做网站项目团队口号建设项目环境影响评价验收网站
刚体上的两个点速度之间的关系
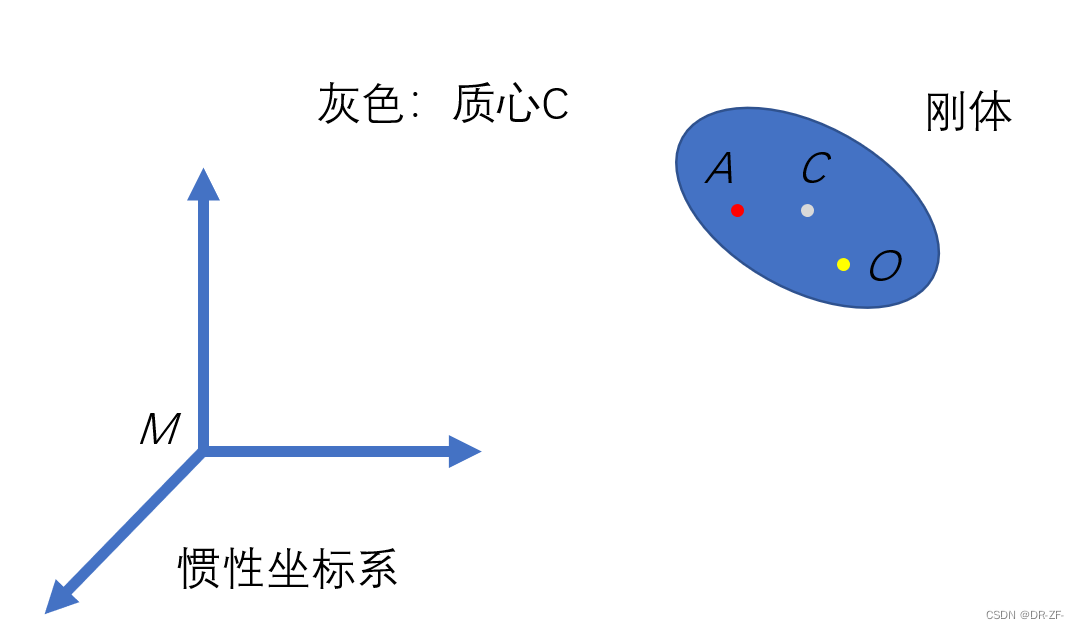
注意:这里所讨论的都是投影在惯性坐标系上的。
dMA=dMO+dOA=dMO+dCA−dCOd_{_{MA}}=d_{_{MO}}+d_{_{OA}}=d_{_{MO}}+d_{_{CA}}-d_{_{CO}}dMA=dMO+dOA=dMO+dCA−dCO
求导
d˙MA=d˙MO+d˙CA−d˙CO\dot d_{_{MA}}=\dot d_{_{MO}}+\dot d_{_{CA}}-\dot d_{_{CO}}d˙MA=d˙MO+d˙CA−d˙CO
即
vA=vO+ω×dCA−ω×dCO=vO+ω×dOAv_{_{A}}=v_{_{O}}+\boldsymbol{\omega}^{\times} d_{_{CA}}-\boldsymbol{\omega}^{\times}d_{_{CO}}=v_{_{O}}+\boldsymbol{\omega}^{\times} d_{_{OA}}vA=vO+ω×dCA−ω×dCO=vO+ω×dOA
如果把这个投影到刚体本体系中依然成立。