程序员会搭建非法网站吗玉林城乡住房建设厅网站
支持向量机(SVM)的异常检测
SVM通常应用于监督式学习,但OneClassSVM[8]算法可用于将异常检测这样的无监督式学习,它学习一个用于异常检测的决策函数其主要功能将新数据分类为与训练集相似的正常值或不相似的异常值。
OneClassSVM
OneClassSVM的思想来源于这篇论文[9],SVM使用大边距的方法,它用于异常检测的主要思想是:将数据密度较高的区域分类为正,将数据密度较低的区域分类为负,如下图所示:
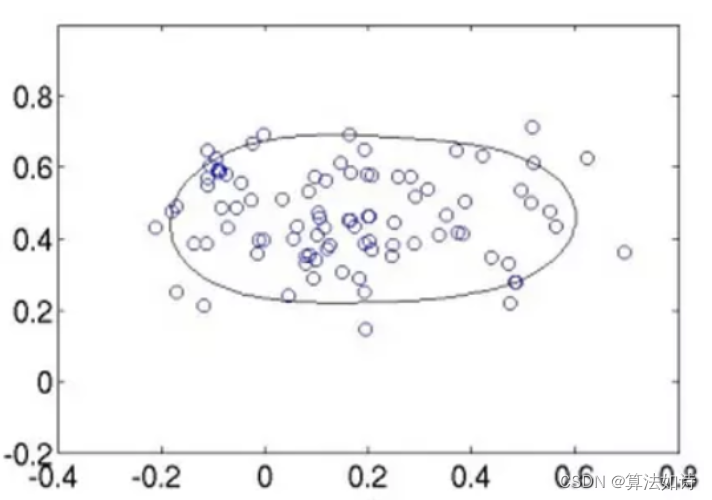
在训练OneClassSVM模型时,我们需要设置参数nu = outliers_fraction,它是训练误差分数的上限和支持向量分数的下限,并且必须在0和1之间。基本上它代表了我们期望的异常值在我们的数据集中的比例。
指定要在算法中使用的核类型:rbf。它使SVM能够使用非线性函数将超空间投影到更高维度。
gamma是RBF内核类型的参数,并控制各个训练样本的影响 - 这会影响模型的“平滑度”。
predict 对数据进行分类,因为我们的模型是单类模型,所以返回+1或-1,-1表示是异常值,1表示是正常值。
data = df[[‘price_usd’, ‘srch_booking_window’, ‘srch_saturday_night_bool’]]
scaler = StandardScaler()
np_scaled = scaler.fit_transform(data)
data = pd.DataFrame(np_scaled)