关于网站建设相关文章武威网站建设公司有
TDesign 是一套拥有完整的 设计价值观 和 视觉风格指南 的企业级设计体系,同时提供了丰富的 设计资源。TDesign 在设计体系基础上产出基于 Vue、React、小程序等业界主流技术栈的组件库解决方案。是不是有点晚了?
请大家各抒己见。



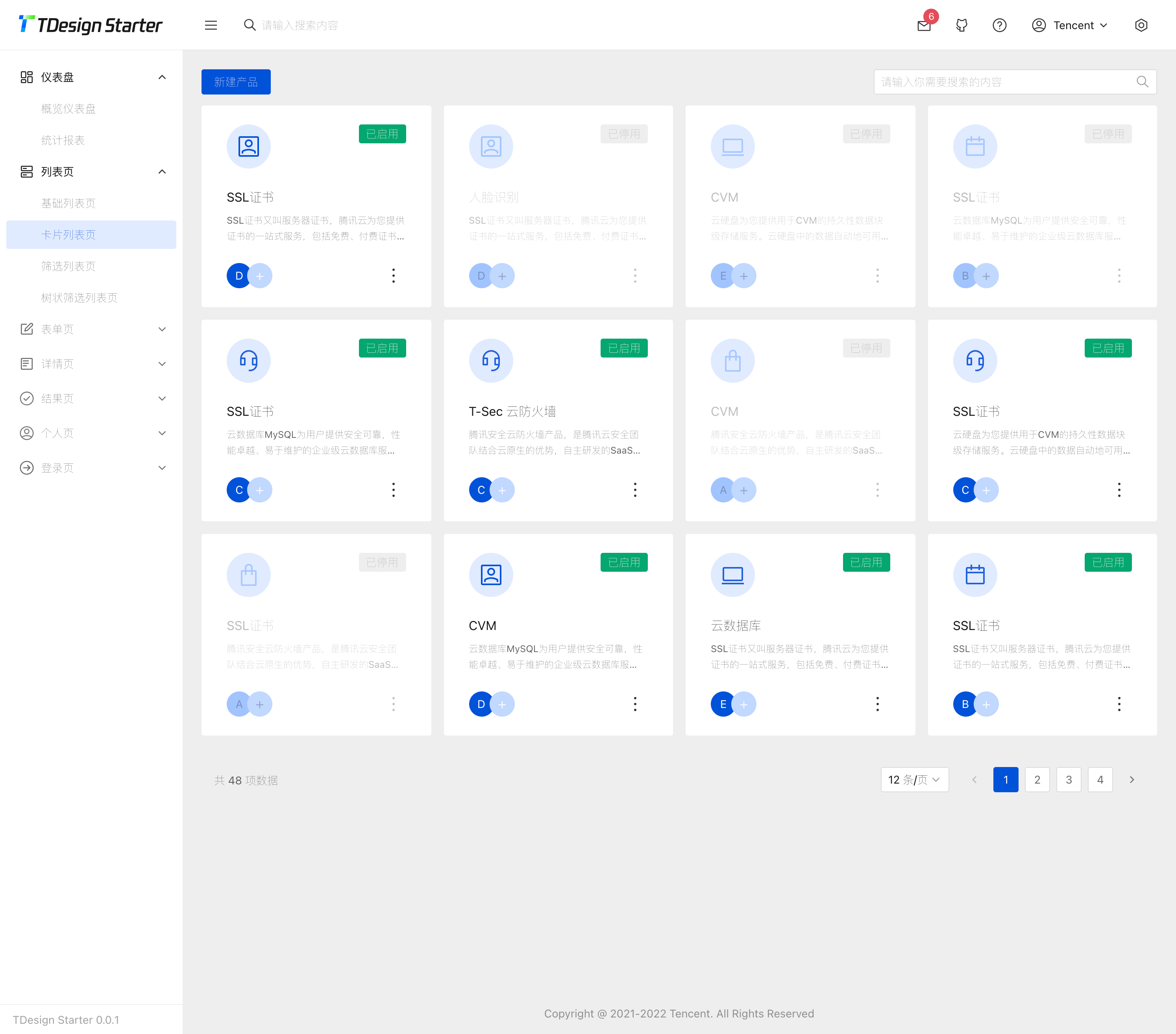
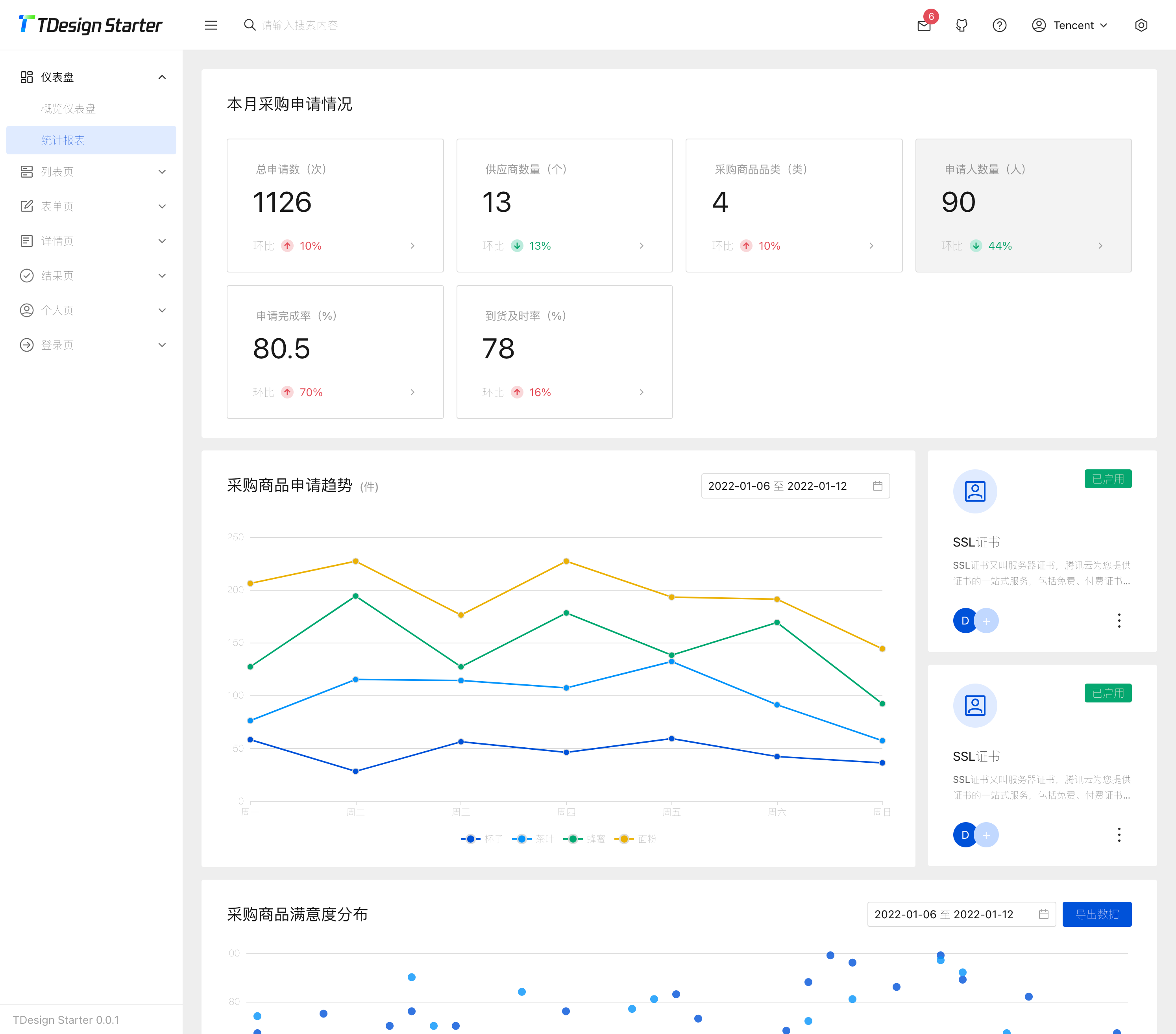
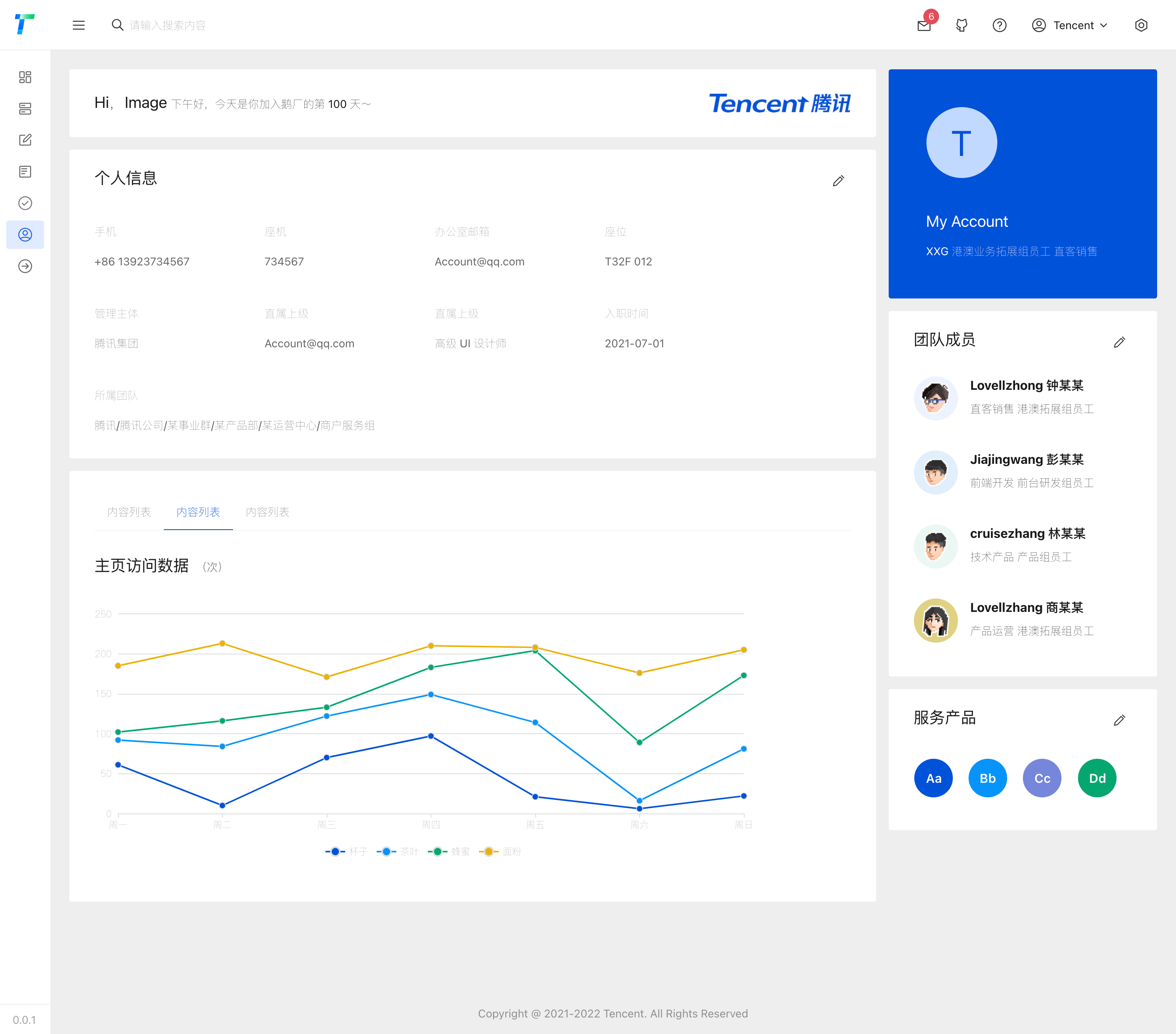
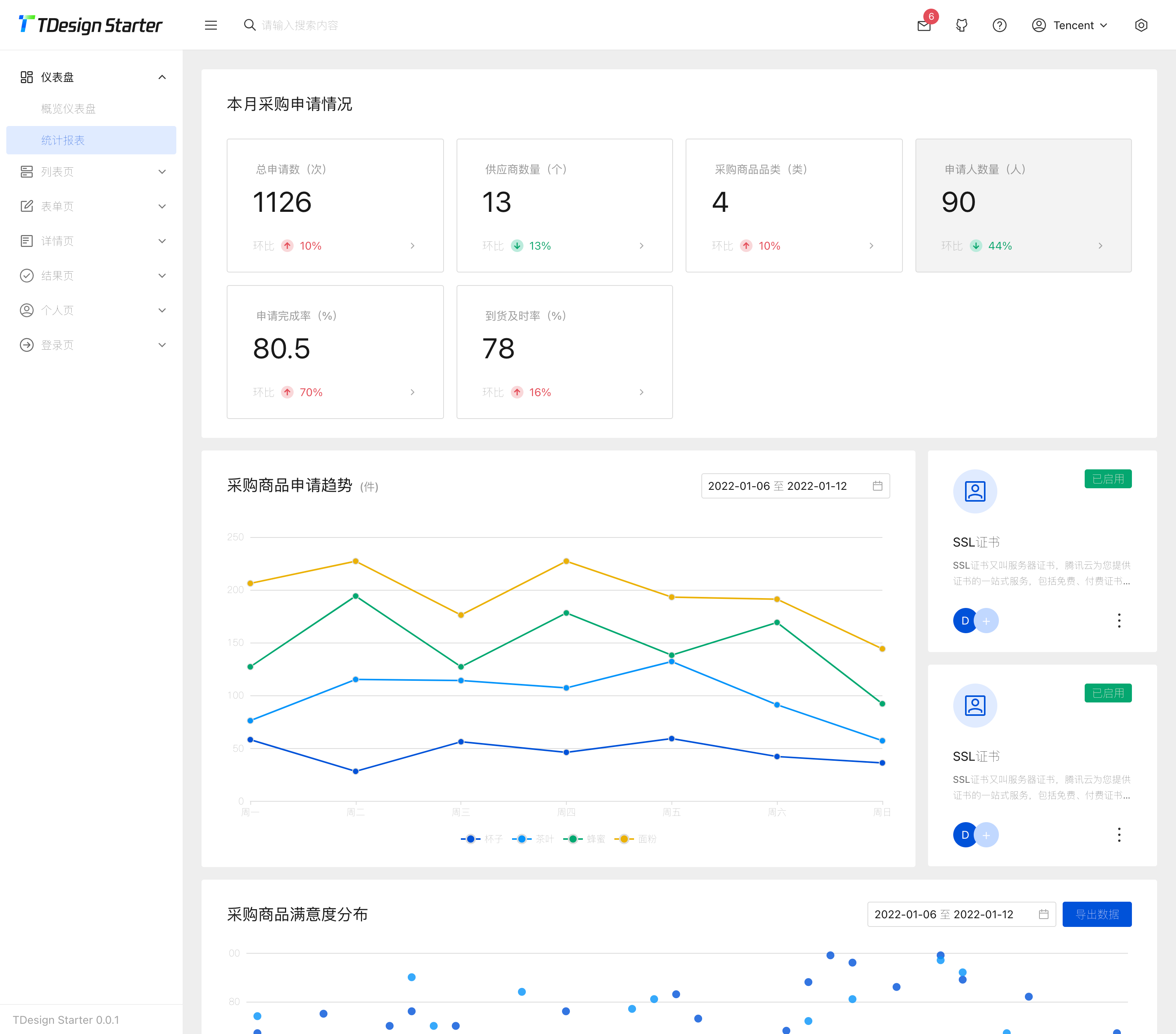
TDesign 是一套拥有完整的 设计价值观 和 视觉风格指南 的企业级设计体系,同时提供了丰富的 设计资源。TDesign 在设计体系基础上产出基于 Vue、React、小程序等业界主流技术栈的组件库解决方案。是不是有点晚了?
请大家各抒己见。