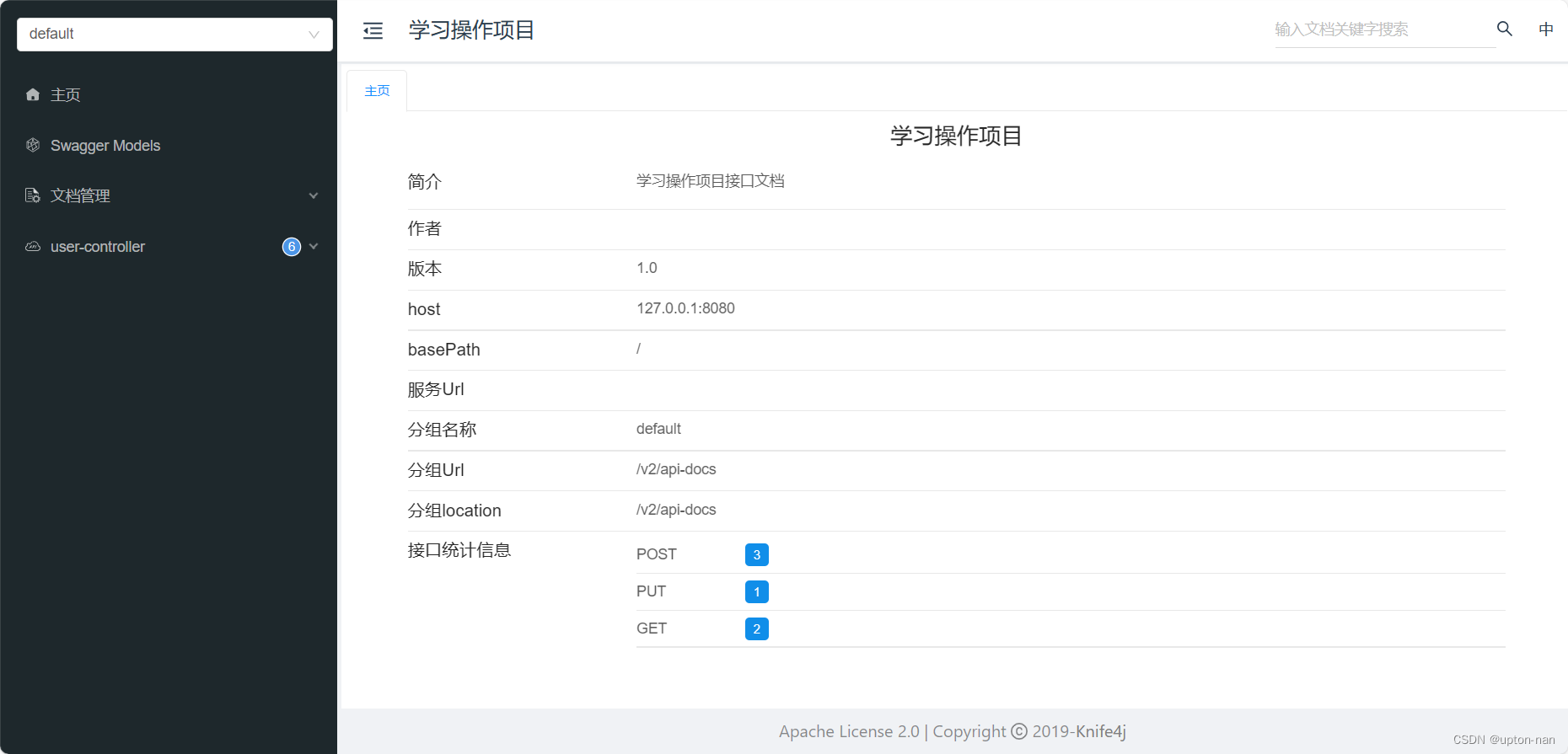
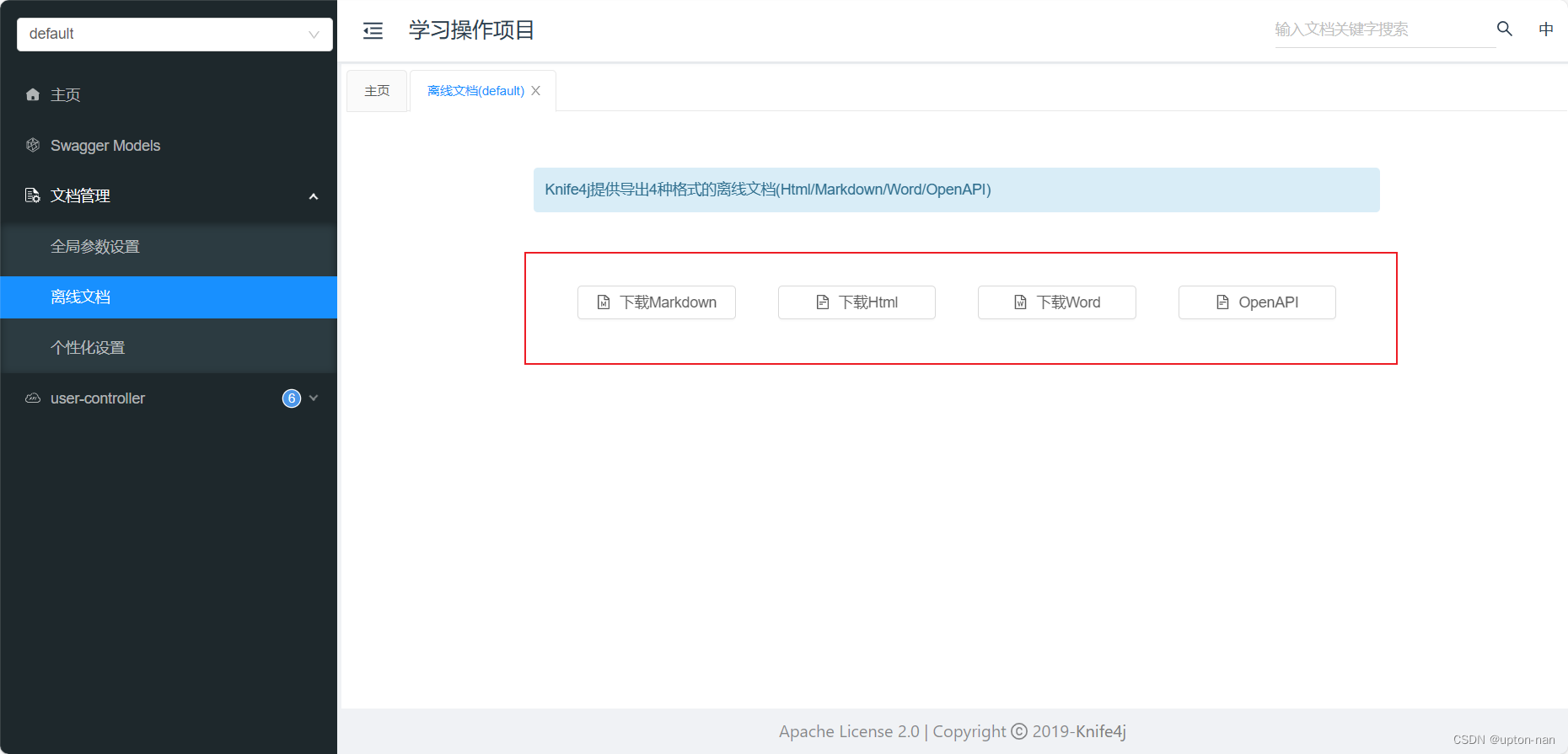
package com.app.studypro.config;import com.app.studypro.common.JacksonObjectMapper;
import com.github.xiaoymin.knife4j.spring.annotations.EnableKnife4j;
import lombok.extern.slf4j.Slf4j;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.http.converter.HttpMessageConverter;
import org.springframework.http.converter.json.MappingJackson2HttpMessageConverter;
import org.springframework.web.servlet.config.annotation.ResourceHandlerRegistry;
import org.springframework.web.servlet.config.annotation.WebMvcConfigurationSupport;
import springfox.documentation.builders.ApiInfoBuilder;
import springfox.documentation.builders.PathSelectors;
import springfox.documentation.builders.RequestHandlerSelectors;
import springfox.documentation.service.ApiInfo;
import springfox.documentation.spi.DocumentationType;
import springfox.documentation.spring.web.plugins.Docket;
import springfox.documentation.swagger2.annotations.EnableSwagger2;import java.util.List;/*** Spring mvc的配置设定** @author Administrator*/
@Slf4j
@Configuration
@EnableSwagger2
@EnableKnife4j
public class WebMvcConfig extends WebMvcConfigurationSupport {@Overrideprotected void extendMessageConverters(List<HttpMessageConverter<?>> converters) {log.info("扩展消息转换器,自定义添加 {} 消息转化器到spring mvc中", JacksonObjectMapper.class);// 创建消息转换器对象MappingJackson2HttpMessageConverter messageConverter = new MappingJackson2HttpMessageConverter();// 设置对象转换器,底层使用Jackson将Java对象转为jsonmessageConverter.setObjectMapper(new JacksonObjectMapper());// 将上面的消息转换器对象追加到mvc框架的转换器集合中,将其放在转换器集合的首个位置converters.add(0, messageConverter);}@Beanpublic Docket createRestApi() {// 创建api文档信息ApiInfo apiInfo = new ApiInfoBuilder()// 设置api文档标题.title("学习操作项目")// 设置api文档的版本.version("1.0")// 设置api文档的描述信息.description("学习操作项目接口文档").build();// 文档类型return new Docket(DocumentationType.SWAGGER_2).apiInfo(apiInfo).select()// Docket声明时,指定一个包扫描的路径,该路径指定的是Controller所在包的路径。// 因为Swagger在生成接口文档时,就是根据这里指定的包路径,自动的扫描该包下的@Controller,@RestController,@RequestMapping等SpringMVC的注解,依据这些注解来生成对应的接口文档.apis(RequestHandlerSelectors.basePackage("com.app.studypro.controller")).paths(PathSelectors.any()).build();}/*** 静态资源映射** @param registry 资源处理器*/@Overrideprotected void addResourceHandlers(ResourceHandlerRegistry registry) {log.info("开始进行静态资源映射...");// 添加Swagger生成的在线文档的相关静态资源映射registry.addResourceHandler("doc.html").addResourceLocations("classpath:/META-INF/resources/");registry.addResourceHandler("/webjars/**").addResourceLocations("classpath:/META-INF/resources/webjars/");}}