建设网站网站名2023楼市回暖潮无望了
一、注释

NC:no connect,默认不连接
NF: no fix,默认不安装
0R: 0R的电阻,即可以短路
二、看图流程
1、看标题,了解功能
2、浏览有几个模块
3、找芯片对应的数据手册,了解芯片功能和使用

例如CH224,通过配置CFG1、CFG2、CFG3三个引脚的电平,就可以配置不同的快充电压。
三、画图注意事项
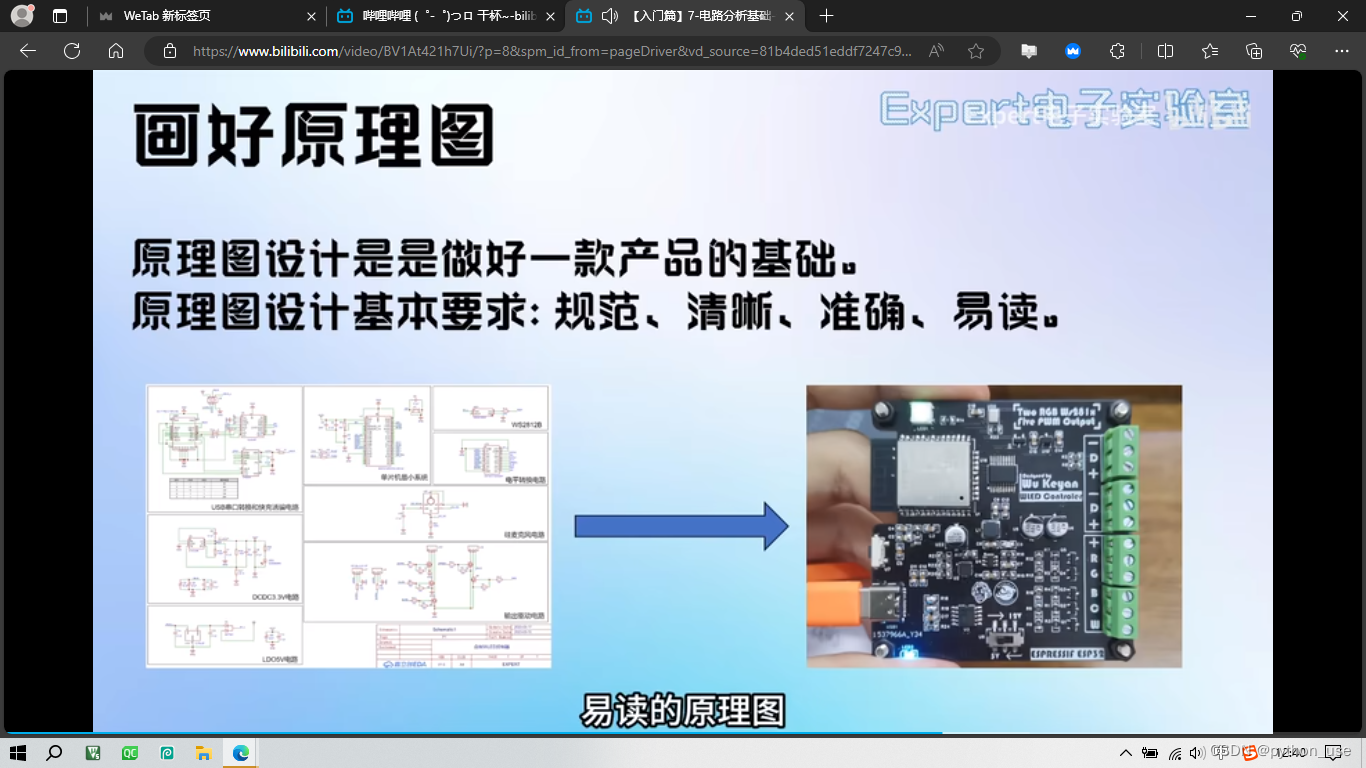
1、分模块、分图页
2.标注重要参数、重要功能以及注意事项,例如前文中快充诱骗器原理图中的表格。
3.合理的网络标签。例如MPU6050_SDA就比较清晰明了,我们就知道这根线接的是MPU6050传感器的SDA引脚
四、PCB结构与组成

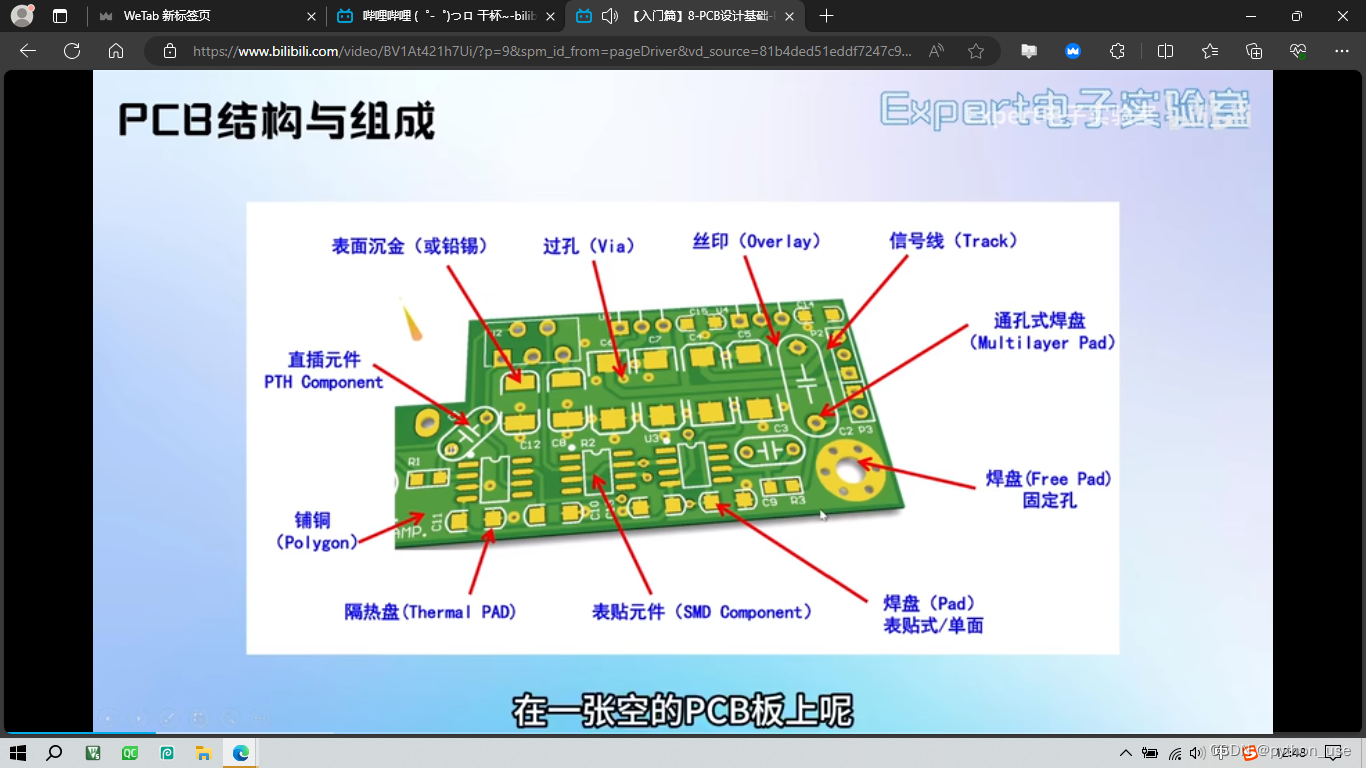


细线一般是用于连接信号线,电源线的。地线一般较多,用铺铜连接,这样有较好的散热效果

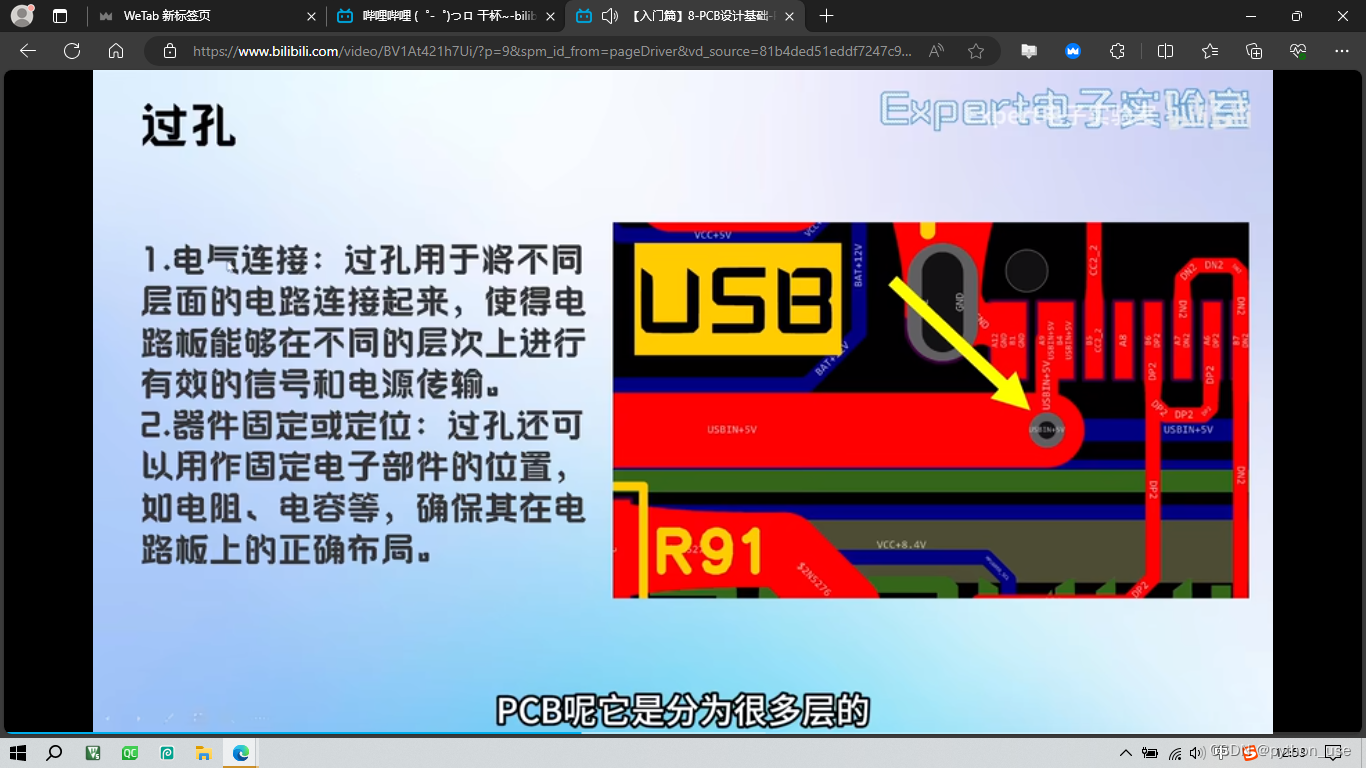
有的过孔较大,用于穿过螺丝。
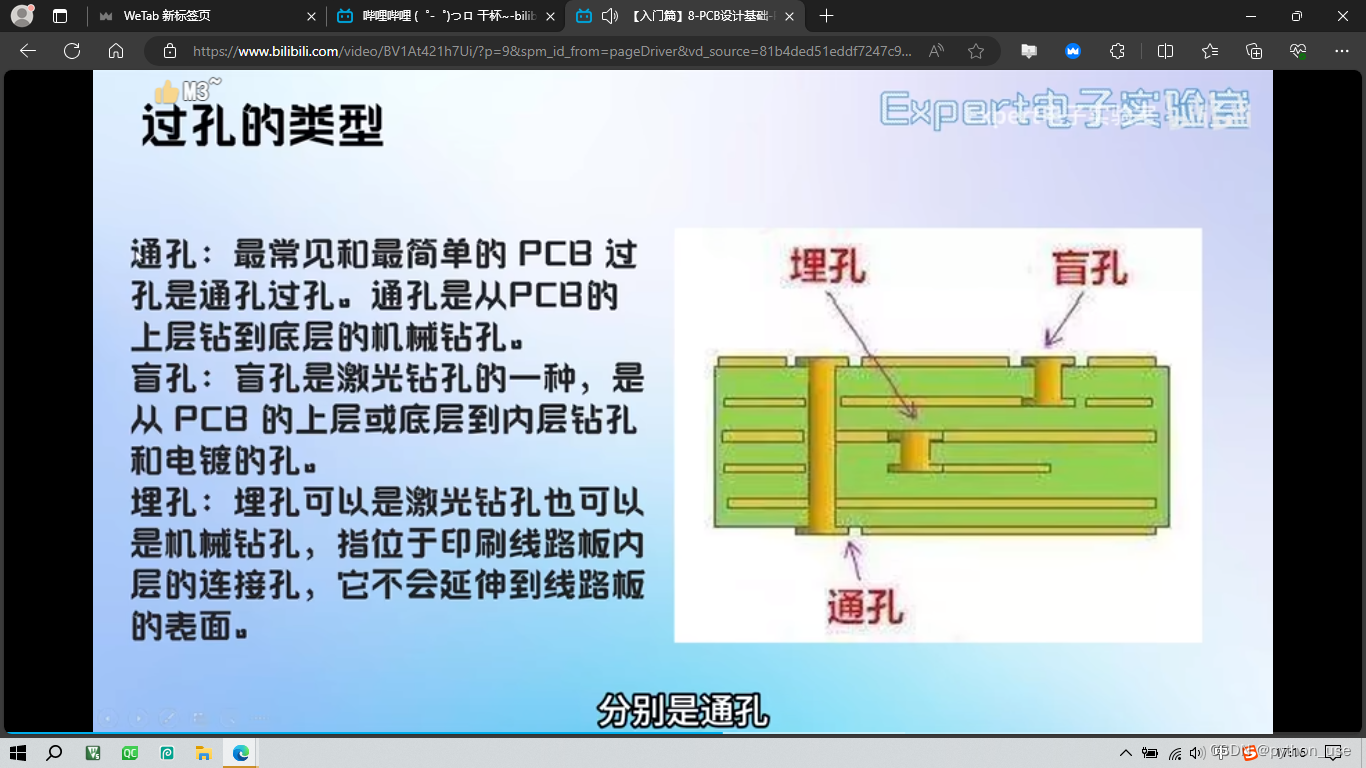
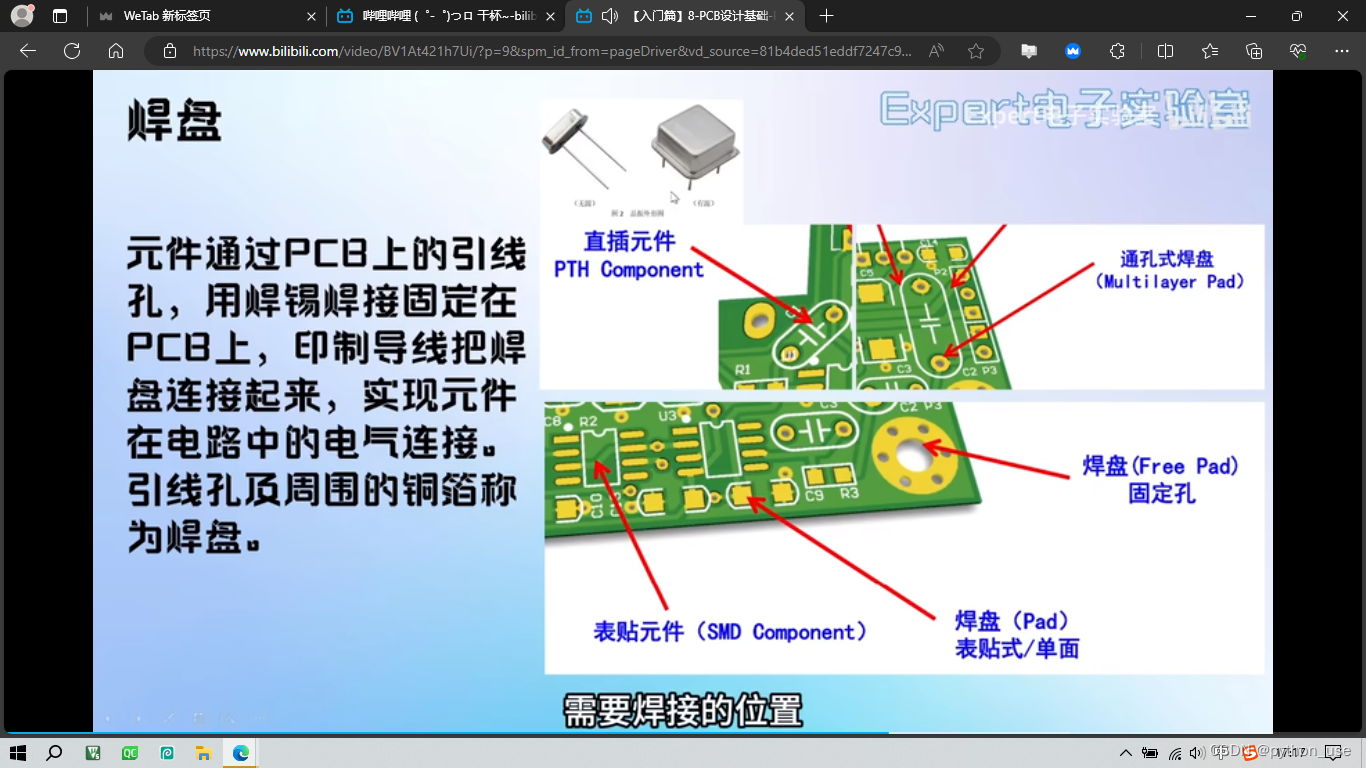
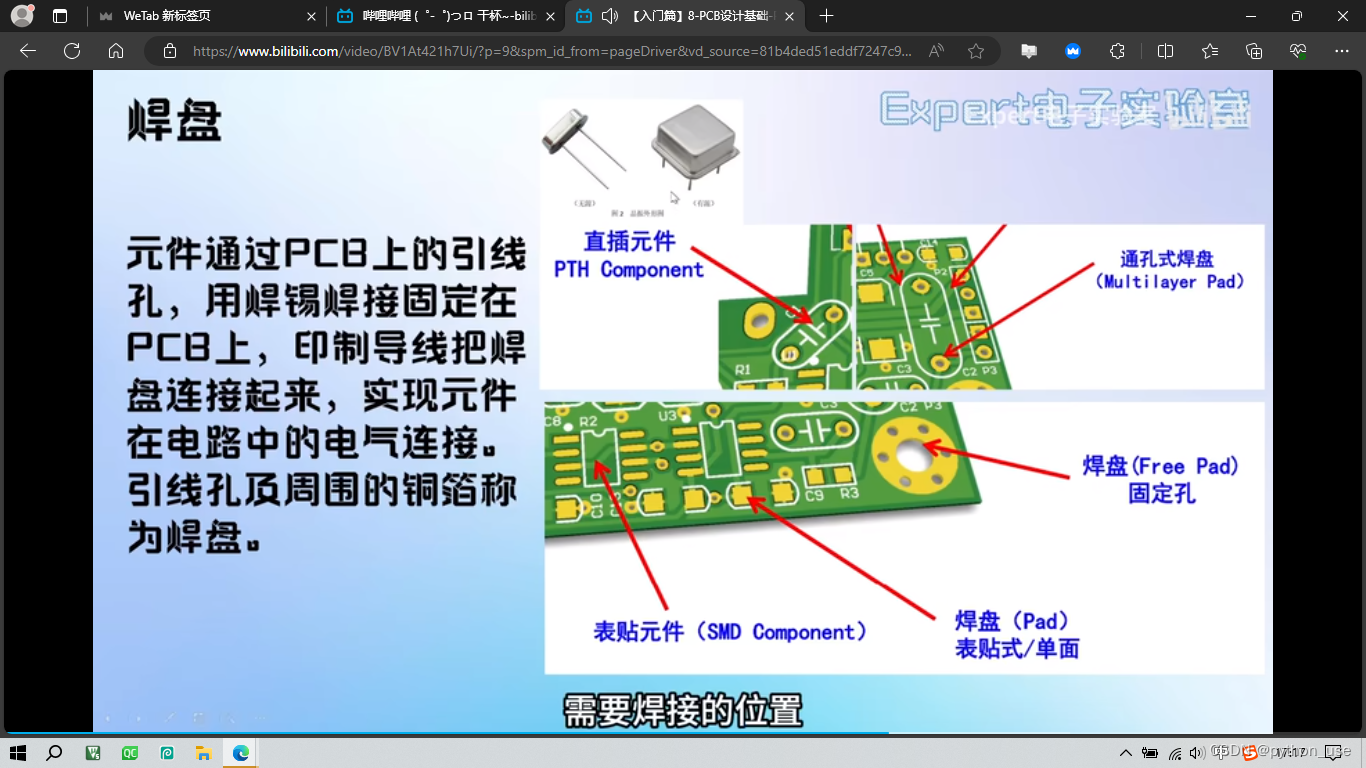
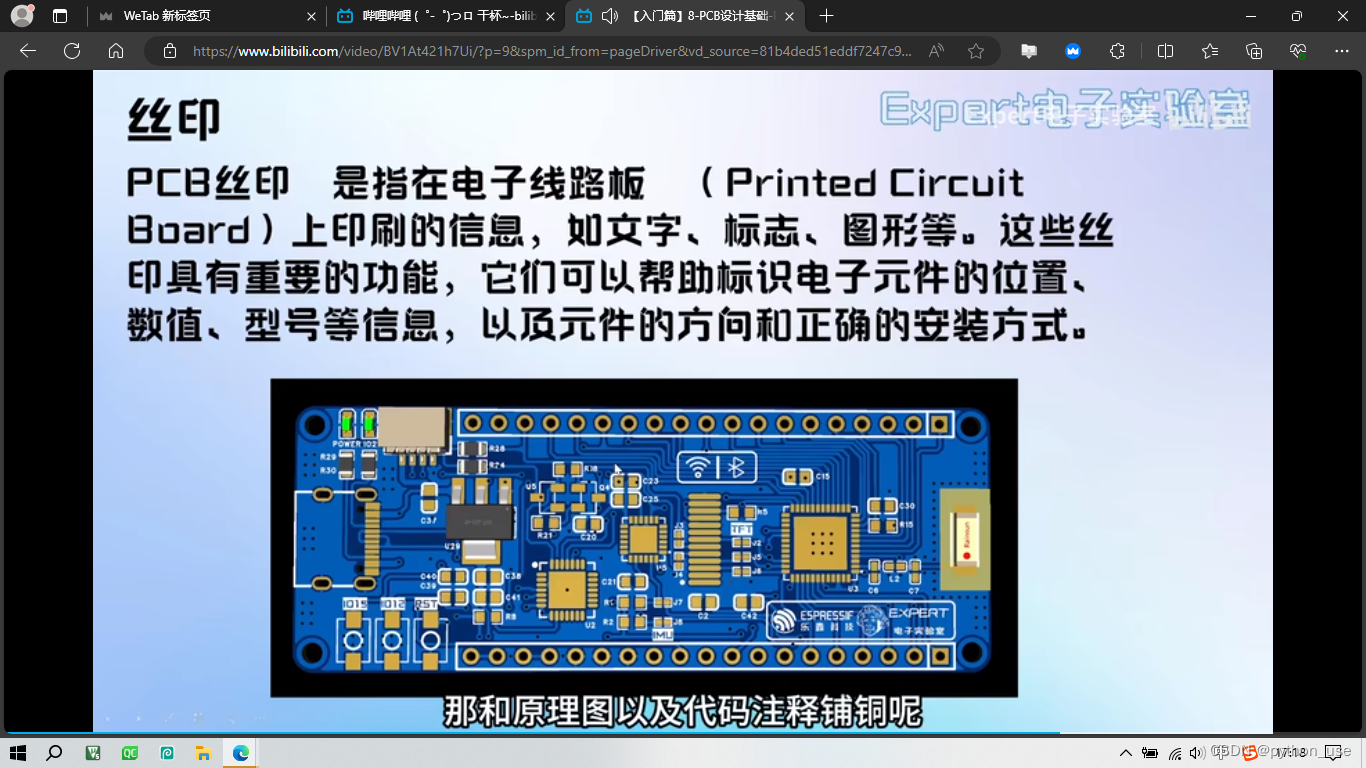
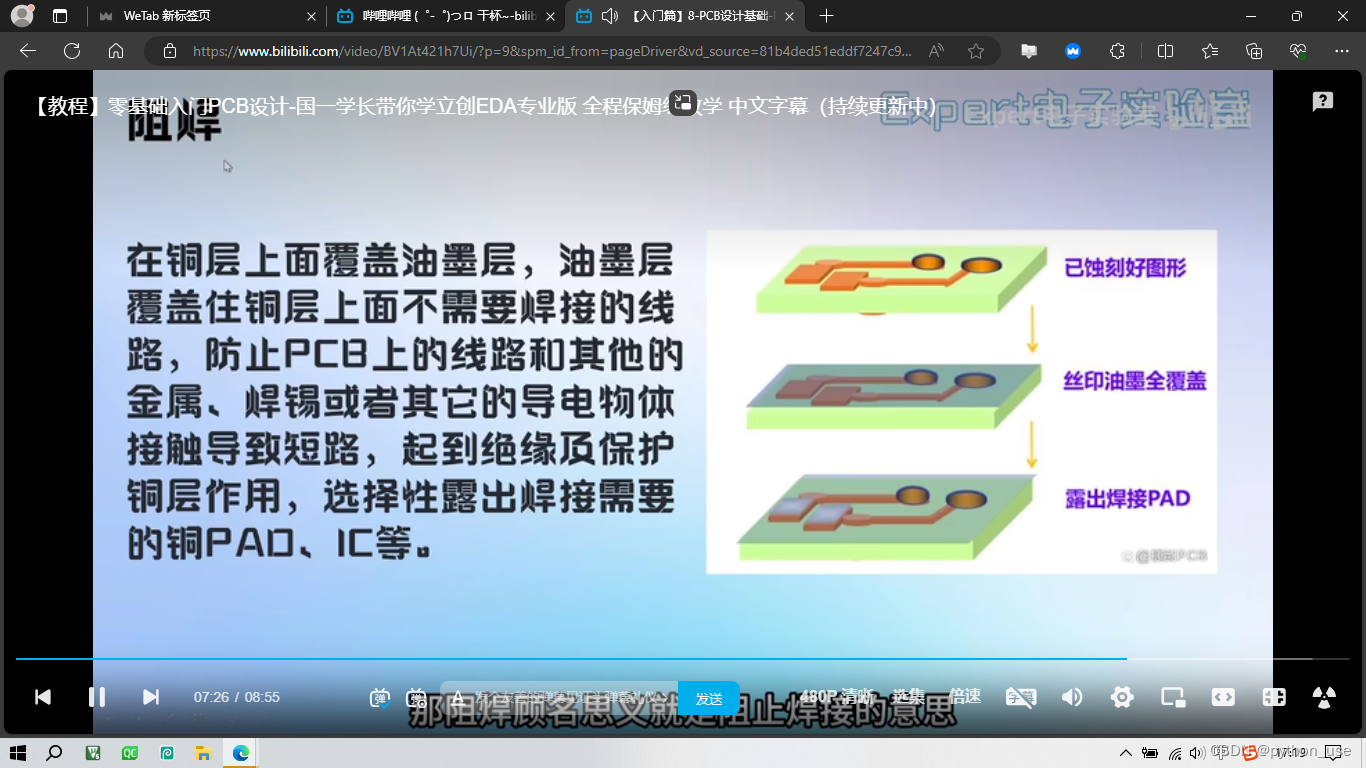
PCB图中红色阻焊外围有一圈紫色环绕,这表示的就是阻焊
五、层叠结构

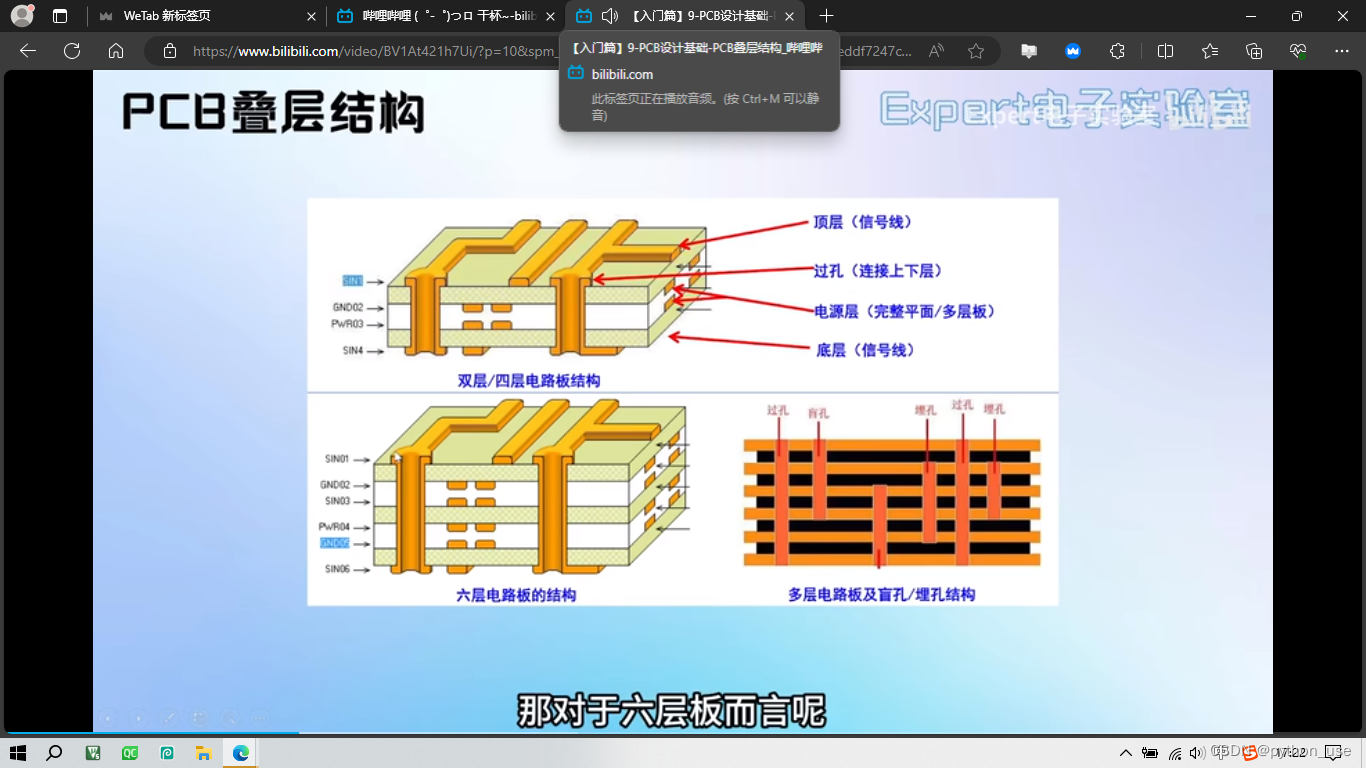
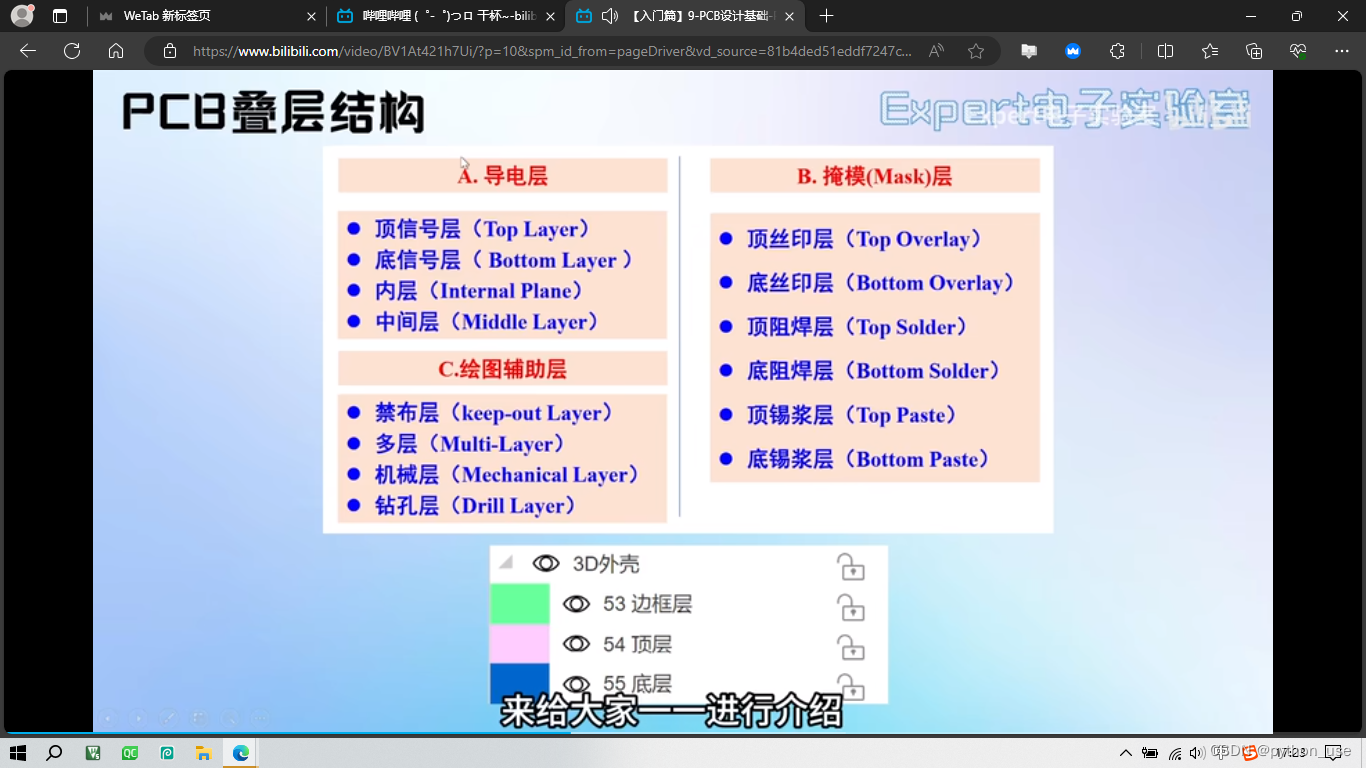



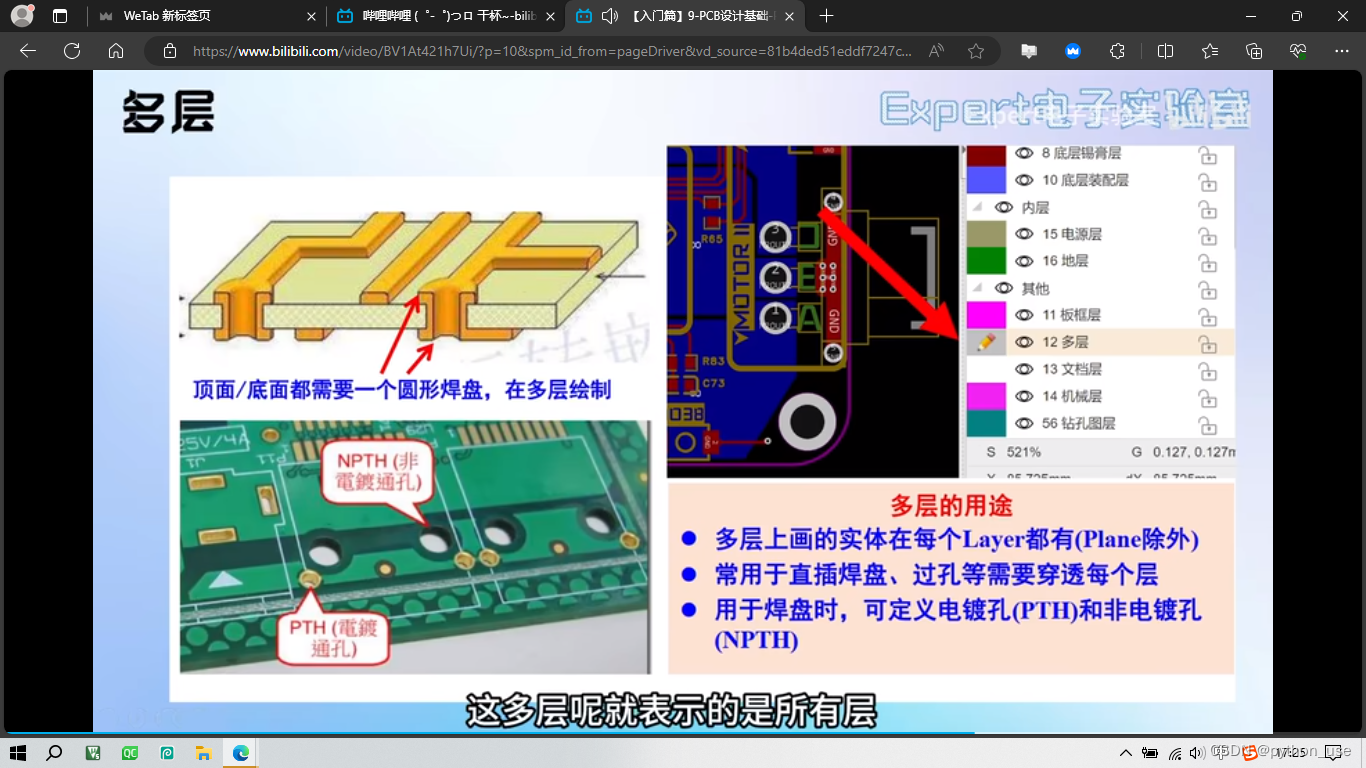

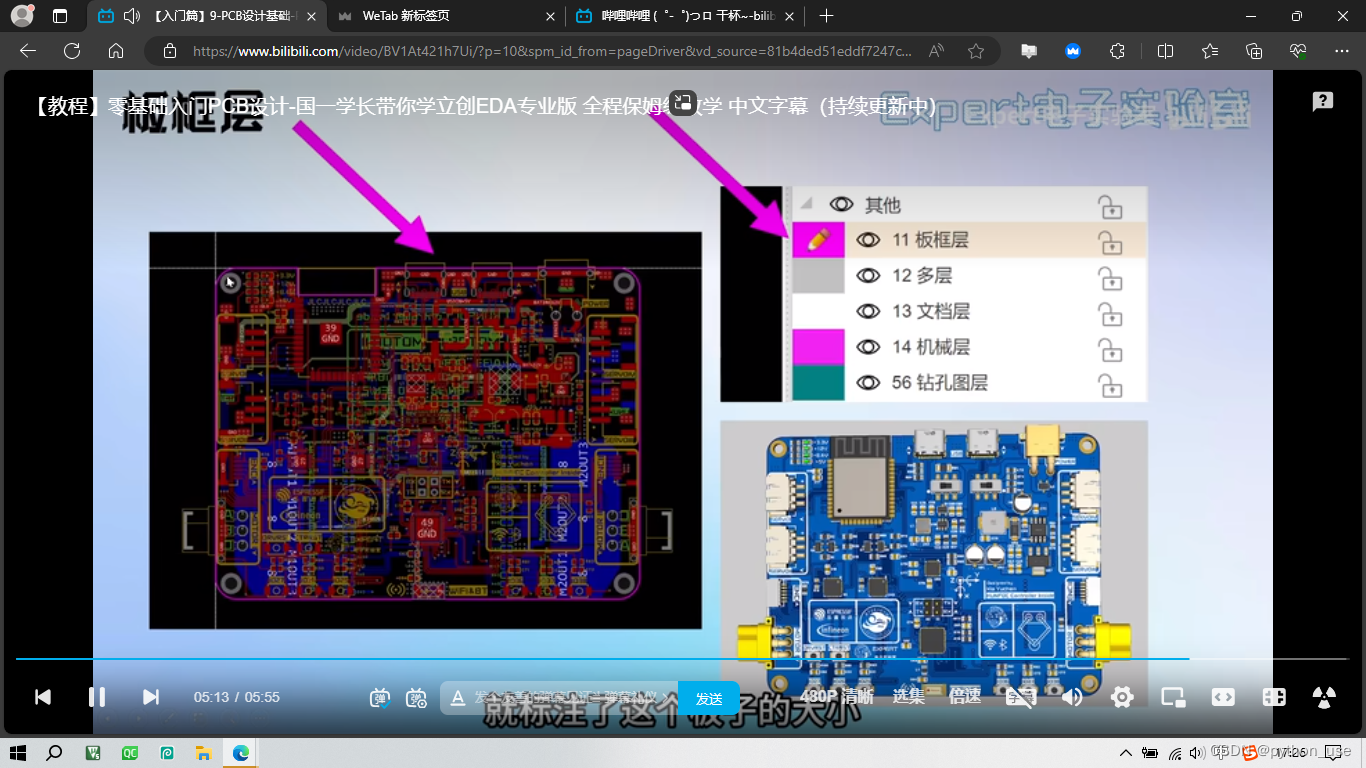
板框层确定了PCB板的大小
六、符号&封装
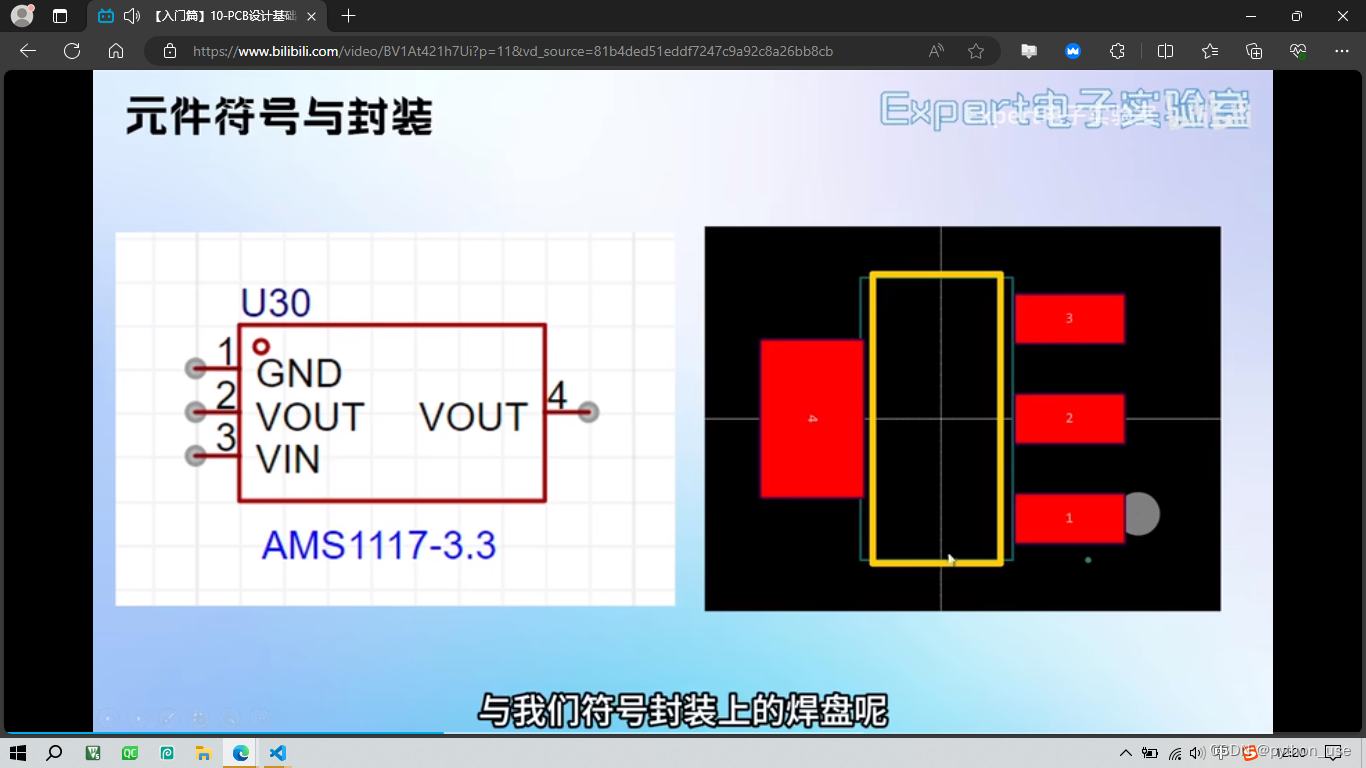
作图中灰色小圆点表示导线会与之相连,引脚编号与右侧焊盘上的标号是一一对应的
黄色的线框其实就是丝印
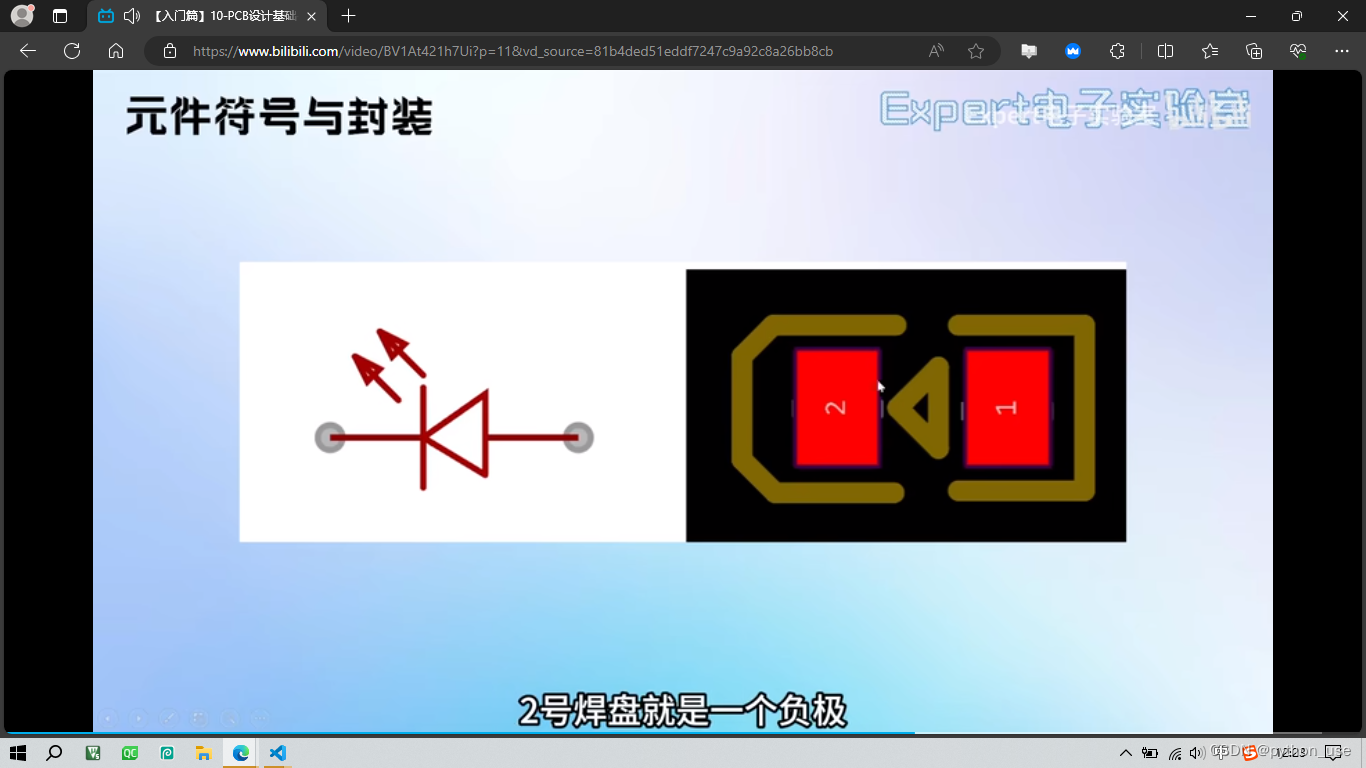


小圆点对应的引脚是1号引脚,芯片上也有类似标注,焊接时要注意对应
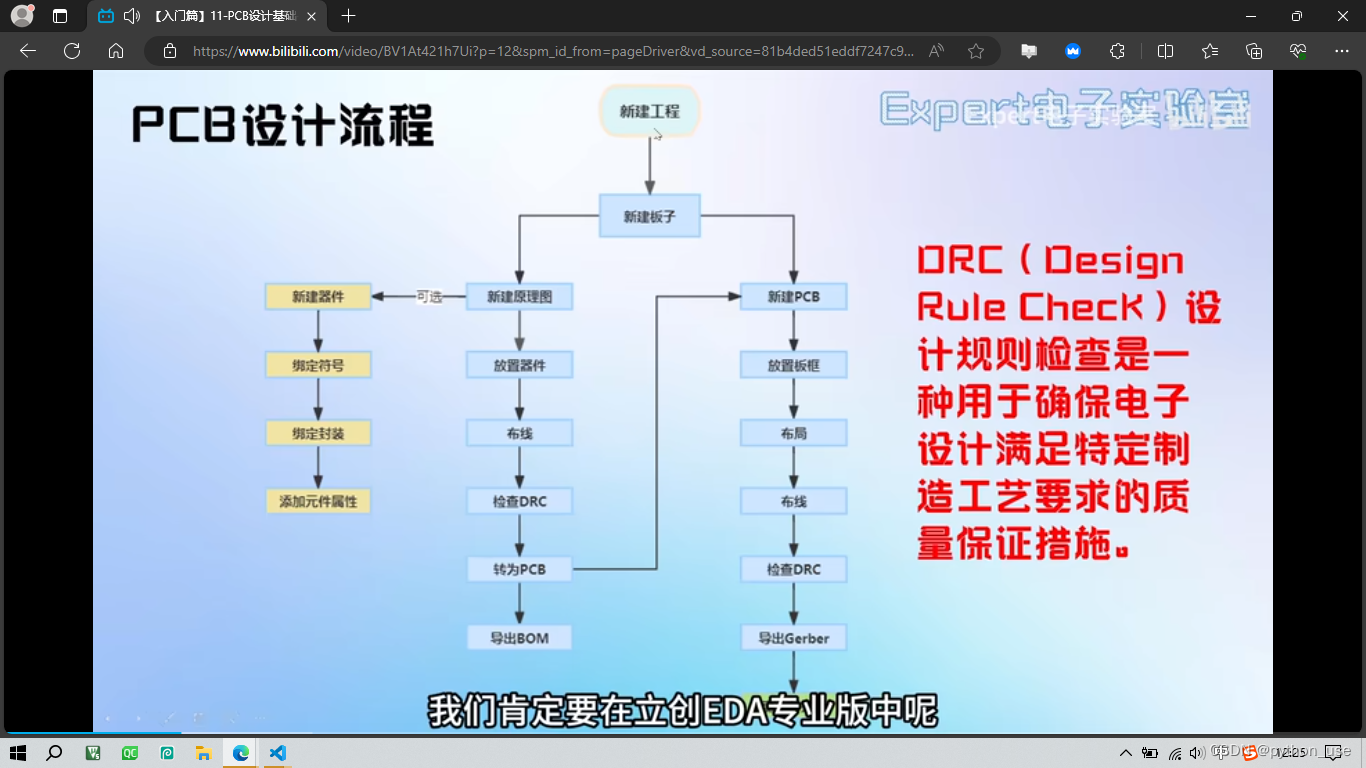
七、设计流程