哪种网站名称容易通过备案审核电子商务网站建设案例教程
一、容器的概念
容器是由一个或多个与系统其余部分隔离的进程组成的集合。我们可以理解为“集装箱”。
集装箱是打包和装运货物的标准方式。它作为一个箱子进行标记、装载、卸载,以及从一个
位置运输到另一个位置。该容器的内容与其他容器的内容隔离,因此互不影响。
容器的目的:为进程集合提供一个独立的运行环境
而容器是怎么实现的呢:
1.文件系统隔离
(每个容器都具有独立的文件系统,单个容器内对文件系统进行增删改查不会影响到其他容
器)
2.资源隔离
利用 namespace 隔离进程之间的相互可见及通信
使用 Cgroup 限制资源使用率,设置其能够使用的 CPU 以及内存量的大小
加强安全边界的 SElinux 和 seccomp(安全计算模式)
cgroup:用于资源管理控制组
namespace 命名空间
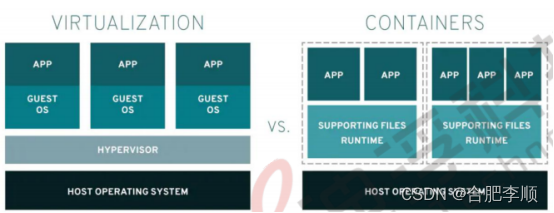
容器与虚拟机在硬件和底层操作系统交互有所不同:
虚拟机:
1. 使多个操作系统能够同时在一个硬件平台上运行。
2. 使用虚拟机监控程序将硬件分为多个虚拟硬件系统,从而允许多个操作系统并行运 行。
3. 需要一个完整的操作系统环境来支持该应用。
容器:
1. 直接在操作系统上运行,从而跨系统上的所有容器共享硬件和操作系统资源。这使
得应用能够保持轻巧,并快速并行运行。
2. 共享相同的操作系统内核,将容器化应用进程与系统的其余进程隔离开,并使用与
该内核兼容的软件。
3. 需要的硬件资源比虚拟机少得多,这也使其能够快速启动和停止并降低存储要求
而相比容器通常提供的对硬件的访问,访问底屋硬件信息的应用可能需要更直接地访问硬
件,这就不合适作为容器运行
docker 与 podman:
docker:开源的应用容器引擎,所欲一种 Linux 容器封装,提供了易用的容器使用接口,
可以让开发这打包应用及依赖包到一个可移植的容器中,在发布到任何流行的机器上,网桥
使用沙箱机制,相互不会有任何接口
缺点:
Docker 需要在你的系统上运行一个守护进程。
Docker 是以 root 身份在你的系统上运行该守护程序。
podman:开源容器管理工具,是一种无守护程序的容器引擎,是用于在 Linux 系统上开发, 管理和运行任何符合 Open Container Initiative(OCI)标准的容器和容器镜像,提供了一个 与 Docker 兼容的命令行前端,该前端可以简单地为 Docker CLI 别名,即“ alias docker = podman”。
Podman 控制下的容器既可以由 root 用户运行,也可以由非特权用户运行,这个是 Podman
与 Docker 最大的差别之一。
不同之处:
1.docker 需要在我们的系统上运行一个守护进程(docker daemon),而 podman 不需要;
2.启动容器的方式不同:
docker cli 命令通过 API 跟 Docker Engine(引擎)交互告诉它我想创建一个container,然后 docker Engine 才会调用 OCI container runtime(runc)来启动一个 container。这代表 container 的 process(进程)不会是 Docker CLI 的 child;
process(子进程),而是 Docker Engine 的 child process。Podman 是直接给 OCI containner runtime(runc)进行交互来创建 container 的,所以 container process 直接是 podman 的 child process。
3.因为 docke 有 docker daemon,所以 docker 启动的容器支持--restart 策略,但是 podman 不支持,如果在 k8s 中就不存在这个问题,我们可以设置 pod 的重启策略,在 系统中我们可以采用编写 systemd 服务来完成自启动4.docker 需要使用 root 用户来创建容器,但是 podman 不需要。
在 redhat 中提供了一组用于管理容器操作的容器工具:
podman: 直接管理容器和容器镜像
skopeo:用于检查,复制,删除和部署镜像
buildah:用于创捷新的容器镜像
容器镜像:将容器运行时所需要的所有文件的集合
在容器主机上,您可以 root 用户或普通非特权用户身份运行容器。
由非特权用户运行的容器称为 rootless 容器。
Rootless 容器更安全,但存在一些限制。
例如, rootless 容器无法通过容器主机的特权端口(低于 1024 的端口)发布其网络服务。
如有必要,您可以 root 用户身份直接运行容器,但如果漏洞允许攻击者破坏容器,这样做会
在一定程度上削弱系统的安全性。
运行一个容器
安装容器管理工具:yum module install container-tools -y
选择容器镜像和注册表的概念
容器注册表是用于存储和检索容器镜像的存储库。
开发人员将容器镜像上传或推送到容器注册表中。
从注册表中将这些容器镜像下载或提取到本地系统,可用于运行容器。
也可以使用第三方镜像的公共注册表,也可使用贵组织控制的私有注册表
红帽通过两个主容器注册表分发认证容器镜像:
registry. redhat.io:适用于基于官方红帽产品的容器。
registry.connect.redhat.com:适用于基于第三方产品的容器
registry.access.redhat.com:旧的注册表
容器命名规则
语法:registry_name/user_name/image_name:tag
registry_name 是存储镜像的注册表的名称,通常是注册表的完全限定域名。
user_name 表示镜像所属的用户和组织
image_name 在用户命名空间必须唯一
tag 标识镜像版本。
举例操作:
①[root@localhost ~]# yum module install container-tools -y #安装 container-tools 模块
②[root@localhost ~]# podman login registry.connect.redhat.com #使用登录容器注册表
Username:
但我们没有账号,暂时不登录
③[root@localhost ~]# podman search rhel7 #搜索镜像
![]()
搜索后跟参数:
--no-trunc 表示查看命令描述(全部)
--filter=stars=600 显示点赞数>=600 的
=is-automated=<true|false>显示自动构建的镜像
=is-official=<true|false>仅显示标记为官方的镜像
--limit 限制每个注册表列出的镜像数量
--tls-verify <true|false> 为所有使用的注册表启用和禁用 HTTPS 证书验证。默认
启动(true)
④[root@localhost ~]# podman pull registry.access.redhat.com/rhel7.0:latest #提取镜像
⑤[root@localhost ~]# podman images #列出存储在本地的镜像
⑥[root@localhost ~]# podman run -it --name=rhel7 registry.access.redhat.com/rhel7.0:latest /bin/bash #运行 rhel7 容器
参数理解:
-t == --tty 意思是 pseudo-tty(伪终端)将被分给容器
-i == --interactive 相同。容器接受输入
-d == --detach,表示容器在后台运行(已分离)
--name 设置容器名称。容器名称必须唯一。
如果 podman run 命令不包含容器名称, Podman 将生成唯一的随机名称。
/bin/bash 允许交互
⑦查看正在运行的容器
(
podman ps -a 查看正在运行+历史运行过的容器
podman ps -q 查看正在运行的容器 id
podman ps -s 显示运行容器总文件大小
podman ps -l 显示最近创捷容器
podman ps -n 3 最近创键的 3 个容器
podman ps --no-trunc 显示所有描述
)
[root@localhost ~]# podman ps
[root@localhost ~]# podman run -it registry.access.redhat.com/rhel7.0:latest #我们也可以快速命令,无需交互,使用完后删除容器
[root@example ~]# podman ps
⑧构建一个容器存放在后台
[root@localhost ~]# podman run -itd registry.access.redhat.com/rhel7.0:latest /bin/bash
[root@localhost ~]# podman ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
6479495ccbd5 registry.access.redhat.com/rhel7.0:latest /bin/bash 10
seconds ago Up 9 seconds ago compassionate_northcutt
⑨进入后台容器
[root@localhost ~]# podman attach compassionate_northcutt
[root@6479495ccbd5 /]#
缺点:容器终止或者容器退出,容器就会重后台退出
[root@localhost ~]# podman exec -it 6479495ccbd5 /bin/bash
推荐可以使用:不会退出后台容器
二、相关概念
1.容器注册表信息
①[root@localhost /]# cat /etc/containers/registries.conf #获取有关使用容器注册表的信息
![]()
$HOME/.config/containers #普通用户容器注册表的信息位置(需要pull镜像后,ssh到普通用户)
②[root@localhost /]# podman info #显示 podman 的配置信息(包括注册表)
2.概念
registries.conf 配置文件说明:
安全性:registries. conf 文件的[registries. insecure]部分中列出了不安全的注册表。 如果注册表被列为不安全,则不会使用 TLS 加密来保护与该注册表的连接。如果注册表既可搜索又不安全则会同时在[registries.search]和[registries.insecure]中列出。可将容器注册表配置为需要身份验证。如前所述,可使用 podman login 命令登录需要身份验证的容器注册表。
3.检查容器镜像
①[root@localhost /]# skopeo inspect docker://registry.access.redhat.com/quarkus/mandrel-20-rhel8
#令检查注册表中的远程容器镜像,无需将镜像提取到本地系统
②[root@localhost ~]# podman images #查看本地存储的镜像信息
4.移除本地容器镜像和容器
①[root@localhost ~]# podman images #查看本地存储的镜像信息
②[root@example ~]# podman rmi registry.access.redhat.com/rhel7.0 #移除本地容器镜像
③[root@example ~]# podman rmi -f registry.access.redhat.com/rhel7.0 #强制移除本地容器镜像
④#删除多个镜像间以空格间隔
⑤删除一个容器:podman rm 名称或 id 删除多个:podman rm -f $(podman ps -a -q)
三、管理容器即服务(重点)
1.相关说明了解
①初级概念:
在将数据库或 Web 服务器等服务部署为容器时,通常希望这些容器在服务器启动时自动启动,所以我们将容器作为 systemd 服务启动和停止,并检查其状态。(systemd 服务取代 了 initd,成为系统的第一个进程(PID 等于 1),其他进程都是它的子进程)
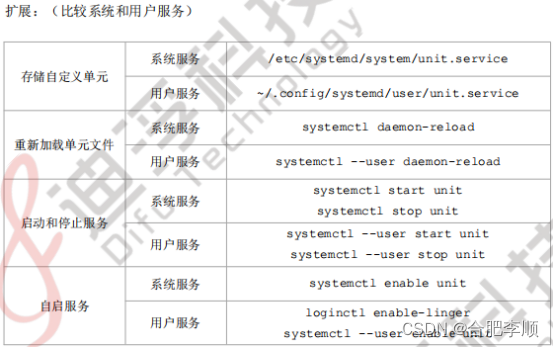
②systemd 管理系统服务:
通过 rootless 容器创捷 systemd 用户单元文件,可以使用 systemctl 来管理。若容器
在 rootless 模式中运行,则可以从非特权用户帐户管理这些服务,以提高安全性。
③systemd 管理用户服务:
借助 systemd 用户服务,用户可以为自己的服务创建单元文件,并使用 systemct1 命令管理这些服务,无需 root 访问权限。
④技术说明:
普通用户原状态情况:当您将用户服务作为非 root 用户启用时, 该服务会在您通过文本或图形控制台或使用 SSH 打开第一个会话时自动启动。当您关闭最后一个会话时,服务停止。此行为与系统服务有所不同,系统服务是在系统启动时启动,在系统关闭时停止;
现在可以实现手段:可以通过 loginct1 enable-linger/disable-linger 来改变启用/禁止用户逗留(相当于保持登录状态)。 若没有指定就是当前用户,如果指定了用户名或 UID, 那么系统将会在启动时自动为这些 用户派生出用户管理器, 并且在用户登出后继续保持运行。
允许未登录的用户在后台运行持续时间很长的服务。
⑤(loginctl — 控制 systemd 登录管理器:
http://www.jinbuguo.com/systemd/loginctl.html)
2.创建和管理 systemd 用户服务说明
①#查看 username 当前各项属性值
loginct1 show-user username
②创建和管理 systemd 用户服务相关说明
定义 systemd 用户服务,在-/.config/systemd/user/目录来下创建服务文件。
使用 systemct1 --user 命令来控制,但必须在控制台登录或直接通过 ssh 登录。sudo
和 su 不起作用。
systemctl 守护进程会与 systemctl --user 进程交互。仅当用户首次从控制台或 ssh
登录时,系统才会启动该进程。
3.podman 生成 systemd 文件有两种方式:
①生成的容器,在开机时服务启动的时候启动容器,关机时停止它。
②每次服务启动的时候创建并运行容器,在停止服务时删除容器.。
[root@example ~]# podman --version #版本
![]()
podman version 1.6.4 #1.6.4 版本不支持--new 参数
4.案例:
创捷 systemd 单元文件
1)创建用户 contsvc
[root@localhost /]# useradd contsvc
[root@localhost /]# passwd contsvc
2)登录 contsvc 用户,搜索 httpd 镜像
[root@localhost /]# ssh contsvc@127.0.0.1
[contsvc@localhost ~]$ podman search httpd
3)创建 webcontent/html 网页文件
[contsvc@localhost ~]$ mkdir -p ~/webcontent/html
[contsvc@localhost ~]$ echo "hello world" > webcontent/html/index.html
4)确定权限
[contsvc@localhost ~]$ ls -ld webcontent/html/
[contsvc@localhost ~]$ ls -l webcontent/html/index.html
5)拉取 httpd 到公共镜像
[contsvc@localhost ~]$ podman pull
registry.access.redhat.com/rhscl/httpd-24-rhel7:latest
6)创建容器
[contsvc@localhost ~]$ podman run -itd --name myweb -p 8080:8080 -v
~/webcontent:/var/www:Z
registry.access.redhat.com/rhscl/httpd-24-rhel7:latest
7)验证
[contsvc@localhost ~]$ curl http://127.0.0.1:8080
hello world
8)创建目录
[contsvc@localhost ~]$ mkdir -p .config/systemd/user
9)创建 systemd 单元文件
[contsvc@localhost ~]$ cd .config/systemd/user/
[contsvc@localhost user]$ podman generate systemd --name myweb --files --new /home/contsvc/.config/systemd/user/container-myweb.service
(在原有的文件名称前加了 container)
在 1.6.4 中没有--new 选项:生成系统化的单位文件,这些文件在服务启动和停止命令处创建和删除容器。此类单位文件不绑定到单个计算机,可以轻松地在其他计算机上共享和使用。
10)停止删除原本的 http 容器
[contsvc@localhost user]$ podman stop myweb
若没有--new 参数不需要删除容器
[contsvc@localhost user]$ podman rm myweb
11)强制 systemd 重启加载配置
[contsvc@localhost user]$ systemctl --user daemon-reload
[contsvc@localhost user]$ podman ps -a
[contsvc@localhost user]$ podman ps
12)启动并启用 container-myweb 服务
[contsvc@localhost user]$ loginctl enable-linger
[contsvc@localhost user]$ systemctl --user enable --now container-myweb.service
13)验证
[contsvc@localhost user]$ systemctl --user status container-myweb.service #active
[contsvc@localhost user]$ curl http://localhost:8080
hello world
14)验证重启也自启
[contsvc@localhost user]$ su -
[root@localhost ~]# reboot
[root@localhost ~]# curl http://127.0.0.1:8080
hello world!
[root@localhost ~]# ssh contsvc@127.0.0.1