新兴街做网站公司电商培训类网站模板
本章重点
为什么存在动态内存分配
动态内存函数的介绍
- malloc
- free
- calloc
- realloc
常见的动态内存错误
几个经典的笔试题
柔性数组
1. 为什么存在动态内存分配
我们已经掌握的内存开辟方式有:
int val = 20;//在栈空间上开辟四个字节
char arr[10] = {0};//在栈空间上开辟10个字节的连续空间但是上述的开辟空间的方式有两个特点:
- 空间开辟大小是固定的。
- 数组在申明的时候,必须指定数组的长度,它所需要的内存在编译时分配。
但是对于空间的需求,不仅仅是上述的情况。有时候我们需要的空间大小在程序运行的时候才能知道, 那数组的编译时开辟空间的方式就不能满足了,空间大小不容易设计合理。 这时候就只能试试动态存开辟了。
2. 动态内存函数的介绍
2.1 malloc和free
C语言提供了一个动态内存开辟的函数:
void* malloc (size_t size);
这个函数向内存申请一块连续可用的空间,并返回指向这块空间的指针。
- 如果开辟成功,则返回一个指向开辟好空间的指针。
- 如果开辟失败,则返回一个NULL指针,因此malloc的返回值一定要做检查。
- 返回值的类型是 void* ,所以malloc函数并不知道开辟空间的类型,具体在使用的时候使用者自己 来决定。
如果参数 size 为0,malloc的行为是标准是未定义的,取决于编译器。
malloc申请的内存空间,当程序退出时,还给操作系统,如果不退出,动态申请的内存不会主动释放,因此C语言提供了另外一个函数free,专门是用来做动态内存的释放和回收的,函数原型如下:
void free (void* ptr);
free函数用来释放动态开辟的内存。
- 如果参数 ptr 指向的空间不是动态开辟的,那free函数的行为是未定义的。
- 如果参数 ptr 是NULL指针,则函数什么事都不做。
malloc和free都声明在 stdlib.h 头文件中。
#include <stdio.h>
int main()
{//代码1int num = 0;scanf("%d", &num);int arr[num] = { 0 };//c90不支持这种写法,error//为了程序运行过程中开辟更合理的空间,需要动态开辟内存//代码2int* ptr = NULL;ptr = (int*)malloc(num * sizeof(int));if (NULL == ptr)//判断ptr指针是否为空{perrof("malloc");return 1;}int i = 0;for (i = 0; i < num; i++){*(ptr + i) = 0;printf("%d ", *(ptr + i));}free(ptr);//释放ptr所指向的动态内存ptr = NULL;//是否有必要?return 0;
}
运行结果:
结论:malloc申请空间后直接返回这块空间的起始位置,不会初始化空间
free释放ptr所指向的动态内存,ptr = NULL是否有必要呢?
2.2 calloc
C语言还提供了一个函数叫 calloc , calloc 函数也用来动态内存分配。原型如下:
void* calloc (size_t num, size_t size);
- 函数的功能是为 num 个大小为 size 的元素开辟一块空间,并且把空间的每个字节初始化为0。
- 与函数 malloc 的区别只在于 calloc 会在返回地址之前把申请的空间的每个字节初始化为全0。
#include <stdio.h>
#include <stdlib.h>
int main()
{int* p = (int*)calloc(10, sizeof(int));if (NULL == p)//判断p指针是否为空{perror("calloc");return 1;}int i = 0;for (i = 0; i < 10; i++){printf("%d ", *(p + i));}free(p);p = NULL;//p置为空指针return 0;
}运行结果:
所以如何我们对申请的内存空间的内容要求初始化,那么可以很方便的使用calloc函数来完成任务。
2.3 realloc
- realloc函数的出现让动态内存管理更加灵活。
- 有时会我们发现过去申请的空间太小了,有时候我们又会觉得申请的空间过大了,那为了合理的时候内存,我们一定会对内存的大小做灵活的调整。那 realloc 函数就可以做到对动态开辟内存大小 的调整。
void* realloc (void* ptr, size_t size);
- ptr 是要调整的内存地址
- size 调整之后新大小
- 返回值为调整之后的内存起始位置。
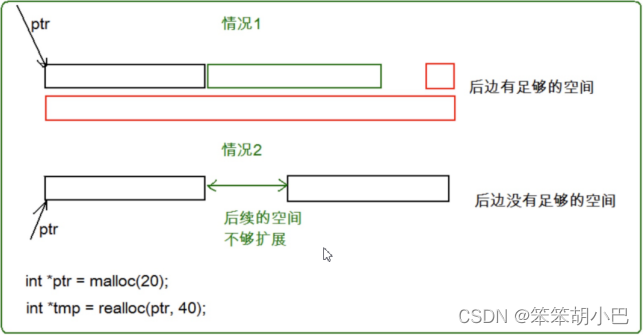
- 这个函数调整原内存空间大小的基础上,还会将原来内存中的数据移动到 新 的空间。 realloc在调整内存空间的是存在两种情况:
- 情况1:原有空间之后有足够大的空间
- 情况2:原有空间之后没有足够大的空间
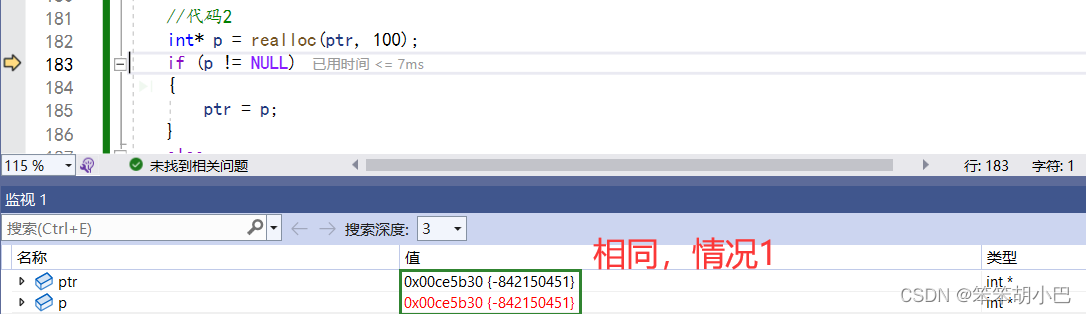
情况1
当是情况1 的时候,要扩展内存就直接原有内存之后直接追加空间,原来空间的数据不发生变化。返回的是原来旧的内存地址。
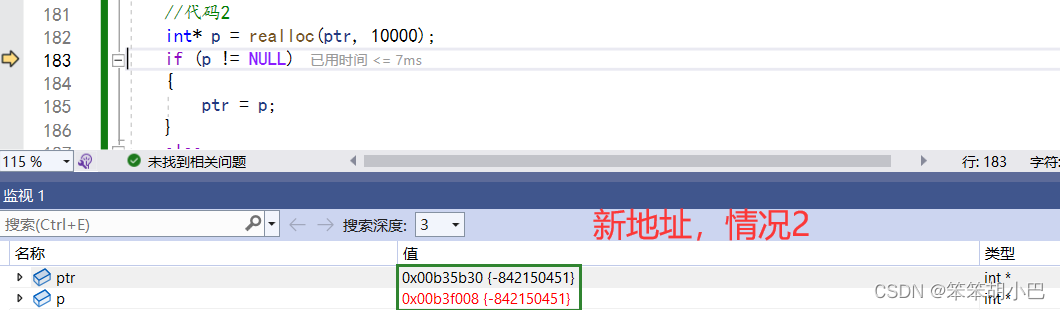
情况2
当是情况2 的时候,原有空间之后没有足够多的空间时,扩展的方法是:在堆空间上另开辟一个合适大小的连续空间来使用,把原来的数据拷贝到这个新的空间,再把旧的空间释放。这样函数返回的是一个新的内存地址。
#include <stdio.h>
#include <stdlib.h>
int main()
{int* ptr = (int*)malloc(10);if (ptr != NULL){//业务处理}else{perror("malloc");return 1;}//扩展容量//代码1ptr = (int*)realloc(ptr, 1000);//这样可以吗?(如果申请失败会如何?) - 内存泄露//代码2int* p = (int*)realloc(ptr, 1000);if (p != NULL){ptr = p;//赋值之后,realloc自己将ptr释放}else{perror("realloc");return 1;}//业务处理free(ptr);ptr = NULL;return 0;
}情况1:
情况2:
 3. 常见的动态内存错误
3. 常见的动态内存错误
3.1 对NULL指针的解引用操作
void test()
{int* p = (int*)malloc(INT_MAX / 4);//malloc函数开辟失败就会返回NULL*p = 20;//如果p的值是NULL,就会有问题free(p);
}3.2 对动态开辟空间的越界访问
void test()
{int i = 0;int* p = (int*)malloc(10 * sizeof(int));if (NULL == p){exit(EXIT_FAILURE);}for (i = 0; i <= 10; i++){*(p + i) = i;//当i是10的时候越界访问}free(p);
}3.3 对非动态开辟内存使用free释放
void test()
{int a = 10;int* p = &a;free(p);//ok?
}3.4 使用free释放一块动态开辟内存的一部分
void test()
{int* p = (int*)malloc(100);p++;free(p);//p不再指向动态内存的起始位置
}3.5 对同一块动态内存多次释放
void test()
{int* p = (int*)malloc(100);free(p);free(p);//重复释放
}3.6 动态开辟内存忘记释放(内存泄漏)
void test()
{int* p = (int*)malloc(100);if (NULL != p){*p = 20;}
}
int main()
{test();while (1);
}忘记释放不再使用的动态开辟的空间会造成内存泄漏。
切记:动态开辟的空间一定要释放,并且正确释放 。
4. 几个经典的笔试题
demo1:
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
void GetMemory(char* p)
{p = (char*)malloc(100);
}
void Test(void)
{char* str = NULL;GetMemory(str);strcpy(str, "hello world");printf(str);
}
int main()
{Test();return 0;
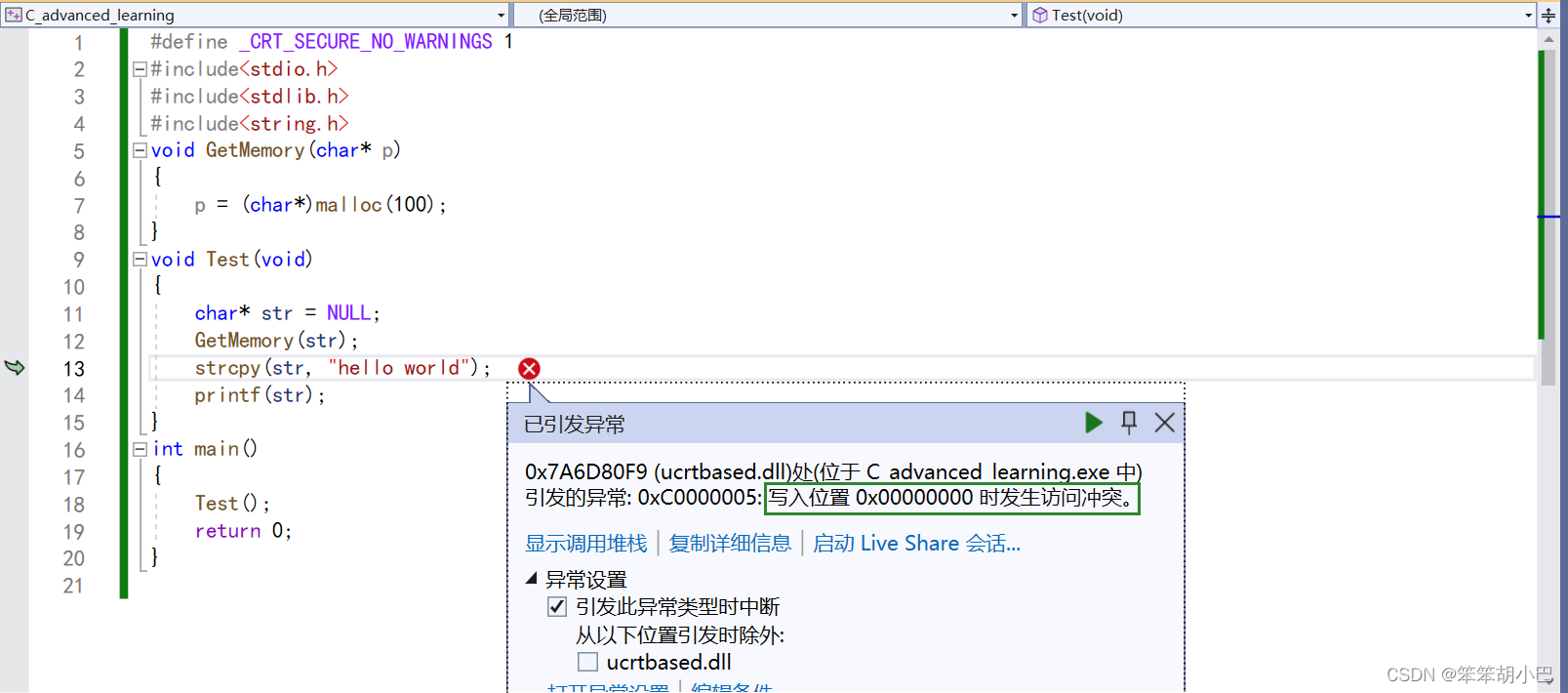
}问题:对NULL解引用以及没有释放malloc申请的空间
解释:
GetMemory函数: 这个函数接受一个字符指针(char*)作为参数,并尝试使用malloc来分配 100 字节的内存。然而,需要理解的是,在C语言中,函数参数是通过值传递的,这意味着GetMemory函数内部的p是从Test函数传递过来的指针的一个拷贝。对于拷贝的指针所做的更改不会影响Test函数中的原始指针。
Test函数: 在Test函数中,声明并初始化了一个char*变量str,并将其设置为NULL。然后,调用GetMemory函数,并将str作为参数传递进去。由于参数是通过值传递的,GetMemory函数只会修改它自己的指针拷贝,并不会改变Test函数中的原始str指针。内存分配问题: 在
GetMemory函数内部,内存被分配给局部指针p,这是从Test函数的str指针拷贝过来的。这意味着在Test函数中,原始的str指针仍然是NULL,并没有被赋予新分配的内存地址。缓冲区溢出: 在调用
GetMemory函数后,有一个strcpy函数调用,试图将字符串 "hello world" 复制到str指针中。然而,由于str仍然是NULL(没有指向已分配的内存),这将导致未定义行为,并可能导致段错误或其他错误,因为访问了无效的内存。
修改:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>void GetMemory(char** p)
{*p = (char*)malloc(100); // 分配 100 字节内存,并将地址存储在原始指针中
}void Test(void)
{char* str = NULL;GetMemory(&str); // 传递指向指针的指针(双重指针),以修改原始指针strcpy(str, "hello world");printf("%s", str);free(str); // 使用完内存后别忘了释放它str == NULL;
}int main()
{Test();return 0;
}
demo2:
#include<stdio.h>
char* GetMemory(void)
{char p[] = "hello world";return p;//返回局部变量的地址
}
void Test(void)
{char* str = NULL;str = GetMemory();printf(str);
}
int main()
{Test();return 0;
}问题:返回局部变量的地址
解释:
GetMemory函数: 这个函数声明了一个字符数组p并初始化为 "hello world"。然后它试图返回p的地址。但是,需要注意的是,p是一个局部变量,它在函数结束时会被销毁。因此,将局部变量的地址返回给调用者是不安全的,因为在调用者函数中访问返回的地址将指向无效的内存区域。
Test函数: 在Test函数中,声明了一个字符指针str并将其初始化为NULL。然后,调用GetMemory函数,将返回的地址赋值给str。错误的返回局部变量地址: 在
GetMemory函数中,由于返回局部变量p的地址,str指针现在指向了一个不再有效的内存地址,因为p在GetMemory函数返回后已经被销毁。
printf函数: 在printf中尝试打印str指向的字符串时,由于str指向无效内存地址,代码的行为将是未定义的。这可能导致程序崩溃、输出奇怪的字符或其他不确定的结果。
修改:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>char* GetMemory(void)
{char* p = (char*)malloc(12); // 在堆上分配内存以容纳 "hello world" 和空结束符strcpy(p, "hello world"); // 将 "hello world" 复制到新分配的内存块中return p; // 返回指向分配内存的指针
}void Test(void)
{char* str = NULL;str = GetMemory();printf("%s", str);free(str); // 使用完内存后别忘了释放它
}int main()
{Test();return 0;
}
demo3:
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
void GetMemory(char** p, int num)
{*p = (char*)malloc(num);
}
void Test(void)
{char* str = NULL;GetMemory(&str, 100);strcpy(str, "hello");printf(str);
}
int main()
{Test();return 0;
}问题:malloc申请的空间没有释放
修改:
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
void GetMemory(char** p, int num)
{*p = (char*)malloc(num);
}
void Test(void)
{char* str = NULL;GetMemory(&str, 100);strcpy(str, "hello");printf(str);free(str);str = NULL;
}
int main()
{Test();return 0;
}demo4:
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
void Test(void)
{char* str = (char*)malloc(100);strcpy(str, "hello");free(str);if (str != NULL){strcpy(str, "world");printf(str);}
}
int main()
{Test();return 0;
}
问题:
在这段C代码中,首先使用
malloc动态地分配了 100 字节的内存来存储字符串 "hello"。然后,立即使用strcpy将 "hello" 复制到分配的内存块中。接着,使用free释放了分配的内存。然后,代码尝试检查指针
str是否为NULL。然而,这是一个错误的做法。因为在调用free之后,指针str指向内存地址虽然不会发生改变,但是进行指针进行任何操作都是不安全的,并且会导致未定义的行为。
修改:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>void Test(void)
{char* str = (char*)malloc(100);strcpy(str, "hello");free(str); // 释放内存后,str 成为了悬挂指针str = NULL;// 不要在释放内存后使用指针// 这里不再使用 str 指针
}int main()
{Test();return 0;
}
5. C/C++程序的内存开辟
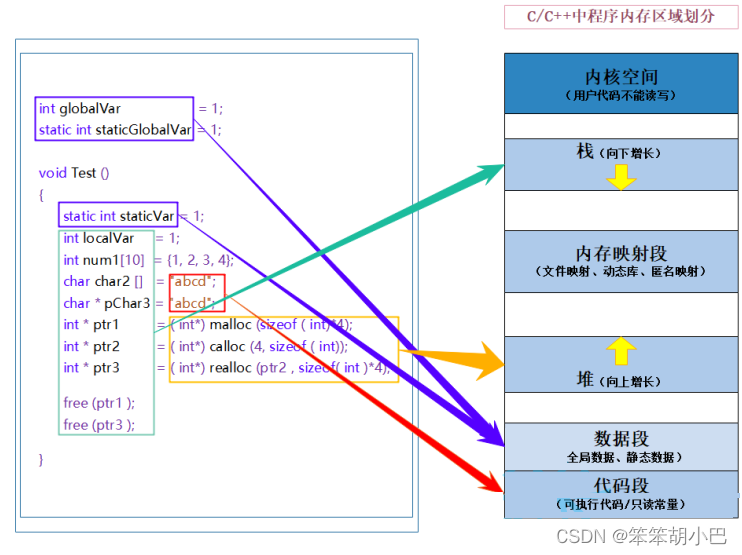 C/C++程序内存分配的几个区域:
C/C++程序内存分配的几个区域:
- 栈区(stack):在执行函数时,函数内局部变量的存储单元都可以在栈上创建,函数执行结 束时这些存储单元自动被释放。栈内存分配运算内置于处理器的指令集中,效率很高,但是 分配的内存容量有限。 栈区主要存放运行函数而分配的局部变量、函数参数、返回数据、返 回地址等。
- 堆区(heap):一般由程序员分配释放, 若程序员不释放,程序结束时可能由OS(操作系统)回收 。分 配方式类似于链表。
- 数据段(静态区)(static):存放全局变量、静态数据。程序结束后由系统释放。
- 代码段:存放函数体(类成员函数和全局函数)的二进制代码。
有了这幅图,我们就可以更好的理解在《C语言初识》中讲的static关键字修饰局部变量的例子了。
实际上普通的局部变量是在栈区分配空间的,栈区的特点是在上面创建的变量出了作用域就销毁。 但是被static修饰的变量存放在数据段(静态区),数据段的特点是在上面创建的变量,直到程序结束才销毁 所以生命周期变长。
6. 柔性数组
也许你从来没有听说过柔性数组(flexible array)这个概念,但是它确实是存在的。 C99 中,结构中的最后一个元素允许是未知大小的数组,这就叫做『柔性数组』成员。
typedef struct st_type
{int i;int a[];//柔性数组成员//int a[0];//也可以写成这个
}type_a;
6.1 柔性数组的特点:
- 结构中的柔性数组成员前面必须至少一个其他成员。
- sizeof 返回的这种结构大小不包括柔性数组的内存。
- 包含柔性数组成员的结构用malloc ()函数进行内存的动态分配,并且分配的内存应该大于结构的大小,以适应柔性数组的预期大小。
type_a* ps = (type_a*)malloc(sizeof(type_a) + 40);
6.2 柔性数组的使用
#include<stdio.h>
#include<stdlib.h>
typedef struct st_type
{int i;int a[0];//柔性数组成员
}type_a;
int main()
{type_a* ps = (type_a*)malloc(sizeof(type_a) + 40);if (!ps){perror("malloc");return 1;}ps->i = 10;int i = 0;for (i = 0; i < ps->i; i++){ps->a[i] = i;}//空间不够,realloc增容/*ps 是要调整的内存地址size 调整之后新大小返回值为调整之后的内存起始位置。*/type_a* p = (type_a*)realloc(ps, sizeof(type_a) + 60);if (!p){perror("realloc");return 1;}ps = p;ps->i = 15;for (i = 0; i < ps->i; i++){printf("%d ", ps->a[i]);}free(ps);ps = NULL;return 0;
}运行结果:
6.3 柔性数组的优势
上述的 type_a 结构也可以设计为指针类型:
#include<stdio.h>
#include<stdlib.h>
typedef struct st_type
{int i;int* a;
}type_a;
int main()
{type_a* ps = (type_a*)malloc(sizeof(type_a));//与柔性数组保持一致if (!ps){perror("malloc");return 1;}ps->i = 10;ps->a = (int*)malloc(40);if (!ps->a){perror("malloc");return 1;}int i = 0;for (i = 0; i < ps->i; i++){ps->a[i] = i;}//空间不够,realloc增容/*ps 是要调整的内存地址size 调整之后新大小返回值为调整之后的内存起始位置。*/int* p = (int*)realloc(ps->a, 60);if (!p){perror("realloc");return 1;}ps->a = p;ps->i = 15;for (i = 0; i < ps->i; i++){printf("%d ", ps->a[i]);}free(ps->a);ps->a = NULL;free(ps);ps = NULL;return 0;
}上述 代码1 和 代码2 可以完成同样的功能,但是 方法1 的实现有两个好处:
第一个好处是:方便内存释放
如果我们的代码是在一个给别人用的函数中,你在里面做了二次内存分配,并把整个结构体返回给用户。用户调用free可以释放结构体,但是用户并不知道这个结构体内的成员也需要free,所以你不能指望用户来发现这个事。所以,如果我们把结构体的内存以及其成员要的内存一次性分配好了,并返回给用户一个结构体指针,用户做一次free就可以把所有的内存也给释放掉。
第二个好处是:这样有利于访问速度.
连续的内存有益于提高访问速度,也有益于减少内存碎片。(其实,我个人觉得也没多高了,反正你跑不了要用做偏移量的加法来寻址)