个人可以做网站中国充电网络公司排名
文章目录
- 简述PicGo
- 下载PicGo
- 获取Token
- 配置PicGo
- 结合Typora
- 总结
简述PicGo
PicGo: 一个用于快速上传图片并获取图片 URL 链接的工具
PicGo 本体支持如下图床:
七牛图床v1.0腾讯云 COS v4\v5 版本v1.1 & v1.5.0又拍云v1.2.0GitHubv1.5.0SM.MS V2v2.3.0-beta.0阿里云 OSSv1.6.0Imgurv1.6.0
特色功能
- 支持拖拽图片上传
- 支持快捷键上传剪贴板里第一张图片
- Windows 和 macOS 支持右键图片文件通过菜单上传 (v2.1.0+)
- 上传图片后自动复制链接到剪贴板
- 支持自定义复制到剪贴板的链接格式
- 支持修改快捷键,默认快速上传快捷键:
command+shift+p(macOS)|control+shift+p(Windows\Linux) - 支持插件系统,已有插件支持 Gitee、青云等第三方图床
- 更多第三方插件以及使用了 PicGo 底层的应用可以在 Awesome-PicGo 找到。欢迎贡献!
- 支持通过发送 HTTP 请求调用 PicGo 上传(v2.2.0+)
从我个人的使用体验上看,可以大幅度提高写作生产力,提升写作效率,作者强烈建议自己做一个免费图床。
下载PicGo
进入官网:https://github.com/Molunerfinn/PicGo/releases/tag/v2.3.1,我下载的是最新的稳定版,当然看自己个人需要也可以在官网找beta版下载。
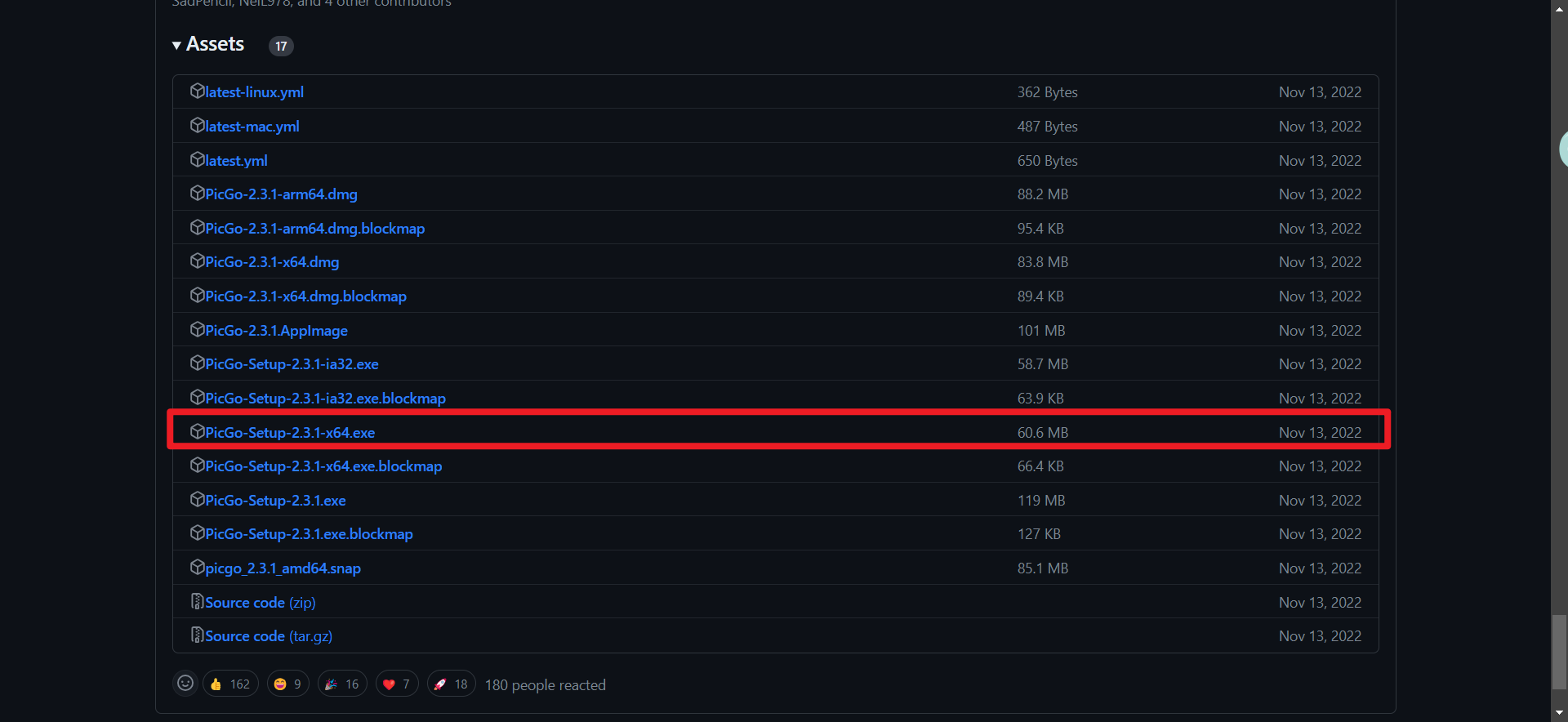
打开下载的exe文件,按下列步骤进行操作。
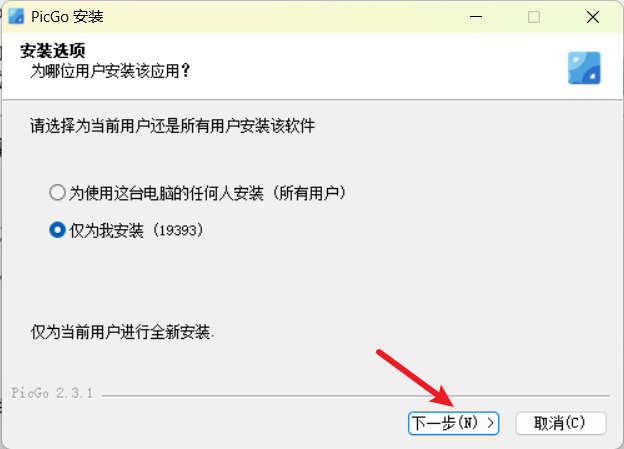
安装路径可自选。
获取Token
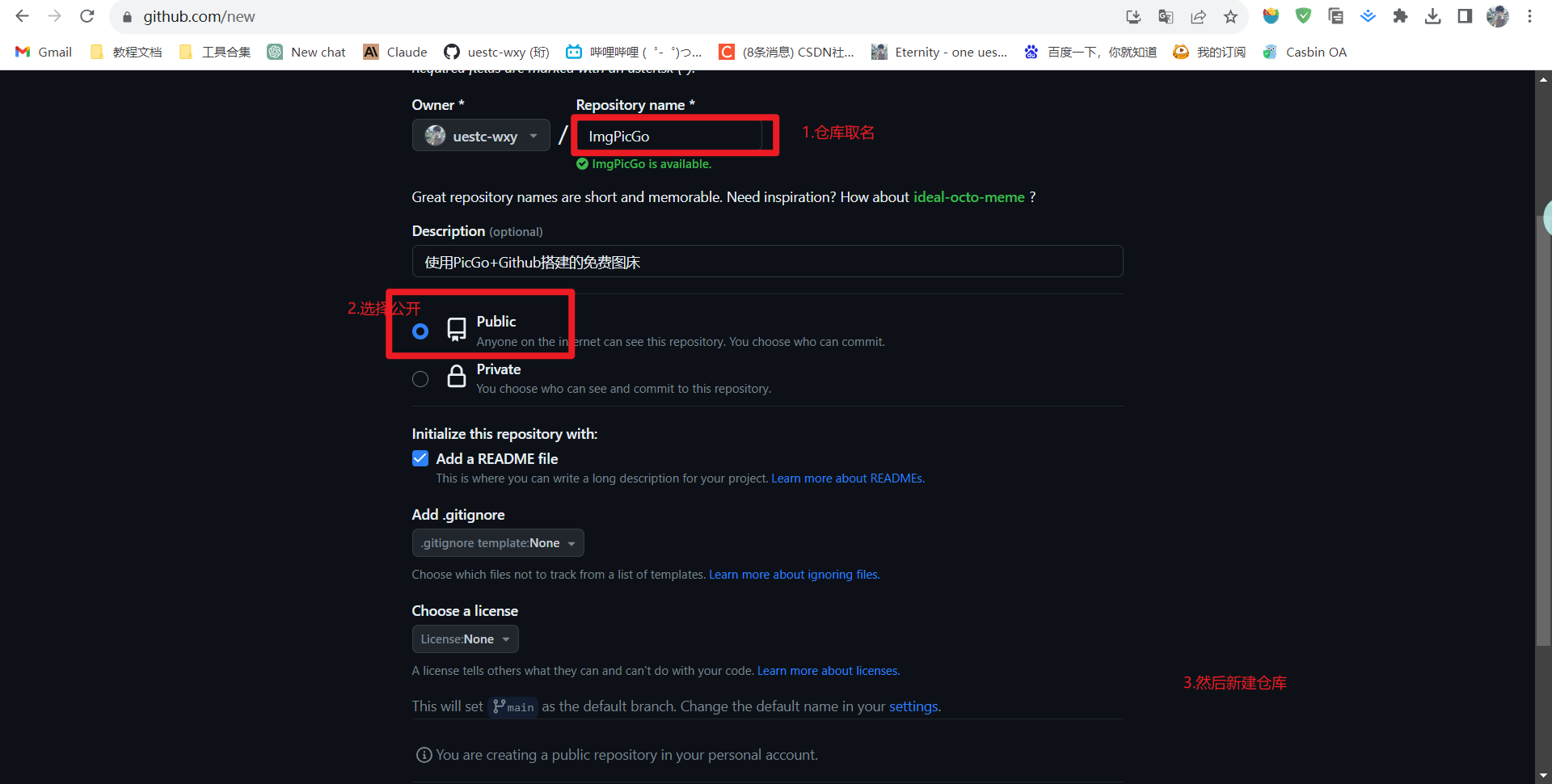
新建一个Github仓库。仓库一定要公开。
右上角点击自己的头像。
点击右下方的settings。
再点击左下方的Developer settings。
按图示进行操作。
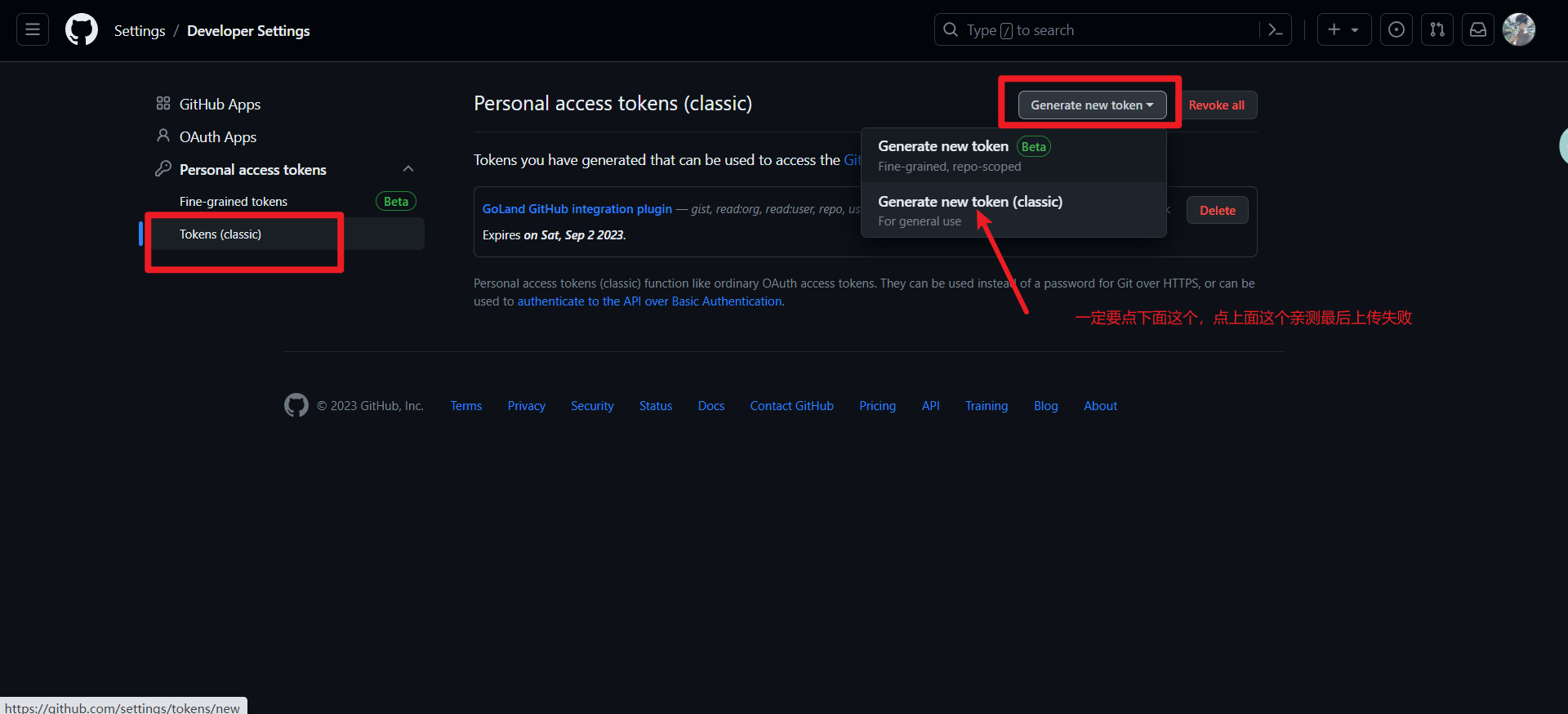
编辑新生成的Token信息。
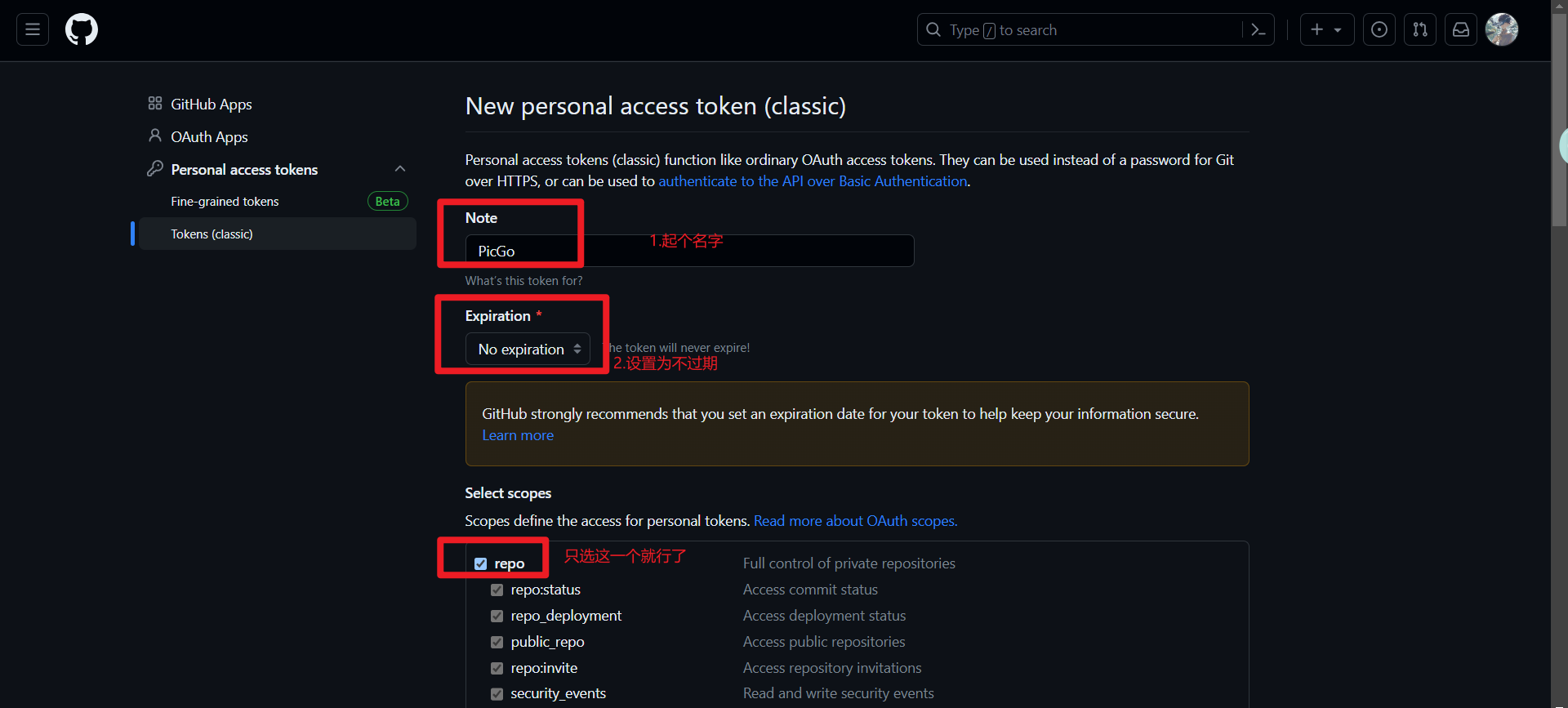
最后点击Generate token。
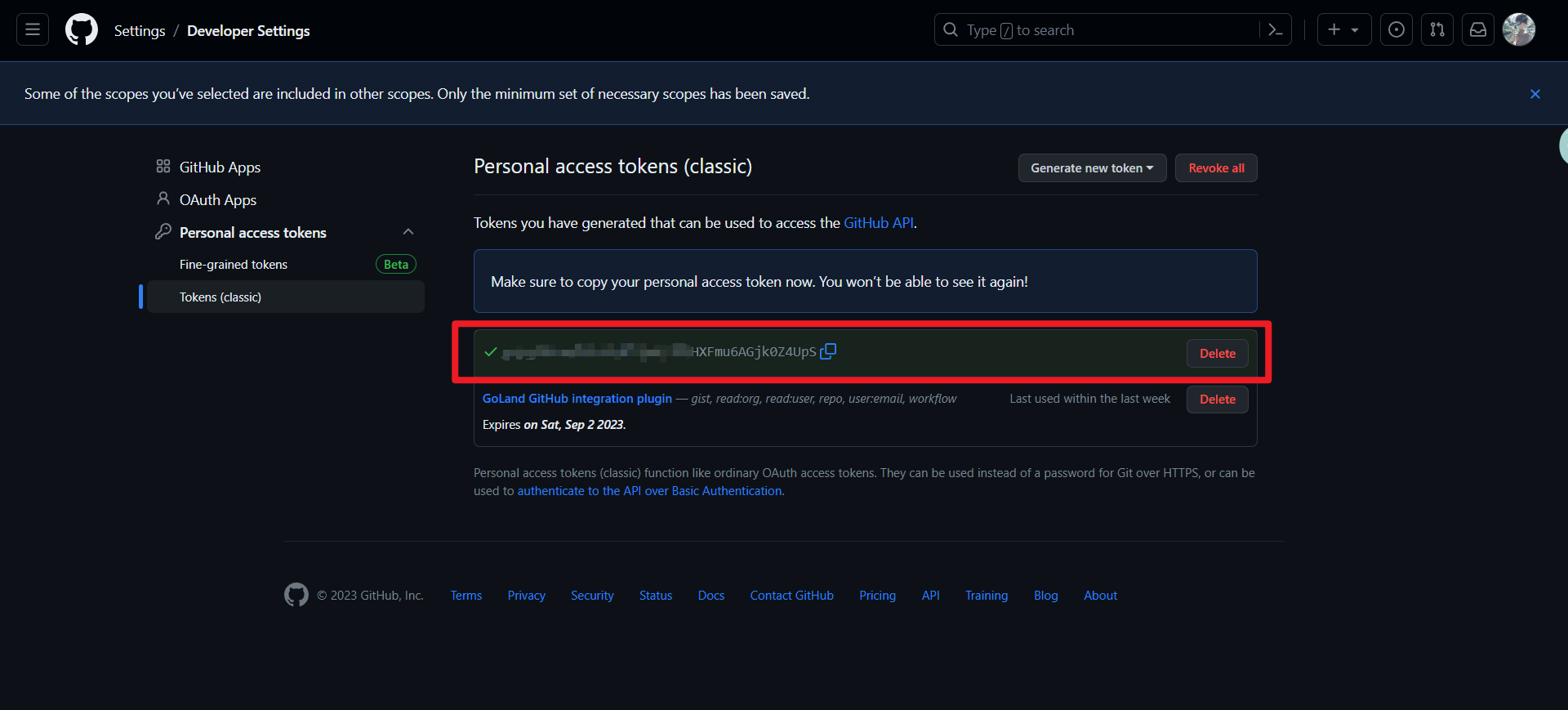
复制生成的Token,一定要保存好,可以放到备忘录里面,这玩意儿只能看一次。
配置PicGo
打开PicGo软件。

点击图床设置,再点击Github。

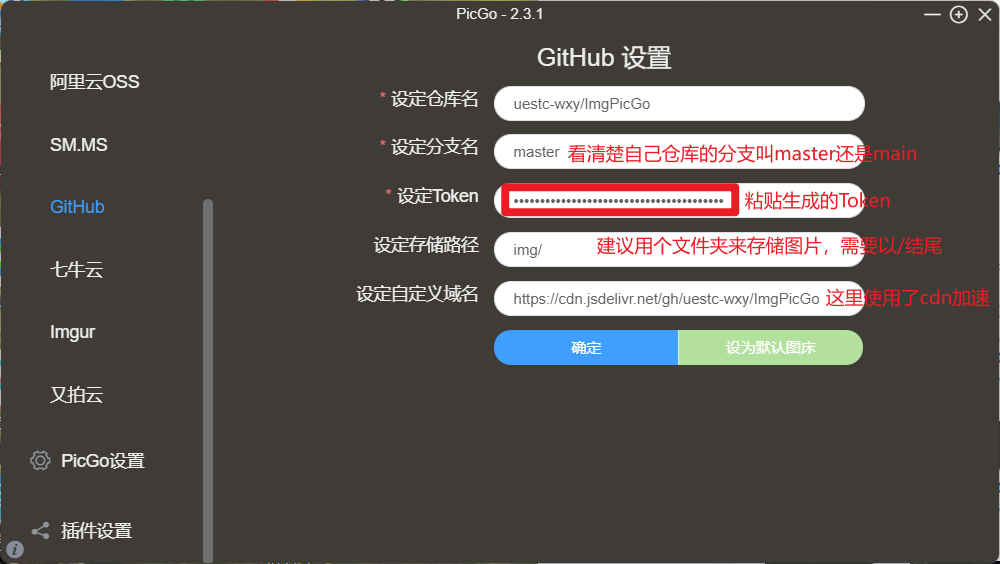
可以按下列操作在Github上新建文件夹。
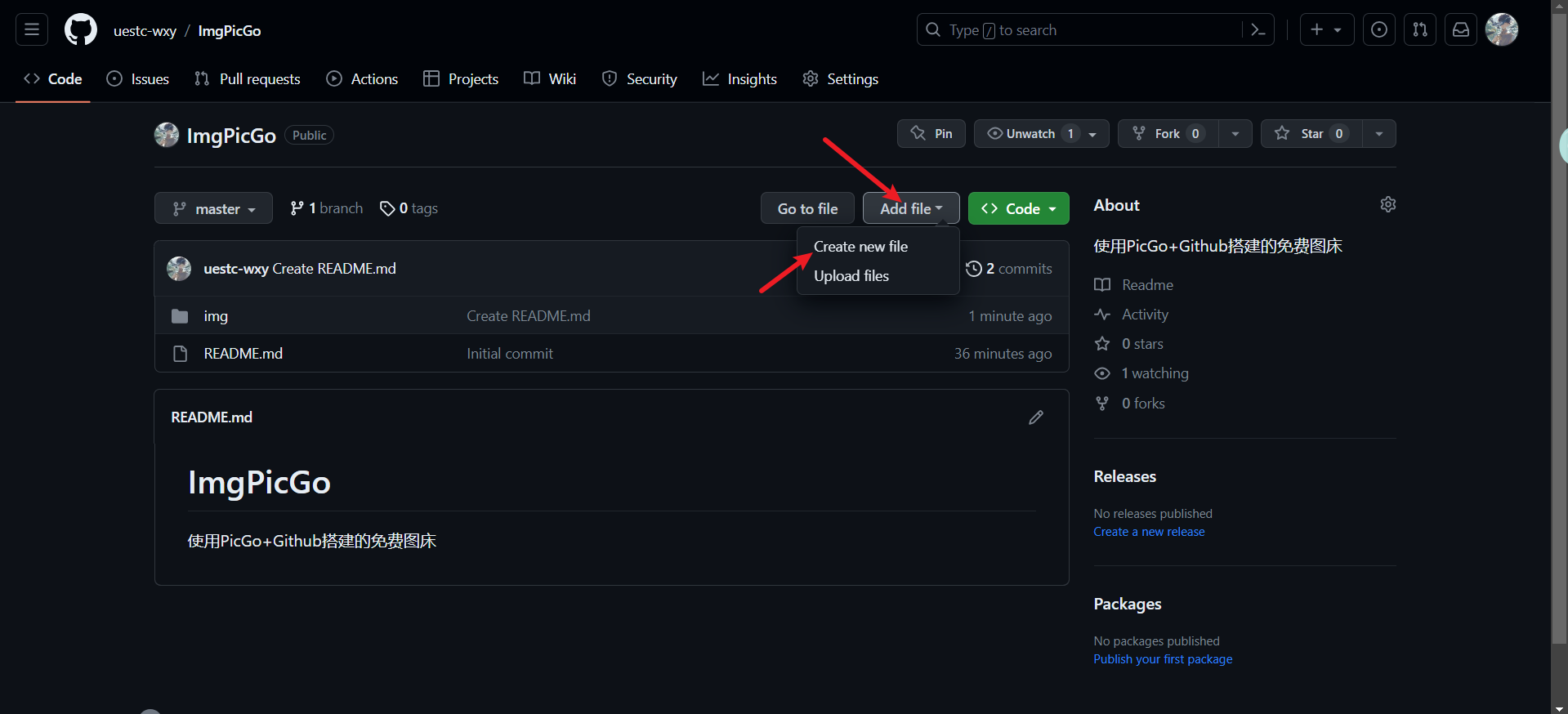
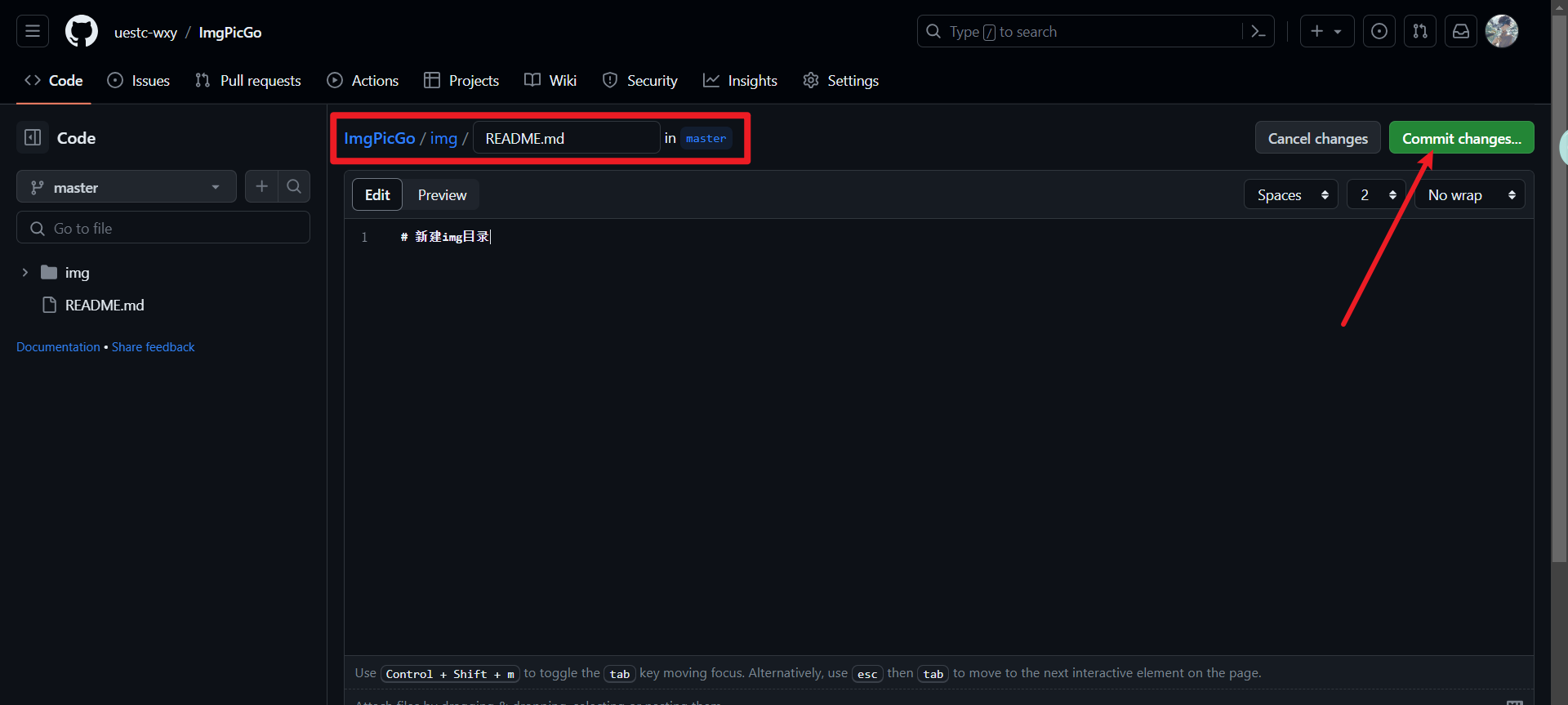
一定要输入文件夹名/文件名,因为Github不允许空文件夹存在,所以必须这样操作,比如img/README.md。
然后点击工作区,上传方式选择Github。
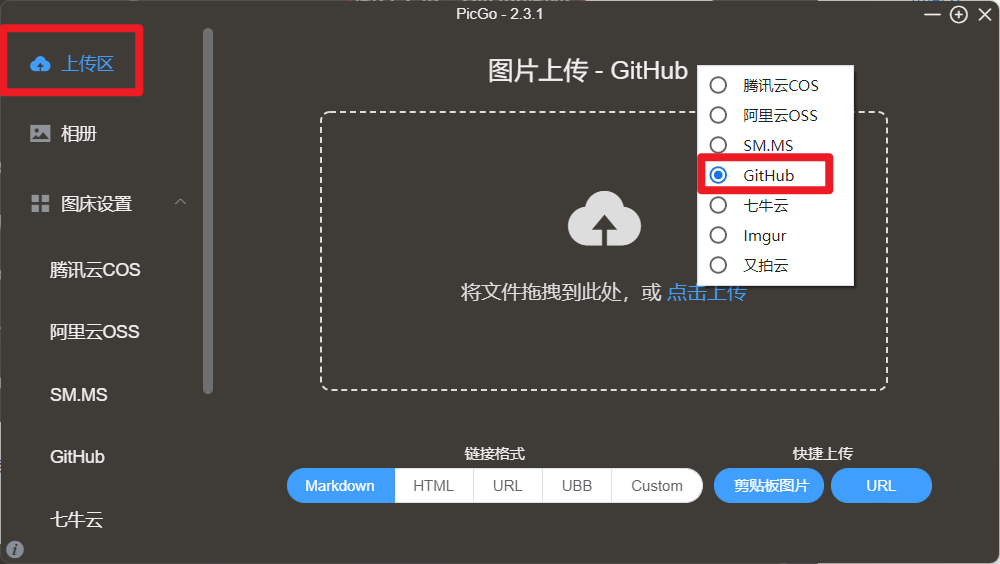
拖拽图片到上传区检验是否配置成功。
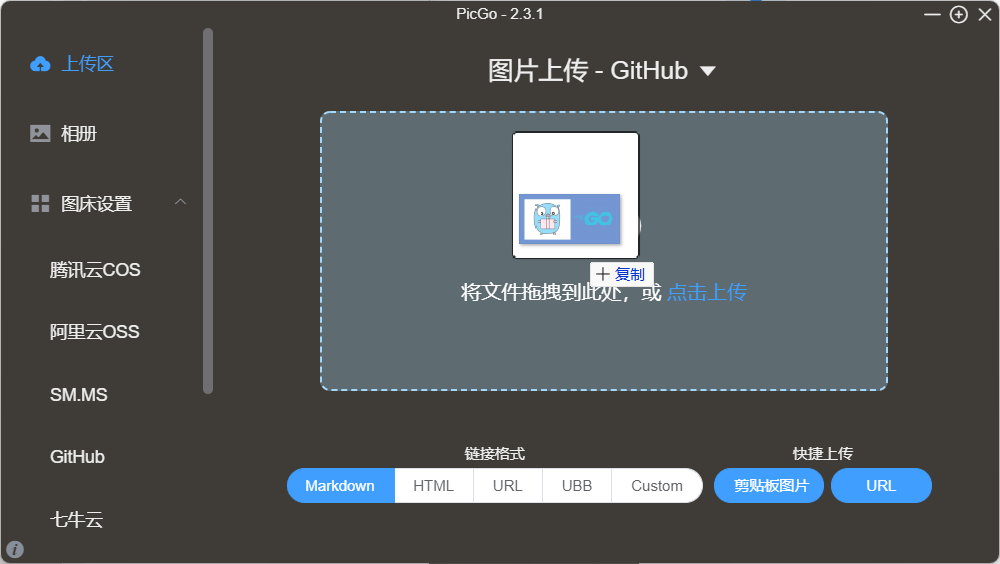
可以看到相册和剪贴板都有上传的图片路径,PicGo配置成功。

结合Typora
在Typora中点击偏好设置。按下列图示进行操作。
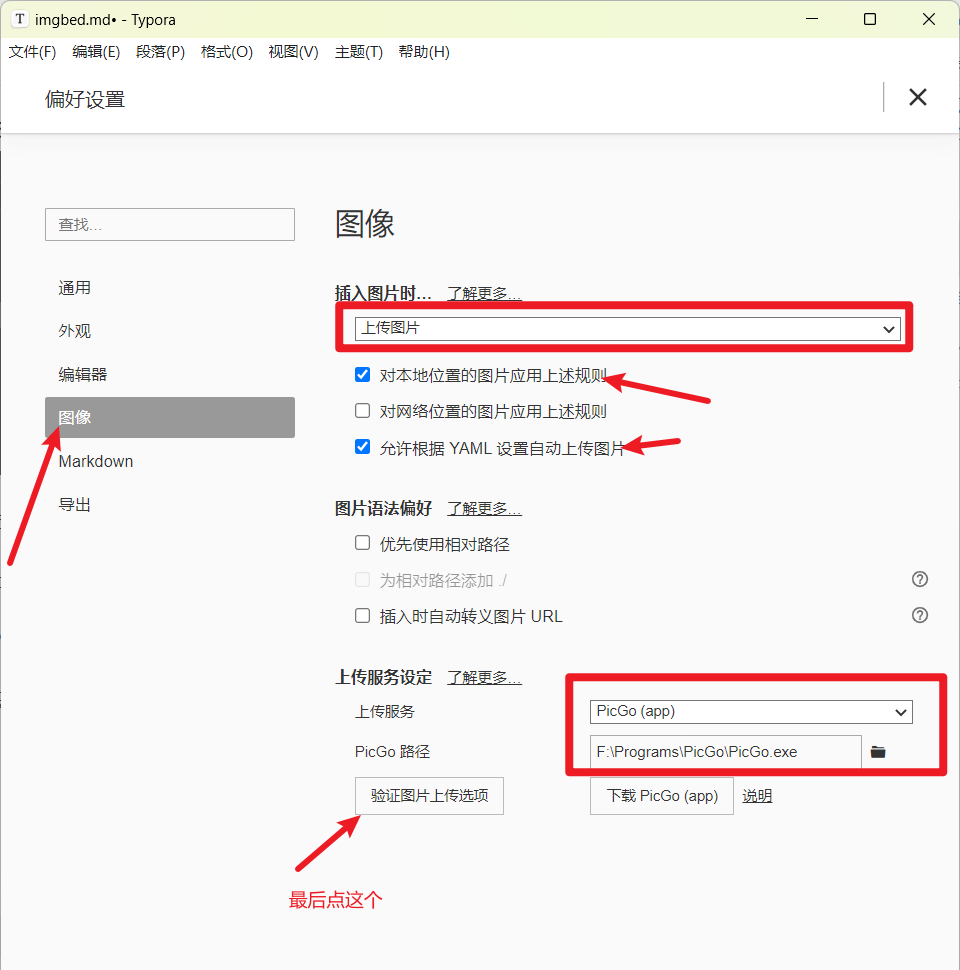
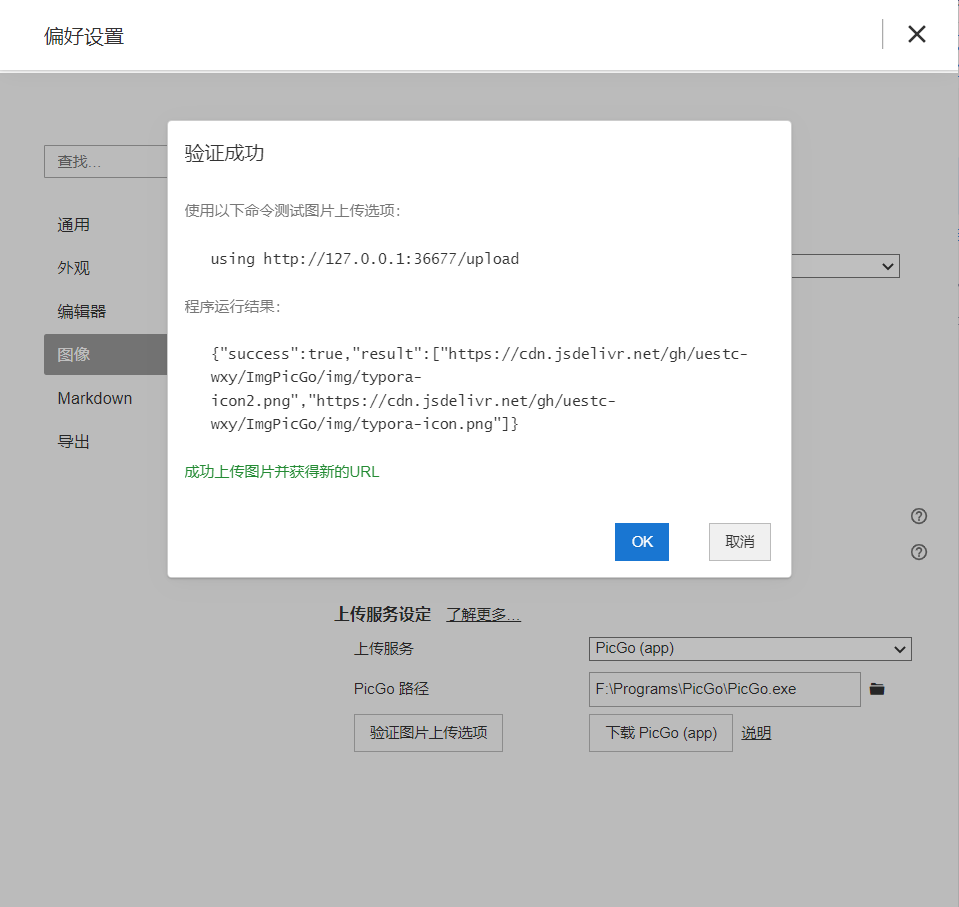
出现以下内容代表示在Typora上配置PicGo成功。
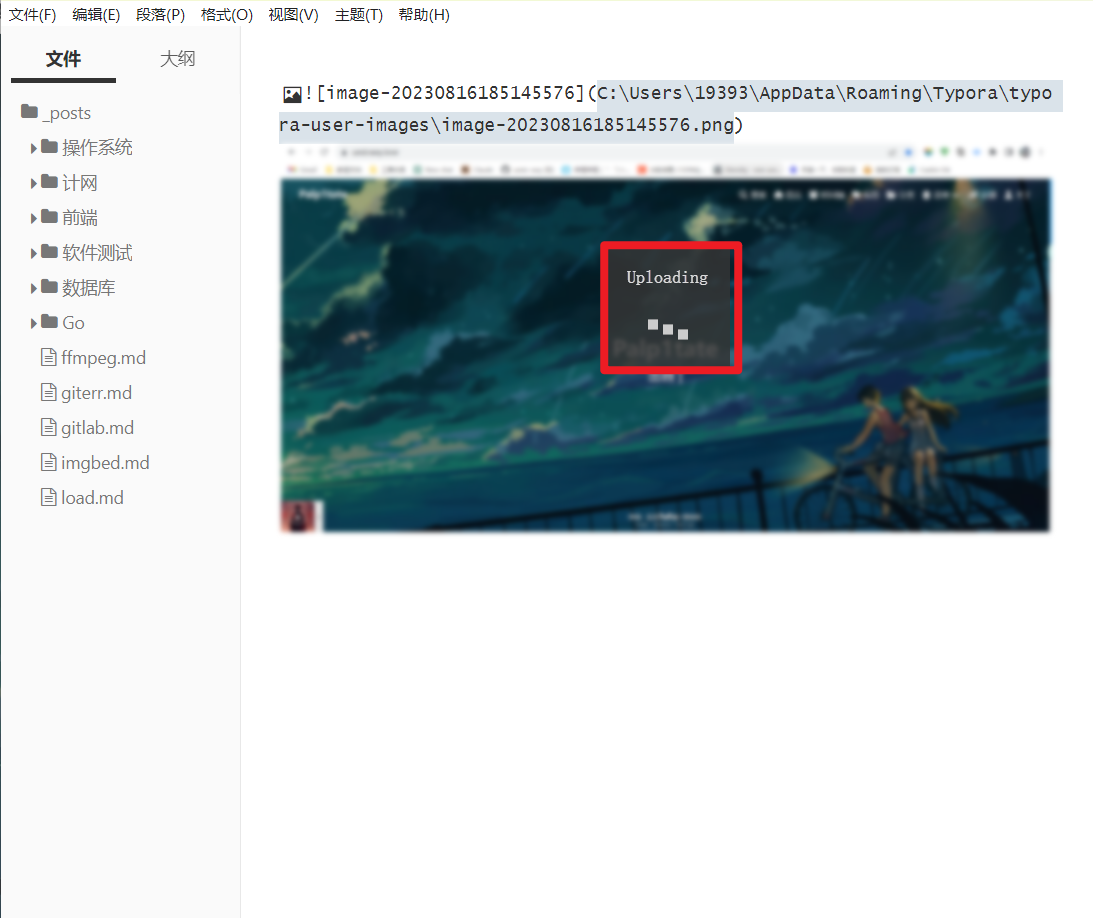
我们随便从剪贴板复制一张图片粘贴到Typora中,可以发现该图片会自动上传到Github中。
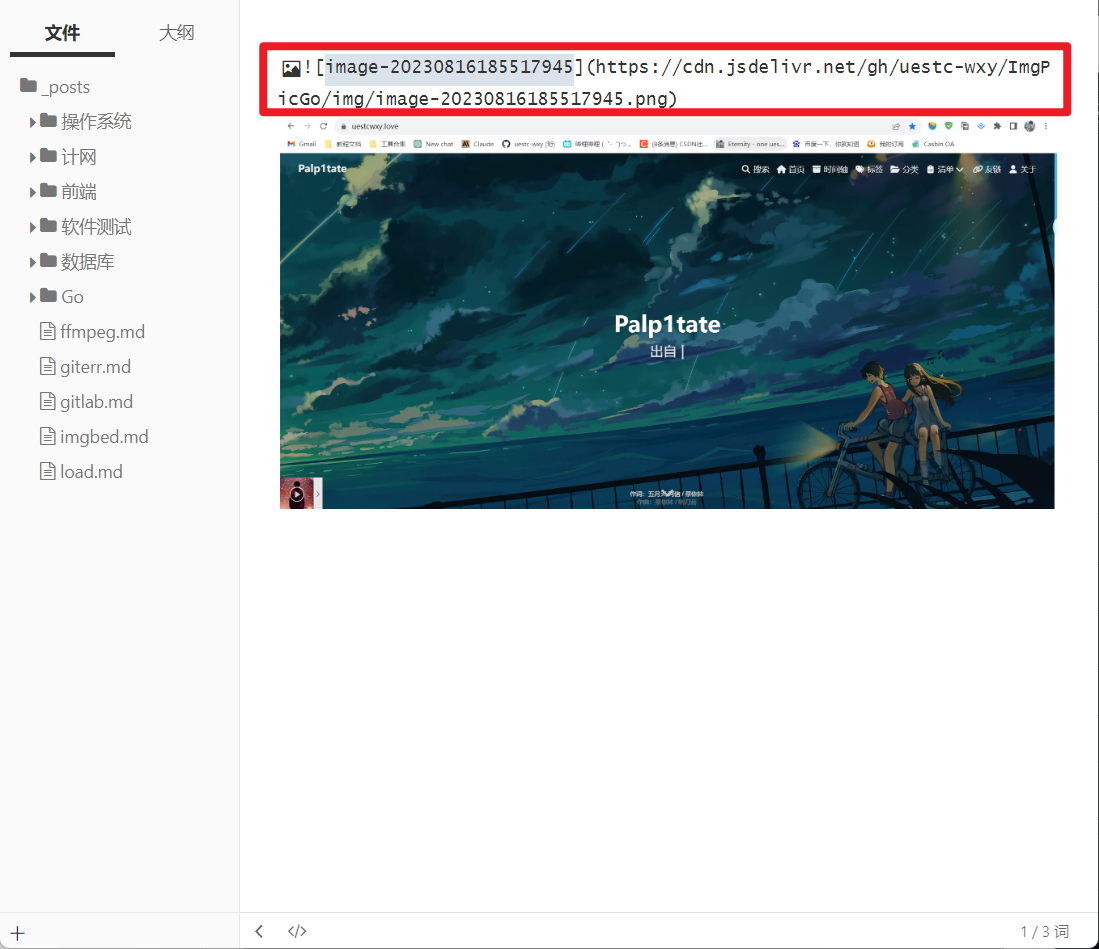
并且路径会自动变为自己设置的域名加图片在Github中仓库的路径。
不得不说,这样极大地提高了我的写作速率,很方便快捷。
ps:原本github中某张图片的路径应该是形如下面的样子:
https://github.com/uestc-wxy/ImgPicGo/blob/master/img/image-20230816184801636.png但是使用这种方式访问图片巨慢,所以我使用了jsdelivr作为cdn加速。新的URL形如
https://cdn.jsdelivr.net/gh/uestc-wxy/ImgPicGo/img/image-20230816184801636.png。gh代表GitHub,后面跟的是Github用户名和仓库名,再是图片在Github中的路径。
总结
个人觉得PicGo加Typora简直就是写作的神器,能够很大程度的提高写作效率,简单来说就是一截图一粘贴一张图片就被唯一确定了,我直呼nice。