互不干扰的。因此,我们只需要求出“横向上的最大间隔”和“纵向上的最大间隔”,然后相乘即可。
对于单个方向:我们只需要求出“相邻两刀”的最大间隔,以及第一刀和最后一刀距离边界的值的最大值即可。
- 时间复杂度 O ( n log n + m log m ) O(n\log n + m\log m) O(nlogn+mlogm)
- 空间复杂度 O ( log n + log m ) O(\log n + \log m) O(logn+logm)
AC代码
C++
class Solution {
private:long long getMax(int l, vector<int>& v) {sort(v.begin(), v.end());int ans= 0;for (int i = 1; i < v.size(); i++) {ans = max(ans, v[i] - v[i - 1]);}return max(ans, max(v[0], l - v[v.size() - 1]));}public:int maxArea(int h, int w, vector<int>& horizontalCuts, vector<int>& verticalCuts) {return getMax(h, horizontalCuts) * getMax(w, verticalCuts) % 1000000007;}
};
Python
# from typing import Listclass Solution:def getMax(self, l: int, v: List[int]) -> int:v.sort()ans = v[0]for i in range(1, len(v)):ans = max(ans, v[i] - v[i - 1])return max(ans, l - v[-1])def maxArea(self, h: int, w: int, horizontalCuts: List[int], verticalCuts: List[int]) -> int:return self.getMax(h, horizontalCuts) * self.getMax(w, verticalCuts) % 1000000007
同步发文于CSDN,原创不易,转载经作者同意后请附上原文链接哦~
Tisfy:https://letmefly.blog.csdn.net/article/details/134073948