网站建设的标准图片分享网站建设
1. 李四(项目负责人)操作步骤
- 在github中创建远程版本库testgit
- 将基础代码上传⾄testgit远程库
- 远程库中基于main分⽀创建dev分⽀
- 将 githubleaflife/testgit 共享给组员
- 李四继续在基础代码上添加⾃⼰负责的模块内容
2. 张三、王五(组员)操作步骤
- 在桌⾯新建zhangsan⽂件夹
- 登录⾃⼰的github账户中
- GitHub搜索githubleaflife/testgit fork到⾃⼰的账户中
- 下载源码到本地新增模块功能
3.协同开发过程中遇到问题
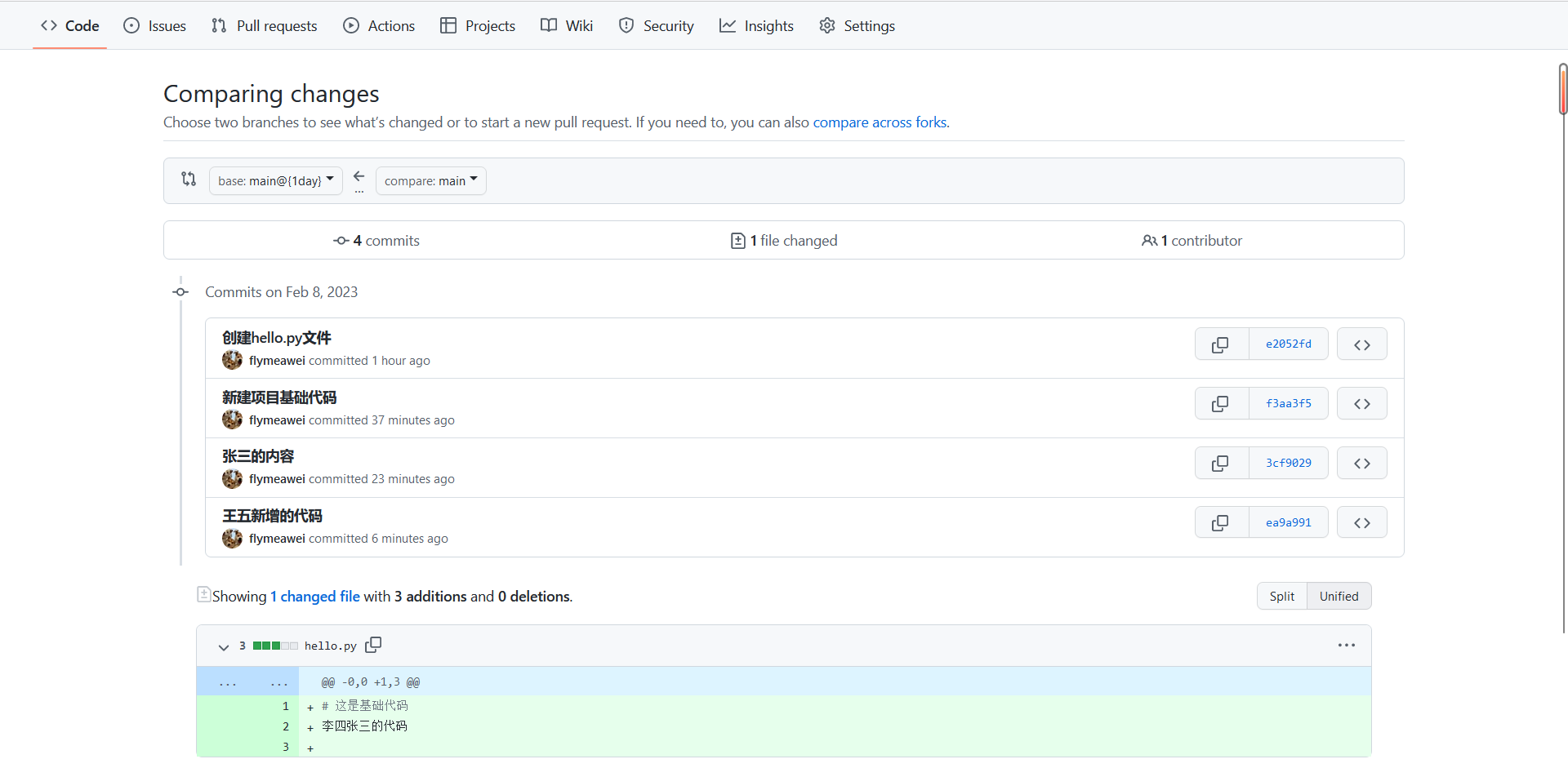
上传代码到远程库
李四负责人
➜ ~ cd 桌面
➜ 桌面 mkdir lisi_fuzeren
➜ 桌面 cd lisi_fuzeren
➜ lisi_fuzeren git clone git@github.com:flymeawei/testgit.git
正克隆到 'testgit'...
remote: Enumerating objects: 8, done.
remote: Counting objects: 100% (8/8), done.
remote: Compressing objects: 100% (5/5), done.
remote: Total 8 (delta 1), reused 4 (delta 1), pack-reused 0
接收对象中: 100% (8/8), 完成.
处理 delta 中: 100% (1/1), 完成.
➜ lisi_fuzeren ls
testgit
➜ lisi_fuzeren cd testgit
➜ testgit git:(main) ls
hello.py LICENSE README.md
➜ testgit git:(main) ls -a
. .. .git .gitignore hello.py LICENSE README.md
➜ testgit git:(main) cat hello.py
i = 10
➜ testgit git:(main) vi hello.py
➜ testgit git:(main) ✗ git branch
➜ testgit git:(main) ✗
➜ testgit git:(main) ✗ git add hello.py
➜ testgit git:(main) ✗ git commit -m "新建项目基础代码"
[main f3aa3f5] 新建项目基础代码1 file changed, 1 insertion(+), 1 deletion(-)
➜ testgit git:(main) git status
位于分支 main
您的分支领先 'origin/main' 共 1 个提交。(使用 "git push" 来发布您的本地提交)无文件要提交,干净的工作区
➜ testgit git:(main) git pull --rebase origin main
来自 github.com:flymeawei/testgit* branch main -> FETCH_HEAD
当前分支 main 是最新的。
➜ testgit git:(main) git push -u origin main
枚举对象中: 5, 完成.
对象计数中: 100% (5/5), 完成.
使用 2 个线程进行压缩
压缩对象中: 100% (2/2), 完成.
写入对象中: 100% (3/3), 319 字节 | 319.00 KiB/s, 完成.
总共 3 (差异 1),复用 0 (差异 0)
remote: Resolving deltas: 100% (1/1), c
张三负责人
~ cd 桌面
➜ 桌面 ls
'19 芒果头条项目' FlaskProjects PythonProjects zs_fuzerenDjangoProjects lisi_fuzeren test
➜ 桌面 cd FlaskProjects
➜ FlaskProjects git clone git@github.com:flymeawei/testgit.git
正克隆到 'testgit'...
remote: Enumerating objects: 11, done.
remote: Counting objects: 100% (11/11), done.
remote: Compressing objects: 100% (7/7), done.
remote: Total 11 (delta 2), reused 6 (delta 1), pack-reused 0
接收对象中: 100% (11/11), 完成.
处理 delta 中: 100% (2/2), 完成.
➜ FlaskProjects ls
flaskProject01 testgit
➜ FlaskProjects ls -a
. .. flaskProject01 testgit
➜ FlaskProjects cd testgit
➜ testgit git:(main) ls
hello.py LICENSE README.md
➜ testgit git:(main) ls -a
. .. .git .gitignore hello.py LICENSE README.md
➜ testgit git:(main) cat hello.py
# 这是基础代码
➜ testgit git:(main) vi hello.py
➜ testgit git:(main) ✗ git add hello.py
➜ testgit git:(main) ✗ git commit -m "张三的内容"
[main 3cf9029] 张三的内容1 file changed, 1 insertion(+)
➜ testgit git:(main) ls
hello.py LICENSE README.md
➜ testgit git:(main) cat hello.py
# 这是基础代码
这是张三的代码
➜ testgit git:(main)
➜ testgit git:(main)
➜ testgit git:(main) git status
位于分支 main
您的分支领先 'origin/main' 共 1 个提交。(使用 "git push" 来发布您的本地提交)无文件要提交,干净的工作区
➜ testgit git:(main) git pull --rebase origin main
来自 github.com:flymeawei/testgit* branch main -> FETCH_HEAD
当前分支 main 是最新的。
➜ testgit git:(main) git push -u origin main
枚举对象中: 5, 完成.
对象计数中: 100% (5/5), 完成.
使用 2 个线程进行压缩
压缩对象中: 100% (2/2), 完成.
写入对象中: 100% (3/3), 318 字节 | 318.00 KiB/s, 完成.
总共 3 (差异 1),复用 0 (差异 0)
remote: Resolving deltas: 100% (1/1), completed with 1 local object.
To github.com:flymeawei/testgit.gitf3aa3f5..3cf9029 main -> main
分支 'main' 设置为跟踪来自 'origin' 的远程分支 'main'。
➜ testgit git:(main) git status
位于分支 main
您的分支与上游分支 'origin/main' 一致。无文件要提交,干净的工作区
➜ testgit git:(main)
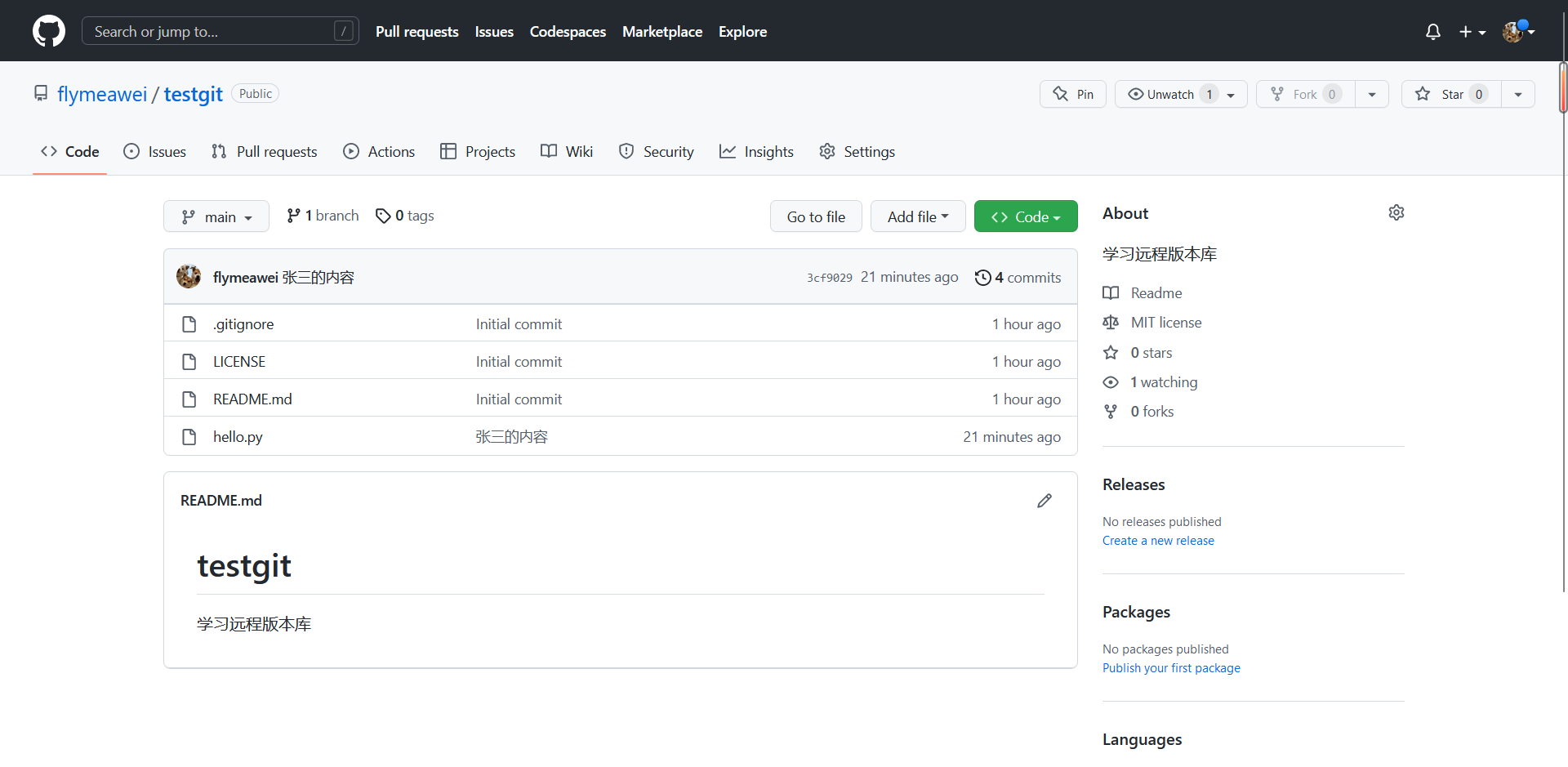
王五负责人
➜ ~ cd 桌面/ww_fuzeren
➜ ww_fuzeren git init
已初始化空的 Git 仓库于 /home/sanha/桌面/ww_fuzeren/.git/
➜ ww_fuzeren git:(master) git checkout -b dev
切换到一个新分支 'dev'
➜ ww_fuzeren git:(dev) git clone git@github.com:flymeawei/testgit.git
正克隆到 'testgit'...
remote: Enumerating objects: 14, done.
remote: Counting objects: 100% (14/14), done.
remote: Compressing objects: 100% (9/9), done.
remote: Total 14 (delta 3), reused 8 (delta 1), pack-reused 0
接收对象中: 100% (14/14), 完成.
处理 delta 中: 100% (3/3), 完成.
➜ ww_fuzeren git:(dev) ✗ ls
testgit
➜ ww_fuzeren git:(dev) ✗ cd testgit
➜ testgit git:(main) ls
hello.py LICENSE README.md
➜ testgit git:(main) vi hello.py
➜ testgit git:(main) ✗ git add hello.py
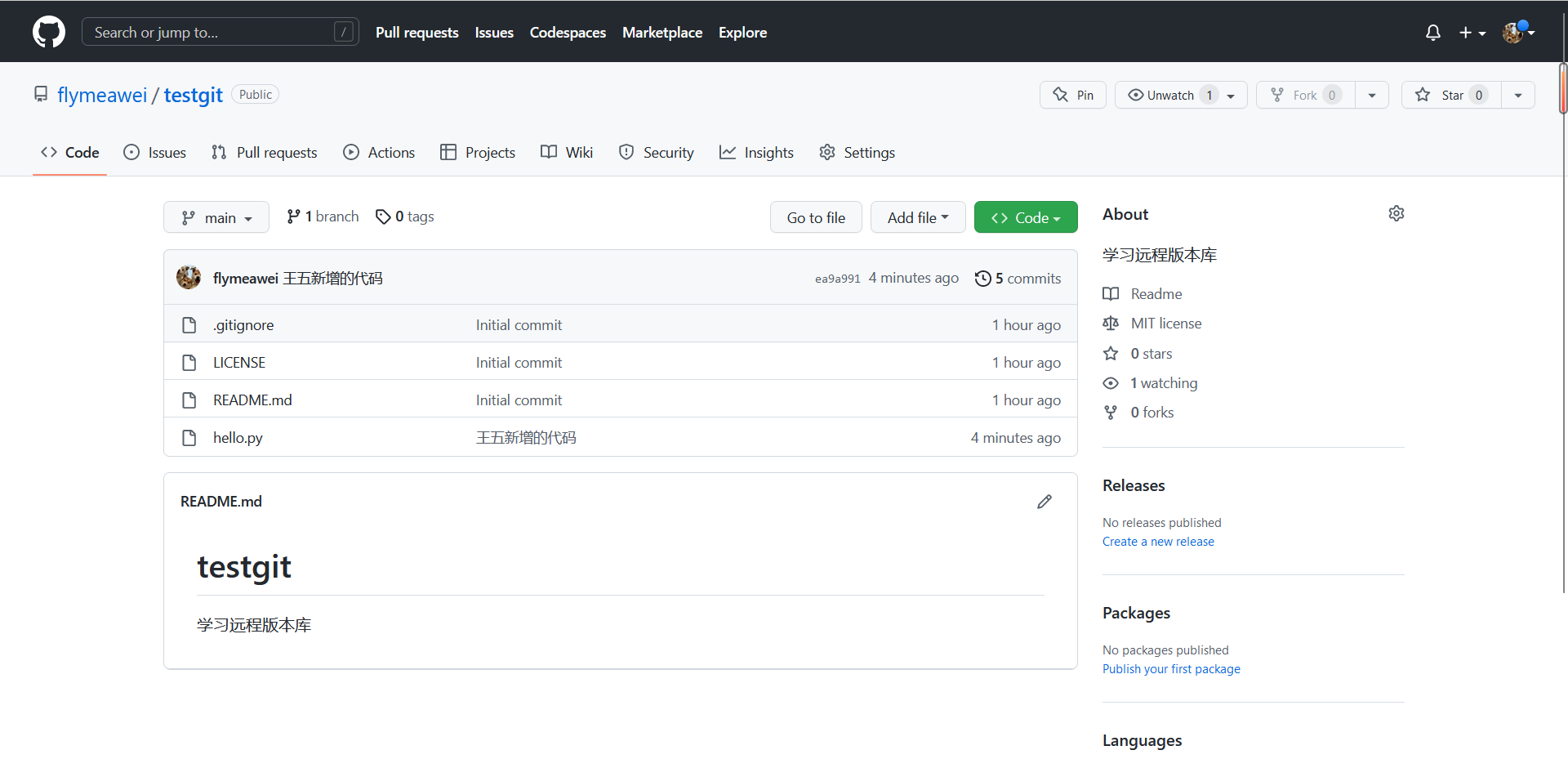
➜ testgit git:(main) ✗ git commit -m "王五新增的代码"
[main ea9a991] 王五新增的代码1 file changed, 2 insertions(+), 1 deletion(-)
➜ testgit git:(main) git status
位于分支 main
您的分支领先 'origin/main' 共 1 个提交。(使用 "git push" 来发布您的本地提交)无文件要提交,干净的工作区
➜ testgit git:(main) git pull --rebase origin main
来自 github.com:flymeawei/testgit* branch main -> FETCH_HEAD
当前分支 main 是最新的。
➜ testgit git:(main) git push -u origin main
枚举对象中: 5, 完成.
对象计数中: 100% (5/5), 完成.
使用 2 个线程进行压缩
压缩对象中: 100% (2/2), 完成.
写入对象中: 100% (3/3), 330 字节 | 330.00 KiB/s, 完成.
总共 3 (差异 1),复用 0 (差异 0)
remote: Resolving deltas: 100% (1/1), completed with 1 local object.
To github.com:flymeawei/testgit.git3cf9029..ea9a991 main -> main
分支 'main' 设置为跟踪来自 'origin' 的远程分支 'main'。
➜ testgit git:(main)
Pull request
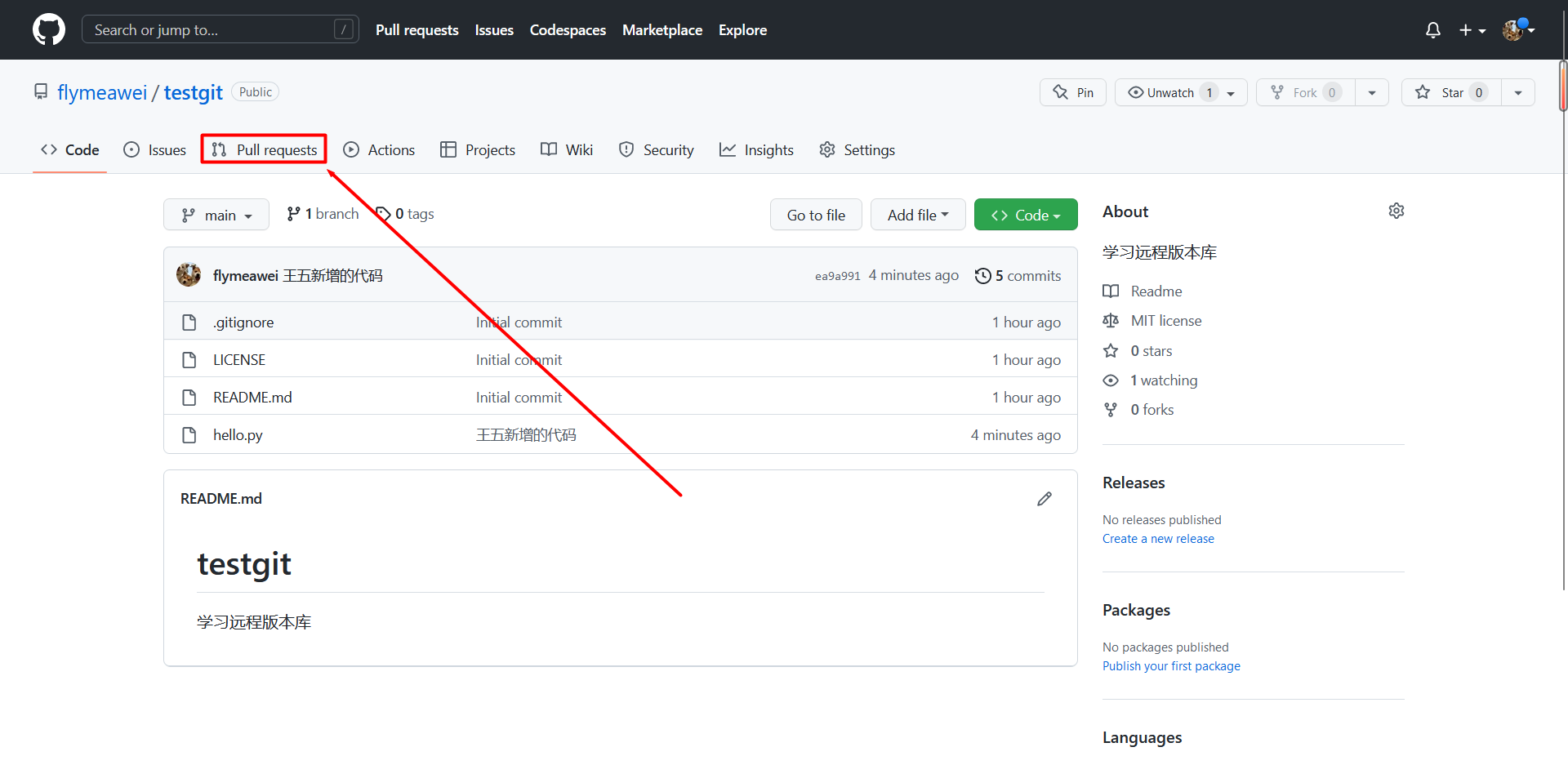
new pull request
合并