自己制作网站的软件官方你网站建设策略
ArkTS基础知识
ArkUI开发框架
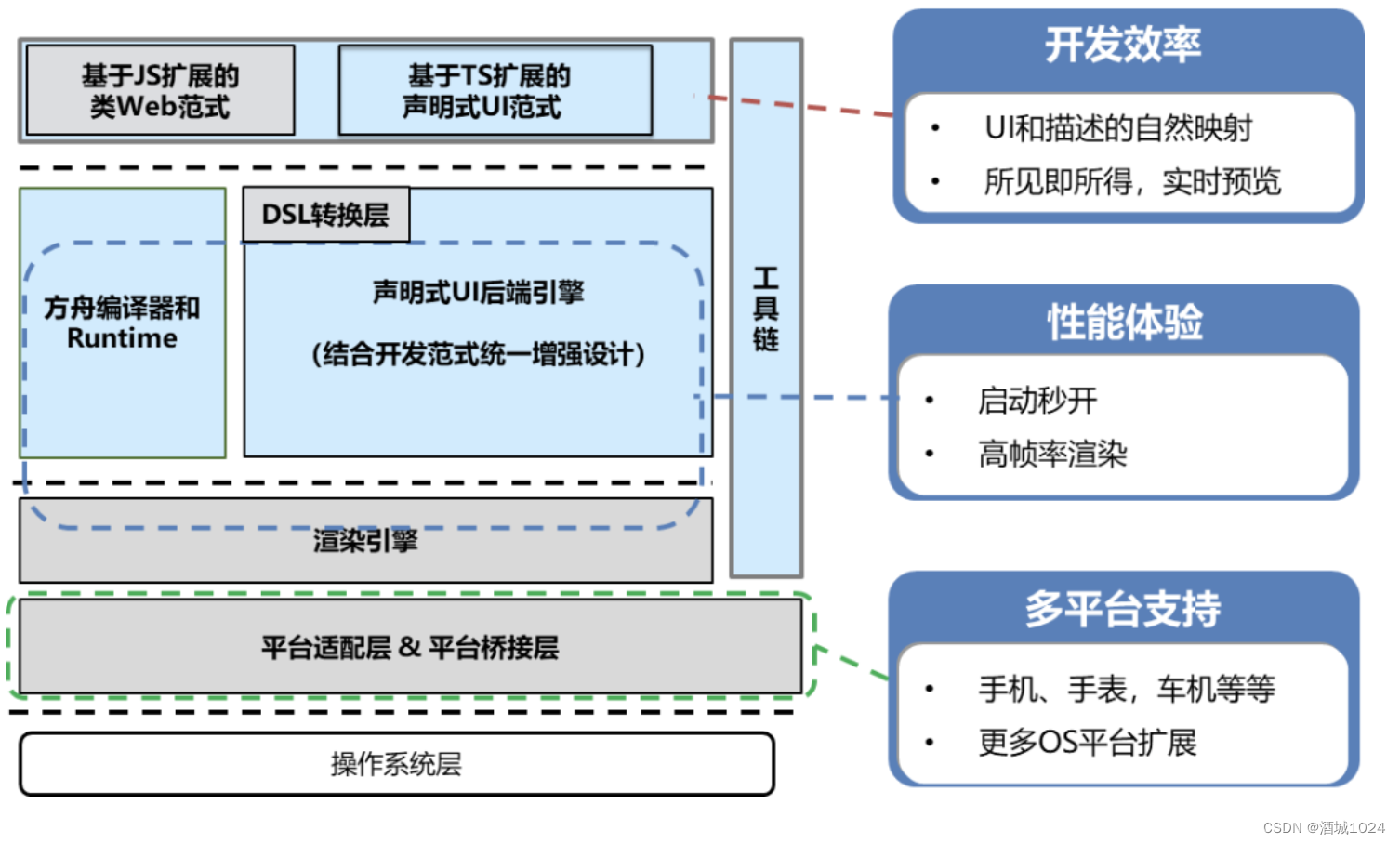
ArkTS声明式开发范式
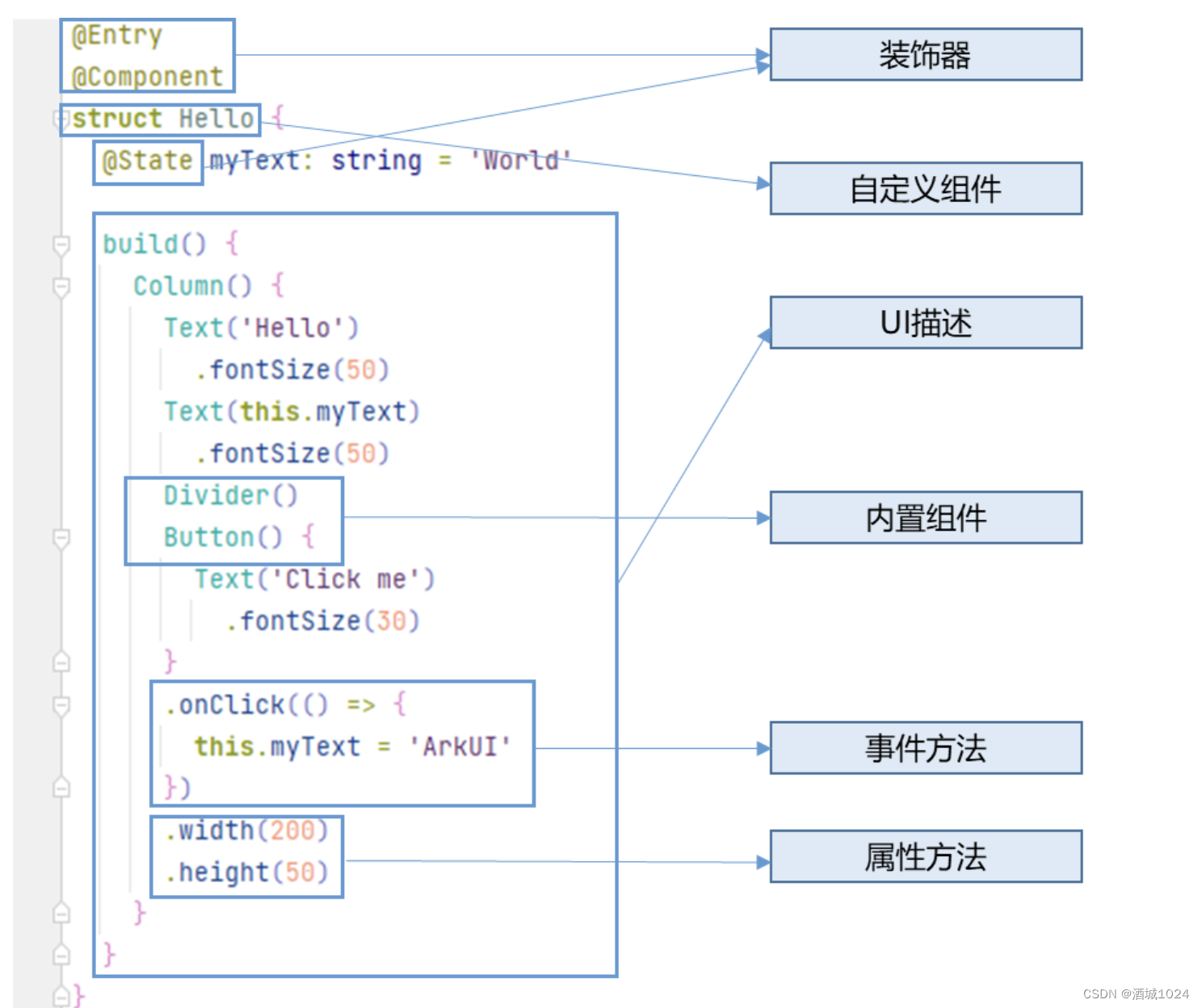
装饰器:
用来装饰类,结构体,方法及变量。如:
@Entry:入口组件
@Component :表示自定义组件
@State 都是装饰器:组件中的状态变量,该状态的变化回引起UI的变更
自定义组件:
@Component 就是可以复用的UI单元,可组合其他组件,如上述被 @Component 装饰的 struct Hello。
UI描述
声明式的方式来描述 UI 的结构,如上述 build() 方法内部的代码块。
内置组件
框架中默认内置的基础和布局组件,可直接被开发者调用,比如示例中的 Column、Text、Divider、Button。
事件方法:
用于添加组件对事件的响应逻辑,统一通过事件方法进行设置,如跟随在Button后面的onClick()。
属性方法:
用于组件属性的配置,统一通过属性方法进行设置,如fontSize()、width()、height()、color() 等,可通过链式调用的方式设置多项属性。
用 @State 装饰过的变量,包含了一个基础的状态管理机制,变量值的变化会自动触发相应的 UI 变更 ,ArkUI 中进一步提供了多维度的状态管理机制,和 UI 相关联的数据,不仅可以在组件内使用,还可以在不同组件层级间传递,比如父子组件之间,爷孙组件之间,也可以是全局范围内的传递,还可以是跨设备传递。另外,从数据的传递形式来看,可分为只读的单向传递和可变更的双向传递。开发者可以灵活的利用这些能力来实现数据和 UI 的联动。
ArkUI完整的开发范式可参考这里:
https://developer.harmonyos.com/cn/docs/documentation/doc-guides/arkui-overview-0000001281480754