合肥建设网站的公司360建筑网网址
基本概念
在支持多任务的操作系统中,修改一块内存区域的数据需要“读取-修改-写入”三个步骤。然而同一内存区域的数据可能同时被多个任务访问,如果在修改数据的过程中被其他任务打断,就会造成该操作的执行结果无法预知。
使用开关中断的方法固然可以保证多任务执行结果符合预期,但这种方法显然会影响系统性能。
ARMv6架构引入了LDREX和STREX指令,以支持对共享存储器更缜密的非阻塞同步。由此实现的原子操作能确保对同一数据的“读取-修改-写入”操作在它的执行期间不会被打断,即操作的原子性。
有多个任务对同一个内存数据进行加减或交换操作时,使用原子操作保证结果的可预知性。
看过自旋锁篇的应该对LDREX和STREX指令不陌生的,自旋锁的本质就是对某个变量的原子操作,而且一定要通过汇编代码实现,也就是说LDREX和STREX指令保证了原子操作的底层实现.
回顾下自旋锁申请和释放锁的汇编代码.
ArchSpinLock 申请锁代码
FUNCTION(ArchSpinLock) @死守,非要拿到锁mov r1, #1 @r1=11: @循环的作用,因SEV是广播事件.不一定lock->rawLock的值已经改变了ldrex r2, [r0] @r0 = &lock->rawLock, 即 r2 = lock->rawLockcmp r2, #0 @r2和0比较wfene @不相等时,说明资源被占用,CPU核进入睡眠状态strexeq r2, r1, [r0]@此时CPU被重新唤醒,尝试令lock->rawLock=1,成功写入则r2=0cmpeq r2, #0 @再来比较r2是否等于0,如果相等则获取到了锁bne 1b @如果不相等,继续进入循环dmb @用DMB指令来隔离,以保证缓冲中的数据已经落实到RAM中bx lr @此时是一定拿到锁了,跳回调用ArchSpinLock函数ArchSpinUnlock 释放锁代码
FUNCTION(ArchSpinUnlock) @释放锁mov r1, #0 @r1=0 dmb @数据存储隔离,以保证缓冲中的数据已经落实到RAM中str r1, [r0] @令lock->rawLock = 0dsb @数据同步隔离sev @给各CPU广播事件,唤醒沉睡的CPU们bx lr @跳回调用ArchSpinLock函数运作机制
鸿蒙通过对ARMv6架构中的LDREX和STREX进行封装,向用户提供了一套原子操作接口。
-
LDREX Rx, [Ry]
读取内存中的值,并标记对该段内存为独占访问:- 读取寄存器Ry指向的4字节内存数据,保存到Rx寄存器中。
- 对Ry指向的内存区域添加独占访问标记。
-
STREX Rf, Rx, [Ry]
检查内存是否有独占访问标记,如果有则更新内存值并清空标记,否则不更新内存:- 有独占访问标记
- 将寄存器Rx中的值更新到寄存器Ry指向的内存。
- 标志寄存器Rf置为0。
- 没有独占访问标记
- 不更新内存。
- 标志寄存器Rf置为1。
- 有独占访问标记
-
判断标志寄存器
标志寄存器为0时,退出循环,原子操作结束。
标志寄存器为1时,继续循环,重新进行原子操作。
功能列表
原子数据包含两种类型Atomic(有符号32位数)与 Atomic64(有符号64位数)。原子操作模块为用户提供下面几种功能,接口详细信息可以查看源码。

此处讲述 LOS_AtomicAdd , LOS_AtomicSub,LOS_AtomicRead,LOS_AtomicSet
理解了函数的汇编代码是理解的原子操作的关键.
LOS_AtomicAdd
//对内存数据做加法
STATIC INLINE INT32 LOS_AtomicAdd(Atomic *v, INT32 addVal)
{INT32 val;UINT32 status;do {__asm__ __volatile__("ldrex %1, [%2]\n""add %1, %1, %3\n" "strex %0, %1, [%2]": "=&r"(status), "=&r"(val): "r"(v), "r"(addVal): "cc");} while (__builtin_expect(status != 0, 0));return val;
}这是一段C语言内嵌汇编,逐一解读
-
- 先将
statusvalvaddVal的值交由通用寄存器(R0~R3)接管.
- 先将
-
- %2代表了入参v,[%2]代表的是参数v指向地址的值,也就是 *v ,函数要独占的就是它
-
- %0 ~ %3 对应
statusvalvaddVal
- %0 ~ %3 对应
-
- ldrex %1, [%2] 表示 val = *v ;
-
- add %1, %1, %3 表示 val = val + addVal;
-
- strex %0, %1, [%2] 表示 *v = val;
-
- status 表示是否更新成功,成功了置0,不成功则为 1
-
-
__builtin_expect是结束循环的判断语句,将最有可能执行的分支告诉编译器。
这个指令的写法为:__builtin_expect(EXP, N)。意思是:EXP==N 的概率很大。
综合理解__builtin_expect(status != 0, 0)
说的是status = 0 的可能性很大,不成功就会重新来一遍,直到strex更新成(status == 0)为止.
-
-
- “=&r”(val) 被修饰的操作符作为输出,即将寄存器的值回给val,val为函数的返回值
-
- "cc"向编译器声明以上信息.
LOS_AtomicSub
//对内存数据做减法
STATIC INLINE INT32 LOS_AtomicSub(Atomic *v, INT32 subVal)
{INT32 val;UINT32 status;do {__asm__ __volatile__("ldrex %1, [%2]\n""sub %1, %1, %3\n""strex %0, %1, [%2]": "=&r"(status), "=&r"(val): "r"(v), "r"(subVal): "cc");} while (__builtin_expect(status != 0, 0));return val;
}解读
- 同
LOS_AtomicAdd解读
volatile
这里要重点说下volatile,volatile 提醒编译器它后面所定义的变量随时都有可能改变,因此编译后的程序每次需要存储或读取这个变量的时候,都要直接从变量地址中读取数据。如果没有volatile关键字,则编译器可能优化读取和存储,可能暂时使用寄存器中的值,如果这个变量由别的程序更新了的话,将出现不一致的现象。
//读取内存数据
STATIC INLINE INT32 LOS_AtomicRead(const Atomic *v)
{return *(volatile INT32 *)v;
}
//写入内存数据
STATIC INLINE VOID LOS_AtomicSet(Atomic *v, INT32 setVal)
{*(volatile INT32 *)v = setVal;
}编程实例
调用原子操作相关接口,观察结果:
1.创建两个任务
- 任务一用LOS_AtomicAdd对全局变量加100次。
- 任务二用LOS_AtomicSub对全局变量减100次。
2.子任务结束后在主任务中打印全局变量的值。
#include "los_hwi.h"
#include "los_atomic.h"
#include "los_task.h"UINT32 g_testTaskId01;
UINT32 g_testTaskId02;
Atomic g_sum;
Atomic g_count;UINT32 Example_Atomic01(VOID)
{int i = 0;for(i = 0; i < 100; ++i) {LOS_AtomicAdd(&g_sum,1);}LOS_AtomicAdd(&g_count,1);return LOS_OK;
}UINT32 Example_Atomic02(VOID)
{int i = 0;for(i = 0; i < 100; ++i) {LOS_AtomicSub(&g_sum,1);}LOS_AtomicAdd(&g_count,1);return LOS_OK;
}UINT32 Example_TaskEntry(VOID)
{TSK_INIT_PARAM_S stTask1={0};stTask1.pfnTaskEntry = (TSK_ENTRY_FUNC)Example_Atomic01;stTask1.pcName = "TestAtomicTsk1";stTask1.uwStackSize = LOSCFG_BASE_CORE_TSK_DEFAULT_STACK_SIZE;stTask1.usTaskPrio = 4;stTask1.uwResved = LOS_TASK_STATUS_DETACHED;TSK_INIT_PARAM_S stTask2={0};stTask2.pfnTaskEntry = (TSK_ENTRY_FUNC)Example_Atomic02;stTask2.pcName = "TestAtomicTsk2";stTask2.uwStackSize = LOSCFG_BASE_CORE_TSK_DEFAULT_STACK_SIZE;stTask2.usTaskPrio = 4;stTask2.uwResved = LOS_TASK_STATUS_DETACHED;LOS_TaskLock();LOS_TaskCreate(&g_testTaskId01, &stTask1);LOS_TaskCreate(&g_testTaskId02, &stTask2);LOS_TaskUnlock();while(LOS_AtomicRead(&g_count) != 2);dprintf("g_sum = %d\n", g_sum);return LOS_OK;
}结果验证
g_sum = 0
经常有很多小伙伴抱怨说:不知道学习鸿蒙开发哪些技术?不知道需要重点掌握哪些鸿蒙应用开发知识点?
为了能够帮助到大家能够有规划的学习,这里特别整理了一套纯血版鸿蒙(HarmonyOS Next)全栈开发技术的学习路线,包含了鸿蒙开发必掌握的核心知识要点,内容有(ArkTS、ArkUI开发组件、Stage模型、多端部署、分布式应用开发、WebGL、元服务、OpenHarmony多媒体技术、Napi组件、OpenHarmony内核、OpenHarmony驱动开发、系统定制移植等等)鸿蒙(HarmonyOS NEXT)技术知识点。

《鸿蒙 (Harmony OS)开发学习手册》(共计892页)
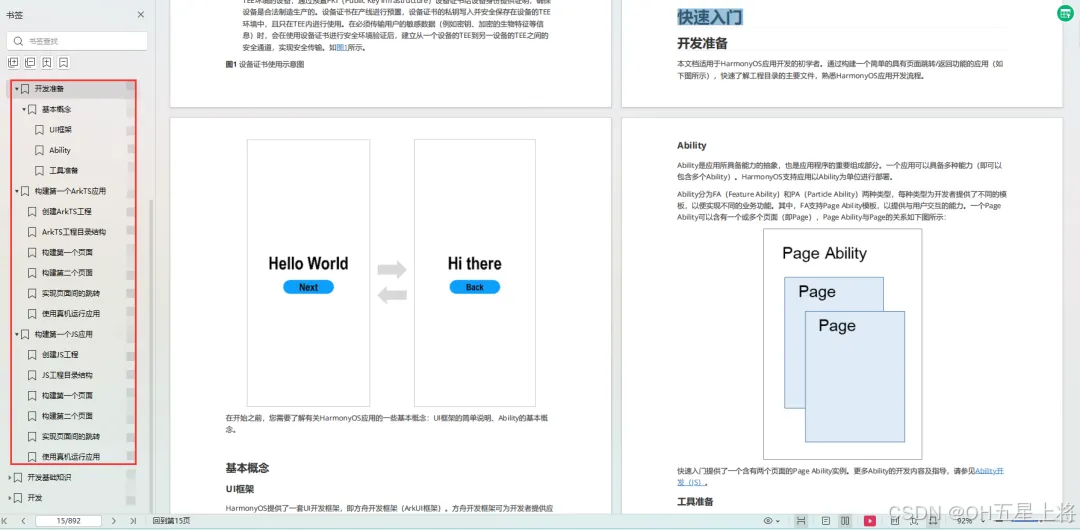
如何快速入门?
1.基本概念
2.构建第一个ArkTS应用
3.……
开发基础知识:
1.应用基础知识
2.配置文件
3.应用数据管理
4.应用安全管理
5.应用隐私保护
6.三方应用调用管控机制
7.资源分类与访问
8.学习ArkTS语言
9.……

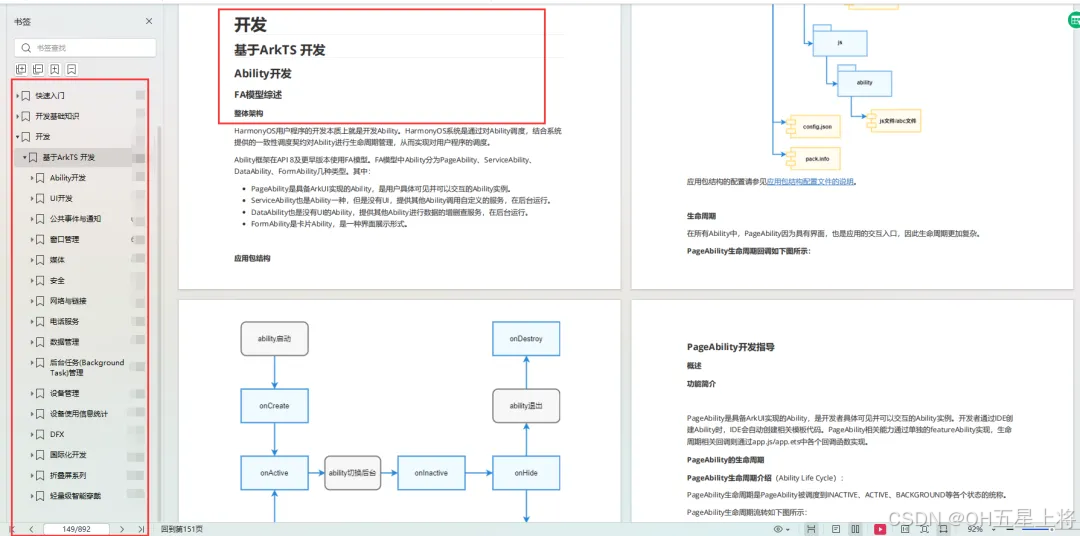
基于ArkTS 开发
1.Ability开发
2.UI开发
3.公共事件与通知
4.窗口管理
5.媒体
6.安全
7.网络与链接
8.电话服务
9.数据管理
10.后台任务(Background Task)管理
11.设备管理
12.设备使用信息统计
13.DFX
14.国际化开发
15.折叠屏系列
16.……
鸿蒙开发面试真题(含参考答案)
OpenHarmony 开发环境搭建
《OpenHarmony源码解析》
- 搭建开发环境
- Windows 开发环境的搭建
- Ubuntu 开发环境搭建
- Linux 与 Windows 之间的文件共享
- ……
- 系统架构分析
- 构建子系统
- 启动流程
- 子系统
- 分布式任务调度子系统
- 分布式通信子系统
- 驱动子系统
- ……

OpenHarmony 设备开发学习手册

写在最后
如果你觉得这篇内容对你还蛮有帮助,我想邀请你帮我三个小忙:
- 点赞,转发,有你们的 『点赞和评论』,才是我创造的动力。
- 关注小编,同时可以期待后续文章ing🚀,不定期分享原创知识。
- 想要获取更多完整鸿蒙最新学习资源,请移步前往
