营销型网站建设对比分析深圳网站网络推广公司
跨域是指访问另外一个域的资源,由于浏览器的同源策略,默认情况下使用 XMLHttpRequest 和 Fetch 请求时是不允许跨域的。跨域的根本原因是浏览器的同源策略,这是由浏览器对 JavaScript 施加的安全限制。
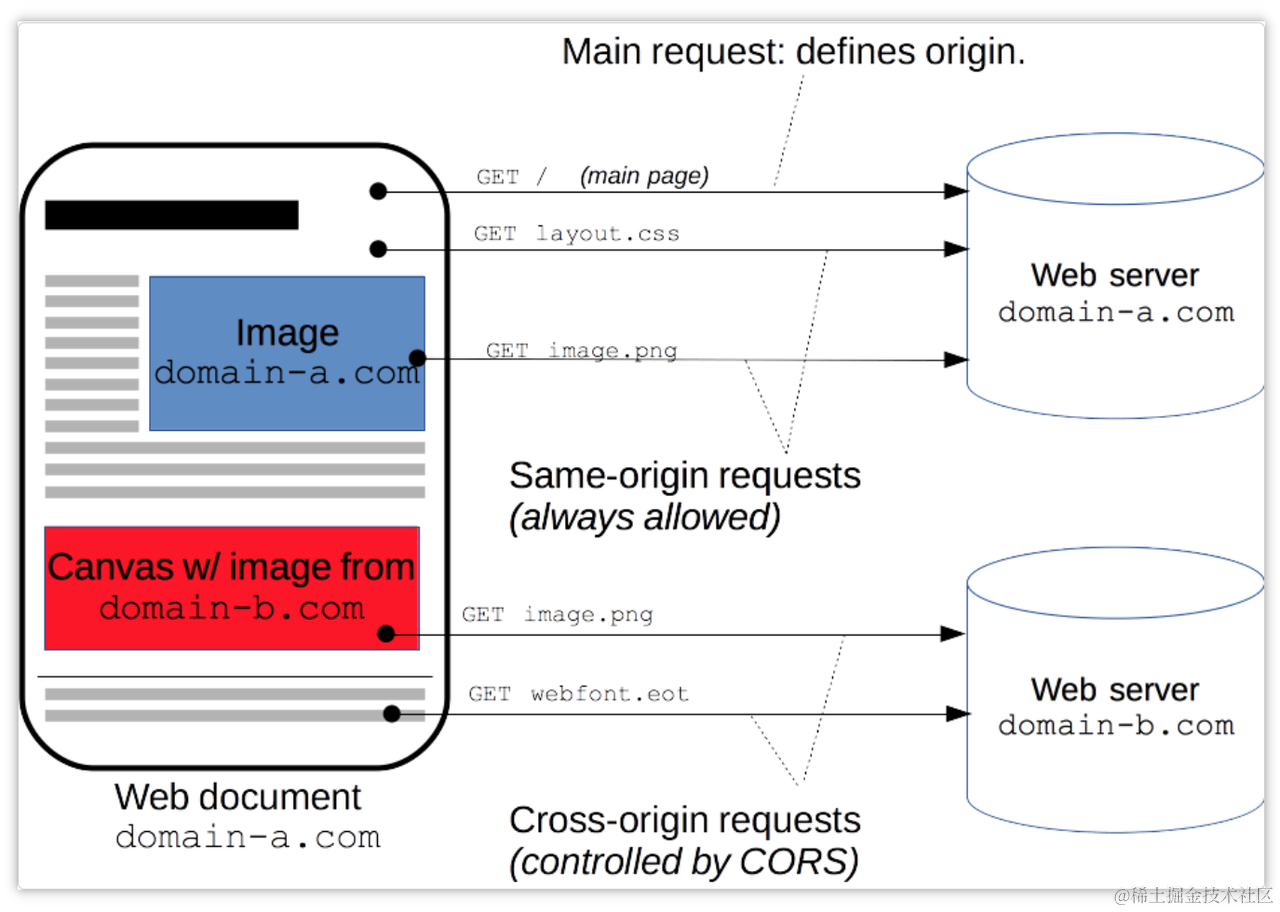
Axios 跨域常见报错
跨域请求被阻止 (Cross-Origin Request Blocked) :
这是由浏览器实施的同源策略导致的错误。浏览器在默认情况下不允许从一个源发送请求到另一个源,除非目标服务器明确授权。如果没有采取任何跨域解决方案,浏览器会拦截该请求,并报告此错误。
无法获取响应内容 (No 'Access-Control-Allow-Origin' header is present on the requested resource) :
当使用 CORS (跨域资源共享) 解决方案时,服务器需要在响应头中添加 Access-Control-Allow-Origin 头信息来指示允许访问资源的来源。如果服务器没有正确配置这个头信息或配置不正确,浏览器会报告此错误,表示未经授权无法获取响应内容。
请求出现网络错误 (Network Error) :
当跨域请求在发送时出现网络错误(例如目标服务器不可访问、请求超时等),Axios 会捕获这个错误,并将其报告为 "Network Error"。
预检请求失败 (Preflight request failed) :
当使用 CORS 发起一些复杂的请求(例如带有自定义头信息或使用 PUT、DELETE 等非简单请求类型),浏览器会在发送真实请求之前发送一个 OPTIONS 预检请求。如果服务器没有正确处理 OPTIONS 请求或未返回正确的预检响应头,浏览器会报告 "Preflight request failed" 错误。
代理服务器错误:
如果使用代理服务器作为解决方案,但代理服务器配置有误或不可用,Axios 可能会报告与代理服务器连接相关的错误。
Axios 跨域的解决方法

1. CORS
CORS 需要服务器设置 Access-Control-Allow-Origin 响应头,表示该资源可以被指定的域进行跨域访问。
// 服务端代码
res.setHeader('Access-Control-Allow-Origin', '*');
2. 服务端启用 CORS
比如 Node.js Express 启用 CORS:
const express = require('express')
const app = express()app.use(function (req, res, next) {// 启用 CORSres.header('Access-Control-Allow-Origin', '*');next();
})
3. JSONP
JSONP 的原理是动态插入
import axios from 'axios';axios.get('/api/user?callback=fetchUser');function fetchUser(user) {console.log(user);
}
服务端返回 JSON 数据并带上函数调用:
fetchUser({name: 'jack'
})
4. 代理服务器
在开发环境下,可以在本地启动一个代理服务器,实现跨域访问。在下面的例子中,客户端可以通过访问代理服务器的 /api/data 路由来获取目标服务器上的数据。
// Node.js 代理服务器
const express = require('express');
const axios = require('axios');
const app = express();
const port = 3000;app.use(express.json());app.get('/api/data', async (req, res) => {try {const response = await axios.get('https://目标服务器的URL/data');res.json(response.data);} catch (error) {res.status(500).json({ error: 'Failed to fetch data from the target server' });}
});app.listen(port, () => {console.log(`Proxy server is running on http://localhost:${port}`);
});Axios 跨域代码实例
假设存在一个需要跨域访问的 API:
axios.get('http://cross-domain-api.com/users')
可以在本地 3000 端口启动一个 Express 代理服务器:
const express = require('express');
const { createProxyMiddleware } = require('http-proxy-middleware');const app = express();app.use('/api', createProxyMiddleware({ target: 'http://cross-domain-api.com', // 跨域目标接口changeOrigin: true
}))app.listen(3000);
然后修改 axios 请求地址,指向代理服务器即可:
axios.get('http://localhost:3000/api/users')
## 提示与注意事项
- 选择跨域解决方案时,考虑到项目的复杂性和需求,选择最合适的方法。
- JSONP 只支持 GET 请求,不适用于所有场景。
- CORS 需要服务器端的支持,在一些旧版本的浏览器中可能不完全支持。
使用 Apifox 调试后端接口
Apifox = Postman + Swagger + Mock + JMeter,Apifox 支持调试 http(s)、WebSocket、Socket、gRPC、Dubbo 等协议的接口,并且集成了 IDEA 插件。在后端人员写完服务接口时,测试阶段可以通过 Apifox 来校验接口的正确性,图形化界面极大的方便了项目的上线效率。
总结
Axios 跨域常用的解决方法有 CORS、JSONP、代理等,开发环境可通过代理服务器实现跨域,CORS 需要服务端设置 Access-Control-Allow-Origin 响应头,JSONP 只支持 GET 请求。选择适合项目需求的解决方案能够很好地解决跨域问题,保障应用的正常运行。
知识扩展:
- FastAPI 与 Flask:Python Web 两大流行框架综合对比
- Axios 怎么通过 FormData 对象上传文件?
参考资料:
- MDN - 跨域资源共享CORS:跨源资源共享(CORS) - HTTP | MDN