为什么搜索不到刚做的网站南通关键词优化平台

1、程序界面介绍
该程序GUI界面包括待检测水果图片加载、检测结果输出、清空可视化框等。其中包括训练模型、加载图片、重置、识别检测按钮。
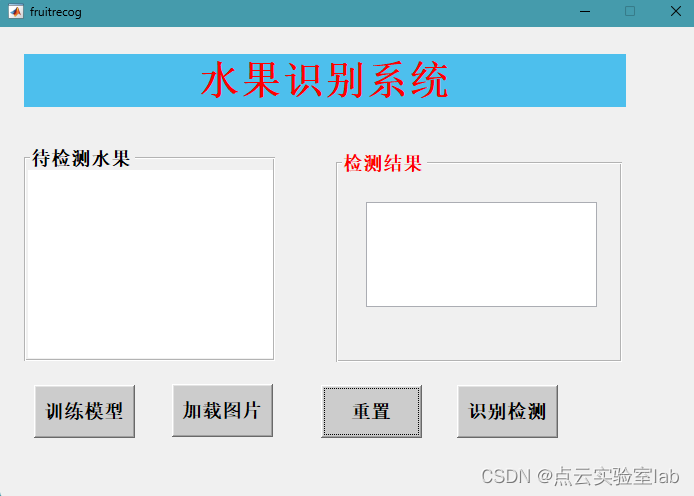
程序GUI界面
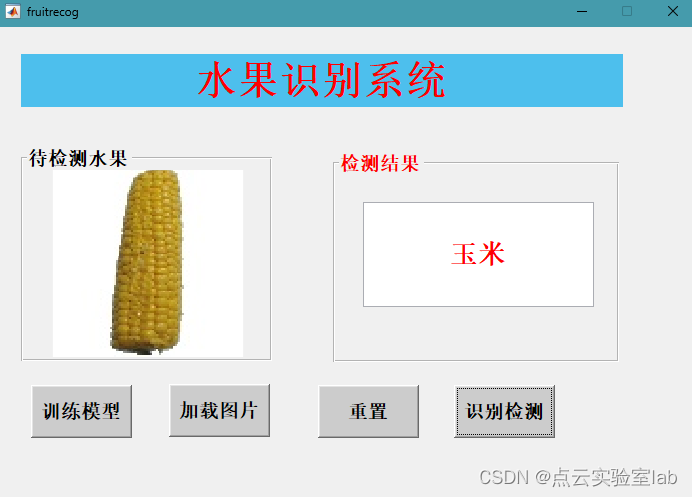 | 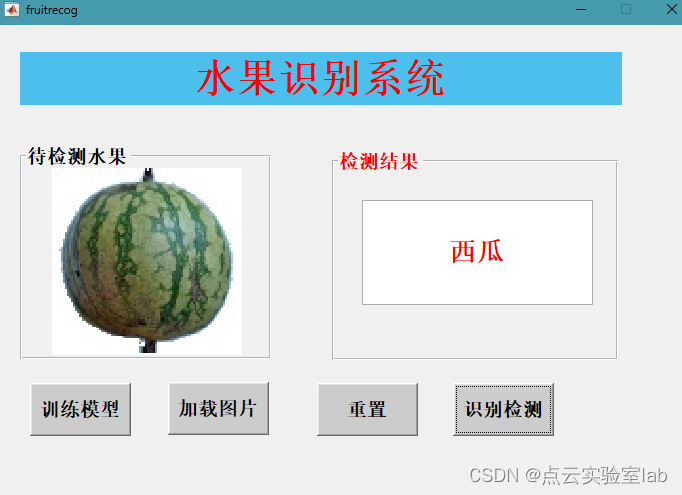 |
| 识别玉米 | 识别西瓜 |
分类器识别水果基本原理:
由于每种水果的外形存在很大差异,比如西瓜与玉米,分别为圆形与杆状形状,因此使用HOG算子算子提取图片特征。HOG特征是一种图像局部特征,其基本思路是对图像局部的梯度幅值和方向进行投票统计,形成基于梯度特性的直方图,然后将局部特征拼接起来作为总特征。局部特征在这里指的是将图像划分为多个子块(Block),每个Block内的特征进行联合以形成最终的特征。
在使用HOG算子识别图像特征后,训练基于SVM多分类模型,得到模型参数,最终实现水果分类。
2、程序的使用
2.1 程序打开
在窗口命令行中输入“guide”,在弹出对话框中,选择"fruitrecog.fig",再单击绿色三角即可运行程序。
命令行窗口输入
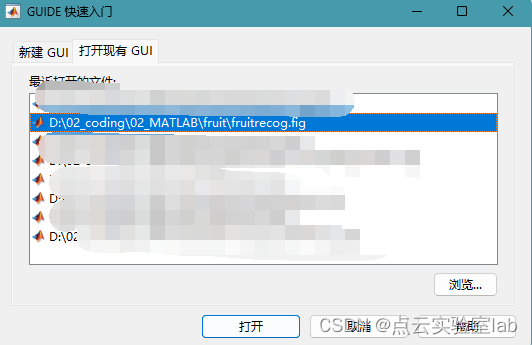
打开对话框
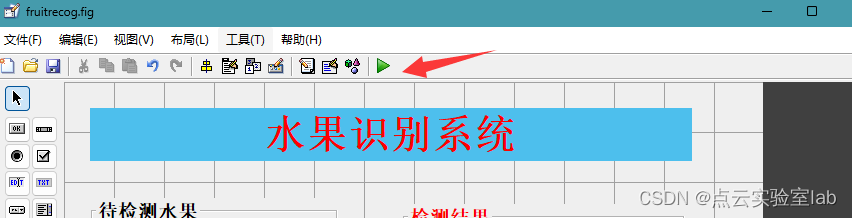
运行示意图
2.2 训练样本介绍
本程序基于支持向量机SVM进行水果识别,需要事先制作不同水果的样本数据。本次实验制作了15类水果,每一类水果包含10张训练样本,如下图所示。
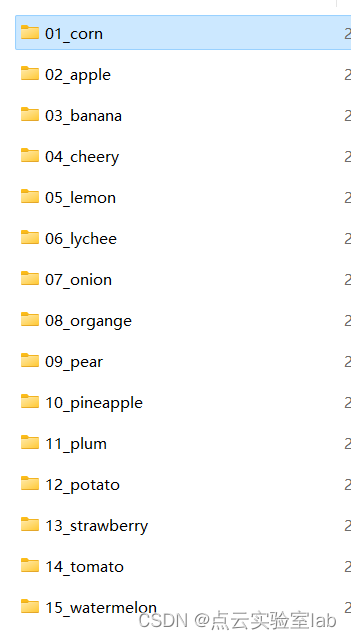
15类水果文件夹示意图
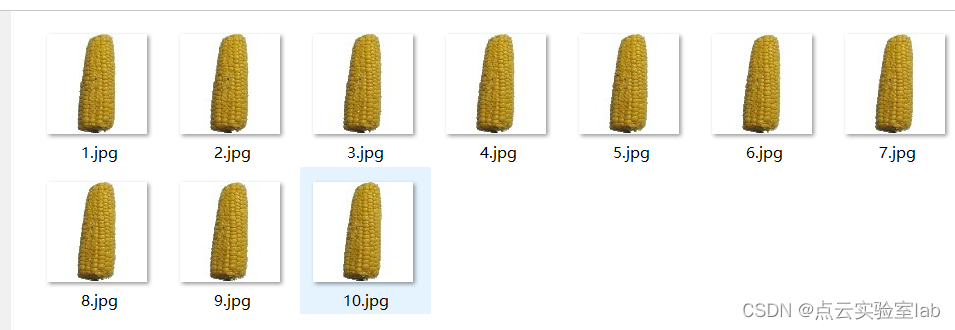
玉米文件夹下示意图

西红柿文件夹下示意图

土豆文件夹下示意图
在收集训练样本数据后,还需要制作一个包含训练样本图片的txt文本,其具体包含了每张样本数据存放的路径。因此,若下载到自己电脑上,需要在txt文本中修改图片路径。
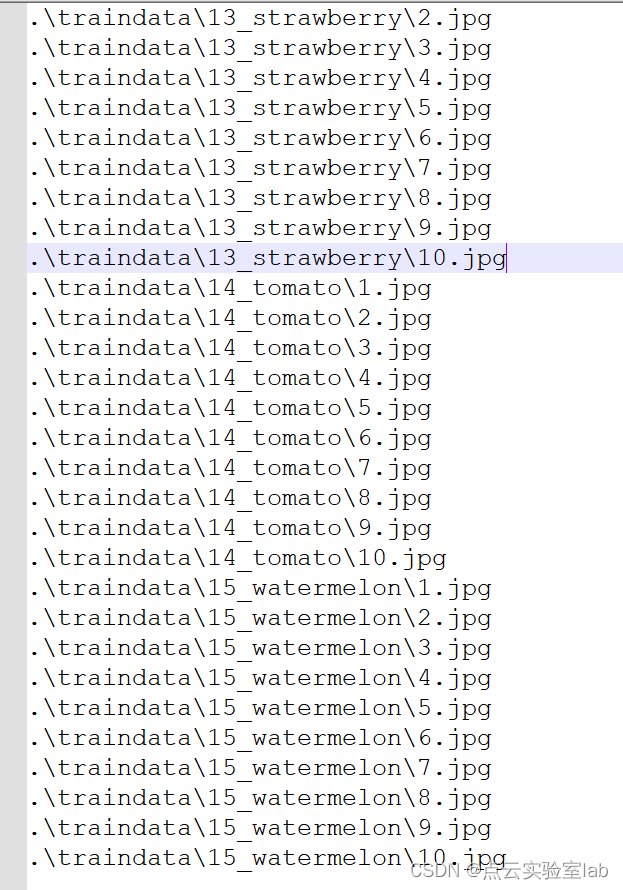
traindata.txt文本中图片路径采用相对路径方式
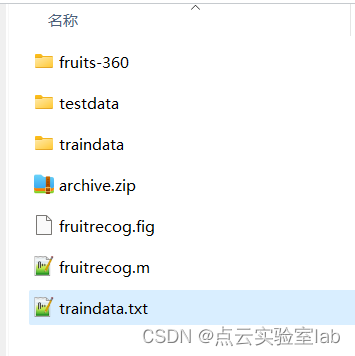
m文件与训练数据、traindata.txt在文件夹中位置关系示意图(在同一层文件夹)
******需要注意的是,下载到自己电脑上后,一定要将traindata.txt中内容,改成图片实际在你电脑上存放的绝对位置,或者不要动,保持上图截图中相对位置。********
2.3 训练模型
在制作好训练数据后,便可以训练模型。点击“训练模型”按钮,打开traindata.txt文件,确定后开始训练模型,模型训练结束后,会弹出“模型训练完成!”的提示,如下图所示。
打开训练样本文件 训练完成提示
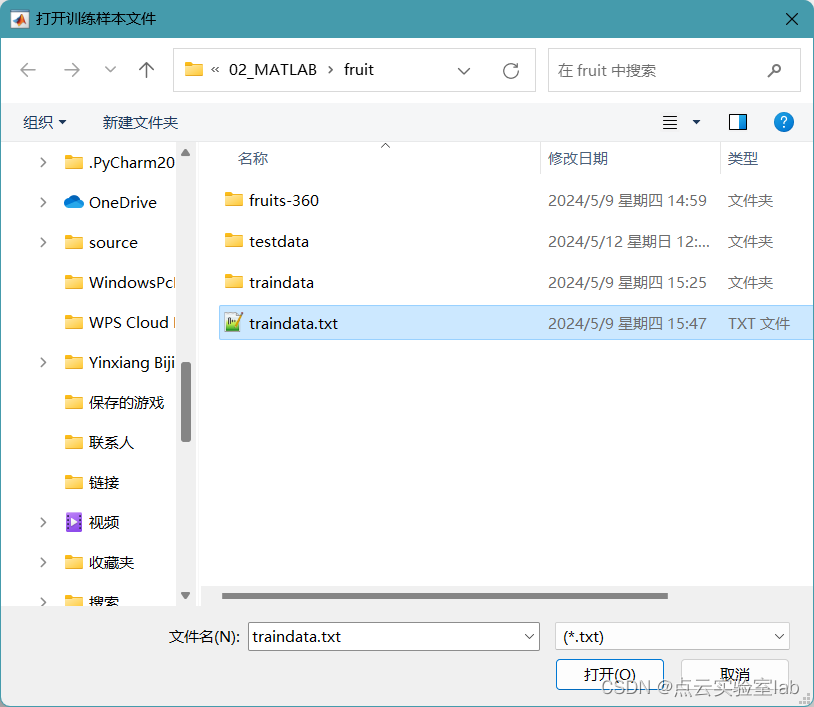
选取训练数据
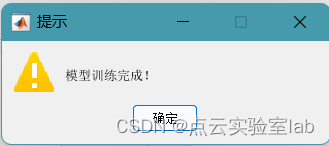
训练结束提示
2.4 识别水果
选择“加载图片”按钮,加载需要识别的水果,如选择草莓图片,再点击“识别检测”按钮,识别出该水果。
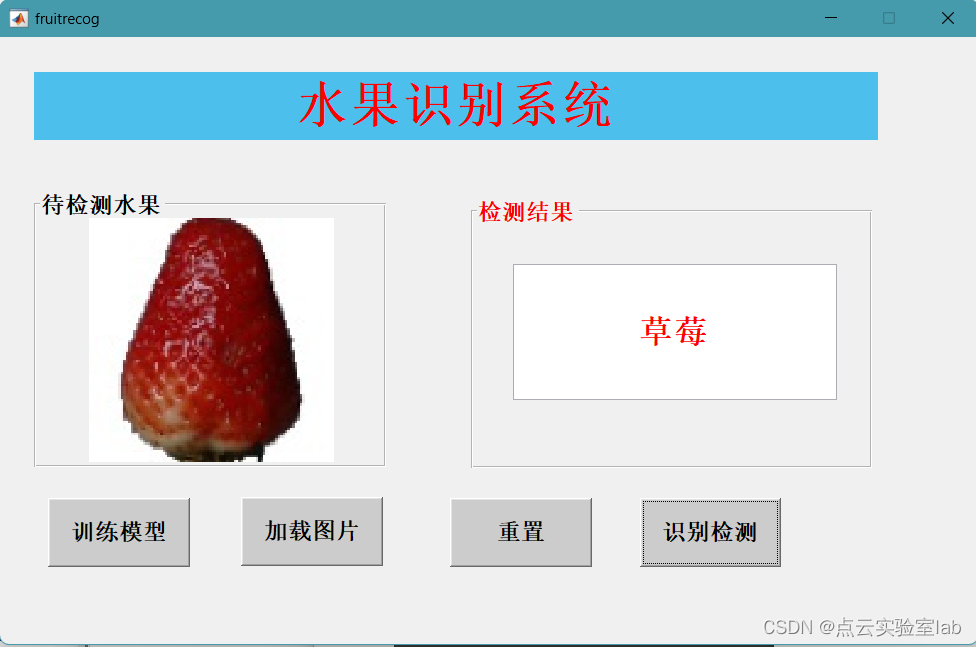
水果识别示意图
4、说明(若训练自己数据)
理论上样本制作的越多,训练的模型精度会更高。若自己想制作更多的训练样本数字训练模型,需要在traindata文件夹下,放入更多的待识别水果图片,进行训练。或者其他想要识别的水果,但是需要在以下方面进行修改
(1)traindata.txt中内容
traindata.txt是存放每个训练样本图片的路径,因此,需要根据最终制作样本图片进行修改。具体来说,将你制作多的训练样本图片路径,全部添加进来即可。
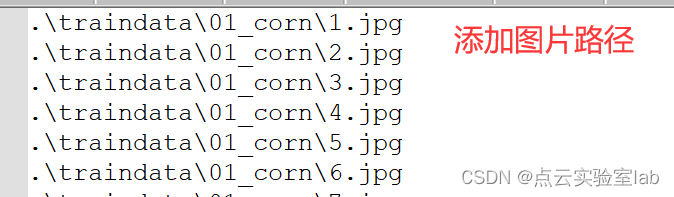
图片路径添加示意图
(2)m文件修改
在fruitrecog.fig文件中,选择“训练模型”按钮,右击,在弹出选项中选择“callback”。
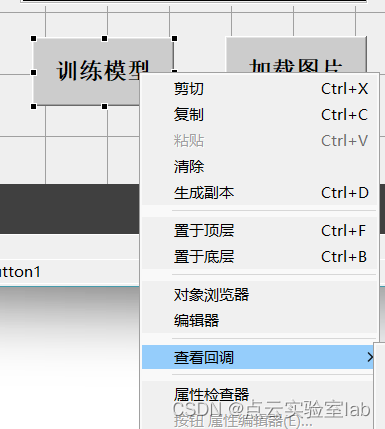
对train_label进行修改,主要修改每类水果样本数量、水果数量。其中用1-15表示每一个水果种类。若要识别的水果种类位20种,则数字位1-20。若每种水果训练样本数量为20,则每个数字出现20次,即有20个1,20个2,20个3......

最后输出显示需要修改:
修改predict_label 值与对应的水果名,这需要根据你自己实际情况进行修改。
