这是记录前端面试的话术集锦第八篇博文——高频考点(JS性能优化 & 性能优化琐碎事),我会不断更新该博文。❗❗❗
1. 从V8中看JS性能优化
注意:该知识点属于性能优化领域。
1.1 测试性能⼯具
Chrome已经提供了⼀个⼤⽽全的性能测试⼯具Audits。
点我们点击Audits后,可以看到如下的界⾯:
在这个界⾯中,我们可以选择想测试的功能然后点击Run audits,⼯具就会⾃动运⾏帮助我们测试问题并且给出⼀个完整的报告:
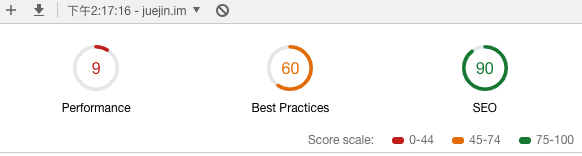
上图是给掘⾦⾸⻚测试性能后给出的⼀个报告,可以看到报告中分别为性能、 体验、SEO都给出了打分,并且每⼀个指标都有详细的评估。
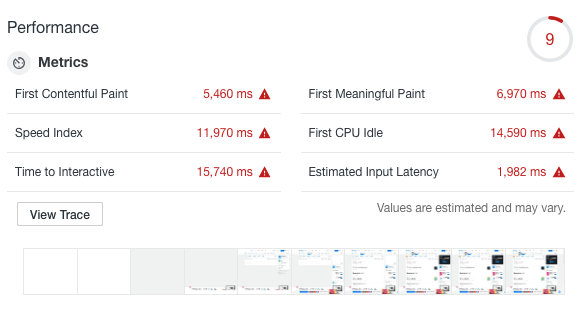
评估结束后&