宁波专业建网站外包网店美工教案
文章目录
- 一、国内图床比较
- 二、使用Github搭建图床
- 三、PicGo整合Github图床
- 1、下载并安装PicGo
- 2、设置图床
- 3、整合jsDelivr
- 具体配置介绍
- 4、测试
- 5、附录
- 四、Typora整合PicGo实现自动上传
每次写博客时,我都会习惯在Typora写好,然后再复制粘贴到对应的网站上。但是难免会遇到一些问题:Typora里的图片是无法直接赋值粘贴到网上的,因为图片存储在本地,网站上写博客的地方是读取不到本地图片的!
这个时候,图床的用途就体现出来了。使用Typora的自带功能,当我们在Typora里插入图片时,能自动的上传至网络,并且得到图片的url连接!
一、国内图床比较
图床:储存图片的服务器,有国内和国外之分。
结合网上的资料在这里举几个例子
-
公共图床:这类图床一般可以直接上传图片,会返回一个链接,供你使用
-
SM.MS图床:无需注册,没有广告,直接上传
-
路过图床:有点广告,需要注册
-
-
代码托管平台:这类图床一般是建立在代码托管平台的仓库中,使用时要公开仓库
-
GitHub:全球最大代码托管平台,目前除了国内速度慢,几乎没啥缺陷
-
Gitee:国内仿GitHub代码托管平台,但免费的各种容量上的限制,优点是国内速度快
-
七牛云:速度快,缺点是要点小钱,免费的各种限制
-
-
服务器图床:
各大云服务器:阿里云,百度云,华为云,或者私人服务器 。除了费用高,没啥缺点,全是优点
但是作为一个学生党,当然白嫖最香!
在gitee和github上纠结很久,最终选择github + jsDelivr(加速),因为gitee的免费个人的空间太小了,并且上传文件的大小限制 < 1M。
二、使用Github搭建图床
新建仓库
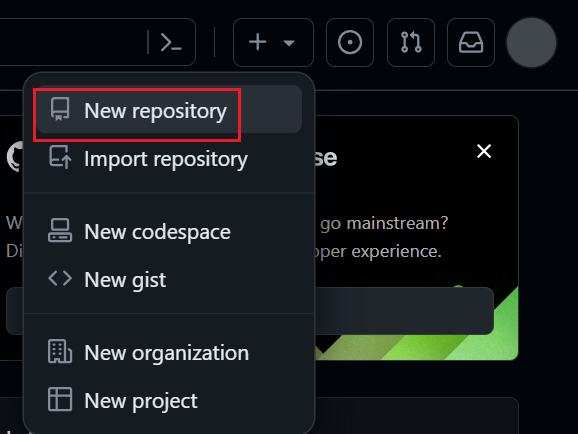

点击右上角用户头像 => settings

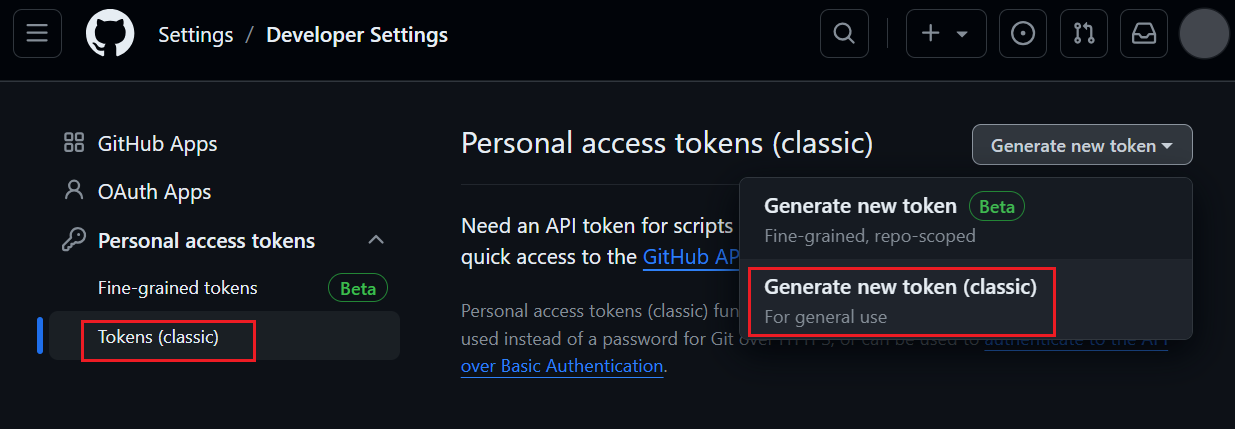
生成token令牌,往下拉,直到左侧到底,选择Developer settings

按图点击
验证选择密码验证
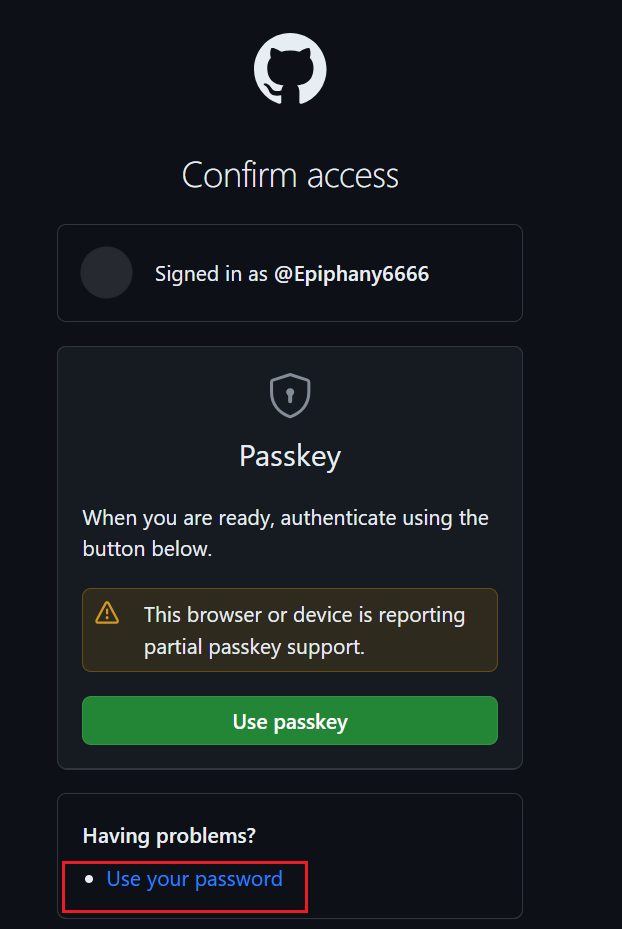
可以给令牌(token)做个Note(标记),然后选择令牌(token)截止时间。这里不建议选永久,因为不安全。基本是该图床你用到多久就选多久即可。
选择 repo 权限,然后拉到底部,选择创建就行了。

创建完毕之后,生成的Token是你的账户下的github服务器的令牌,最好用记事本记录下来,后面会用到。
三、PicGo整合Github图床
PicGo是一款优秀的图床工具,能够自动把本地图片上传至网络,并转换成可访问的链接。
1、下载并安装PicGo
下载地址:https://github.com/Molunerfinn/PicGo/releases
根据自己的操作系统(Win/Linux/Mac)来下载安装包

2、设置图床
图床设置 => Github

3、整合jsDelivr
想要知道jsDelivr的作用,首先就需要了解CDN是什么
CDN的全称是Content Delivery Network,即内容分发网络。CDN是构建在网络之上的内容分发网络,依靠部署在各地的边缘服务器,通过中心平台的负载均衡、内容分发、调度等功能模块,使用户就近获取所需内容,降低网络拥塞,提高用户访问响应速度和命中率。CDN的关键技术主要有内容存储和分发技术。
由于Github的资源在国内加载速度比较慢,因此需要使用CDN加速来优化网站打开速度,jsDelivr + Github便是免费且好用的CDN,非常适合博客网站使用。
进行图床配置:
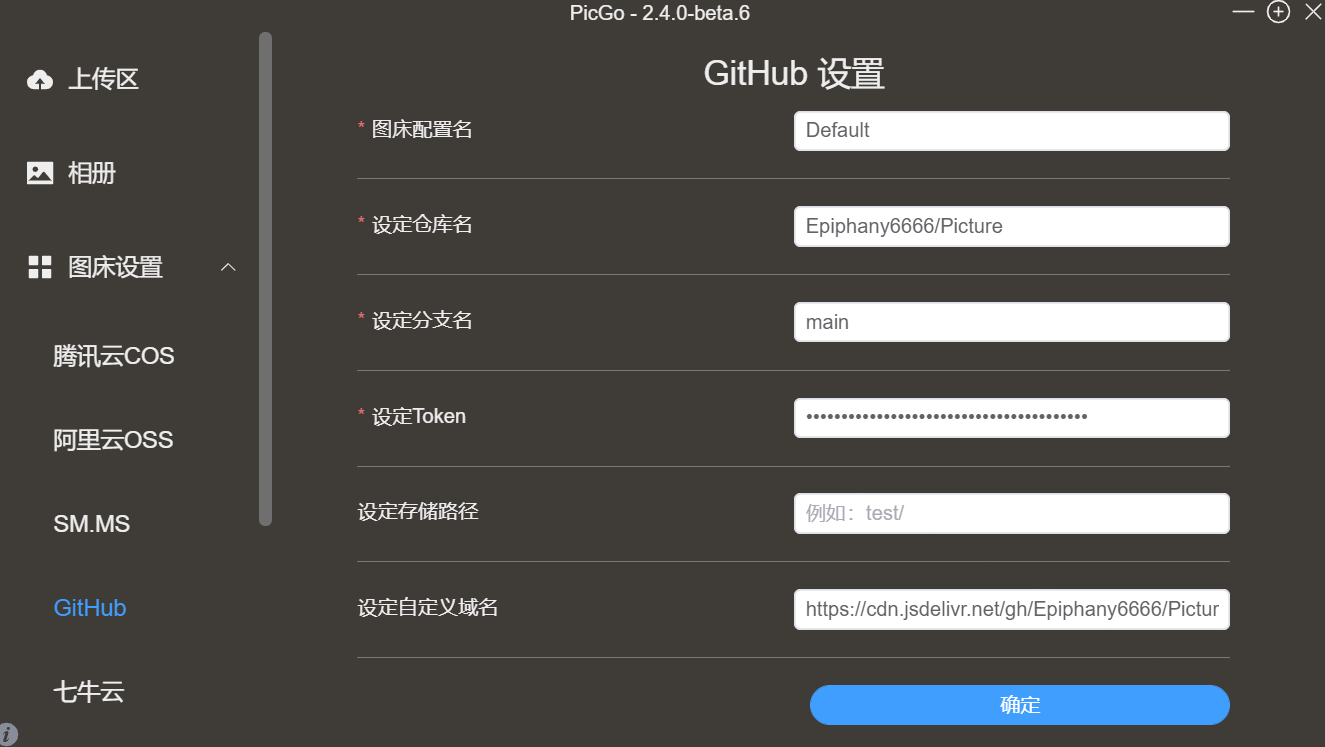
具体配置介绍
-
图床配置名:自己取
-
设定仓库名:用户名+仓库名
-
设定分支名:
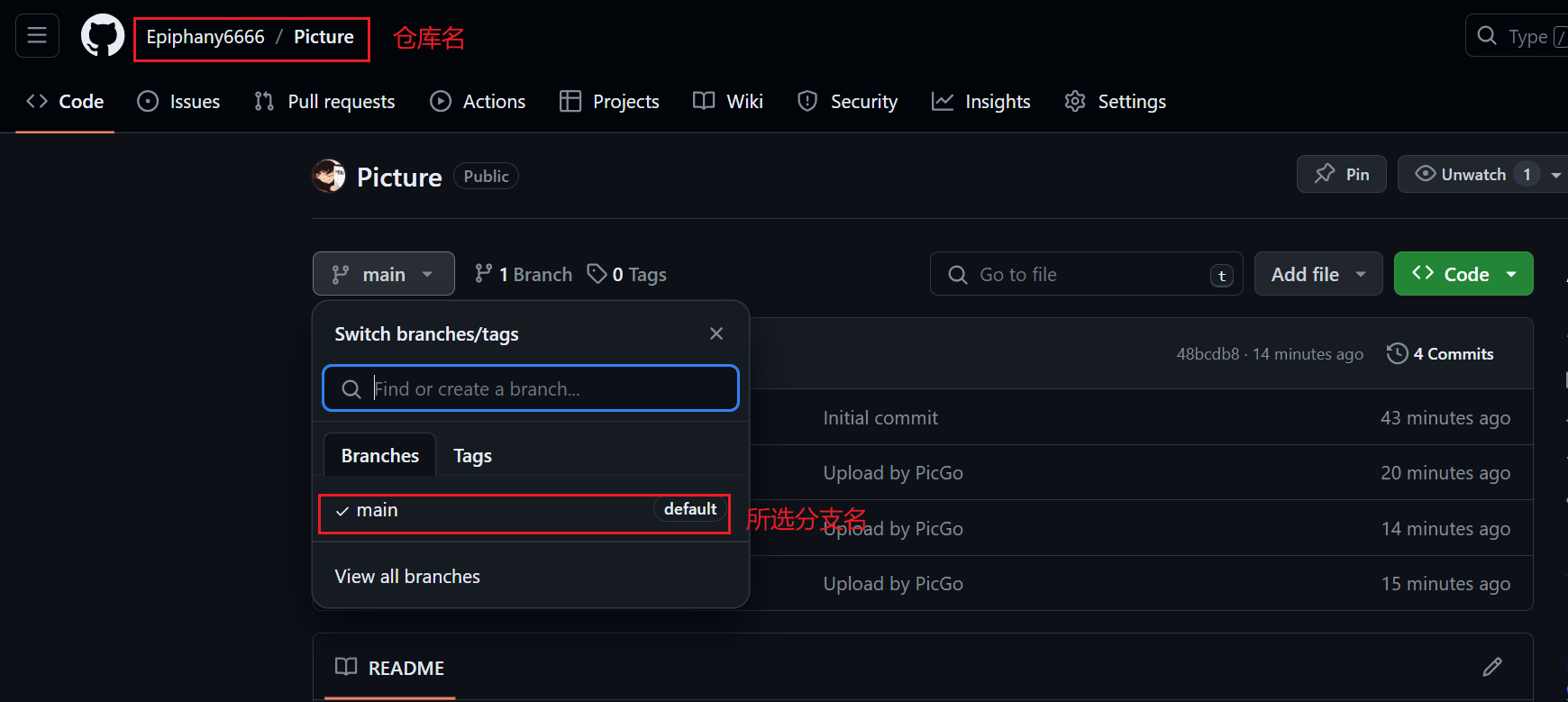
-
设定Token:就是上面我们刚刚在Github上获取的token
-
设定存储路径:需要放到仓库中的哪个文件夹下。
-
如果直接放到仓库的根目录下就不需要填写这一栏
-
如果需要放到某个目录下,直接写目录名就行,不需要在目录名前加 / 。
eg:test
-
当有多级目录时,也是直接写路径。
eg:test/test1/test2
-
当填写的目录不存在时,PicGo会自动帮你在Github上创建目录,这个不用担心!
-
-
设定自定义域名:此时就需要结合jsDelivr来加速了
打开jsDelivr官网,了解它的使用方法:https://www.jsdelivr.com

# https://cdn.jsdelivr.net/gh/:固定的前缀,相当于替换掉了Github地址中的https://github.com/ # user:Github上的用户名 # repo:仓库名 # @version:版本号(这里我们可以不管) # file:文件名(这里我们也不需要加上,因为上传完图片后,它会自动将上传的图片的名字作为存储的文件名) https://cdn.jsdelivr.net/gh/user/repo@version/file例如我的自定义域名就为:https://cdn.jsdelivr.net/gh/Epiphany6666/Picture
这里值得注意的是,如果需要指定上传到哪个分支,此时需要在自定义域名后面使用@ + 分支名,如果是仓库默认的分支,可以省略指定分支这一步。
eg:我需要上传到test分支上,此时自定义域名就变成了:https://cdn.jsdelivr.net/gh/Epiphany6666/Picture@test
4、测试
配置完成后,切换到刚刚配置好的图床,然后手动上传图片试试:可以点击’点击上传’,也可以通过拖拽的方式进行上传
PS:上传的过程中需要关闭steam++

然后,我们能够在相册中看到我们已经上传的图片,可以查看、复制已经上传的图片的URL,同时也可以将上传的图片删除。

5、附录
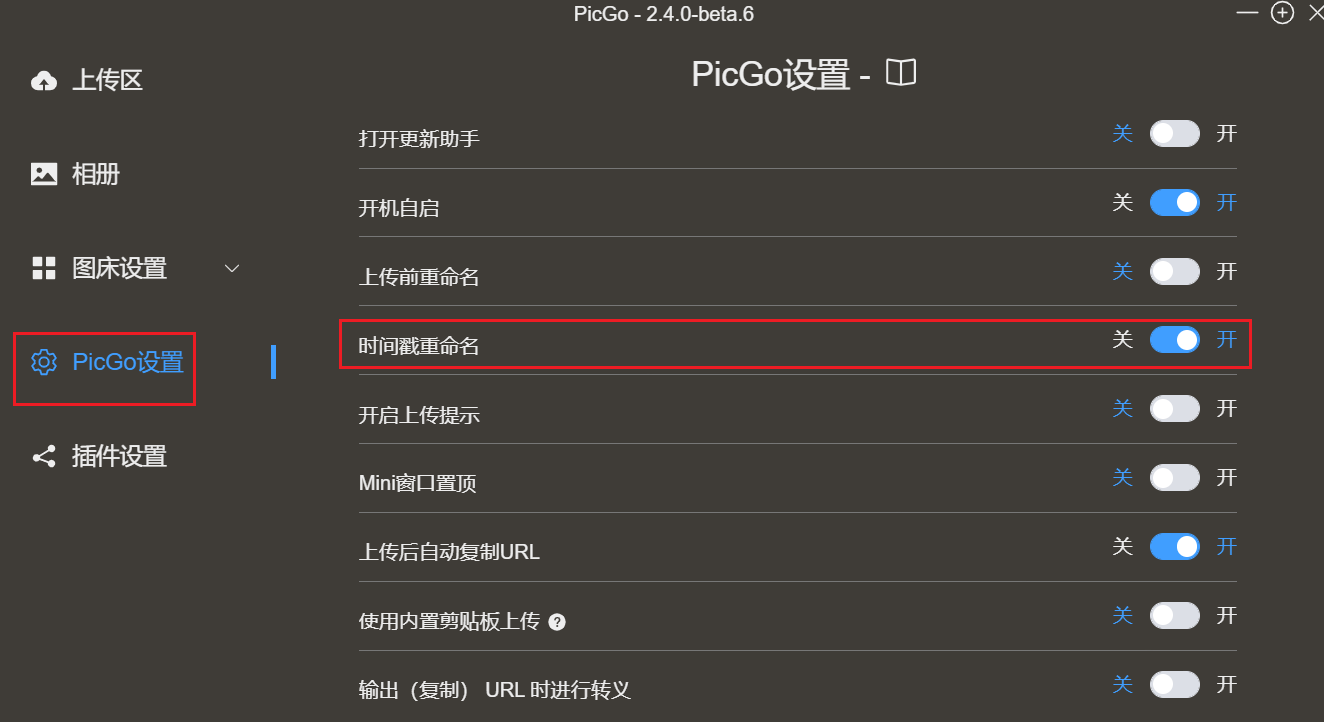
可以在PicGo设置中开启 时间戳重命名 ,这样同时上传相同的图片就不会被覆盖了。
四、Typora整合PicGo实现自动上传
PS:使用Typora上传的时候同样需要关闭steam++
在Typora中配合PicGo,就可以实现在文章中插入图片时自动上传。
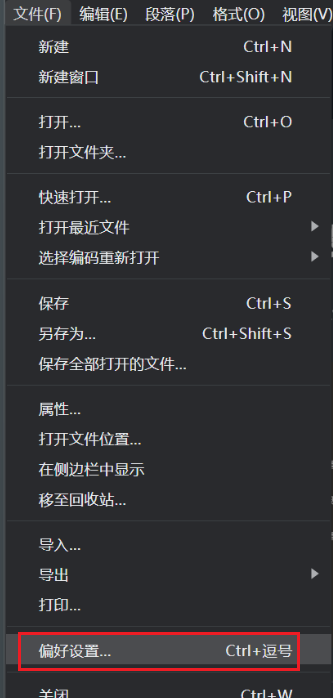
按如图所示配置。
插入图片时选择上传图片。在上传服务内选择PicGo,并选择PicGo.exe的路径。

大功告成!快去在Typora中插入一张图片试试吧!