做的好的营销型网站有哪些中铁建设集团华东分公司网站
在繁华喧嚣的城市里人来人往,井盖作为基础设施的一个组成部分在路面上分布范围广。然而这些看似普通的井盖却存在着位移、水浸的风险,可能给我们的生活带来诸多不便,更会威胁到我们的人身安全。如何有效监测和管理井盖的状态,成为政府部门亟待解决的问题。
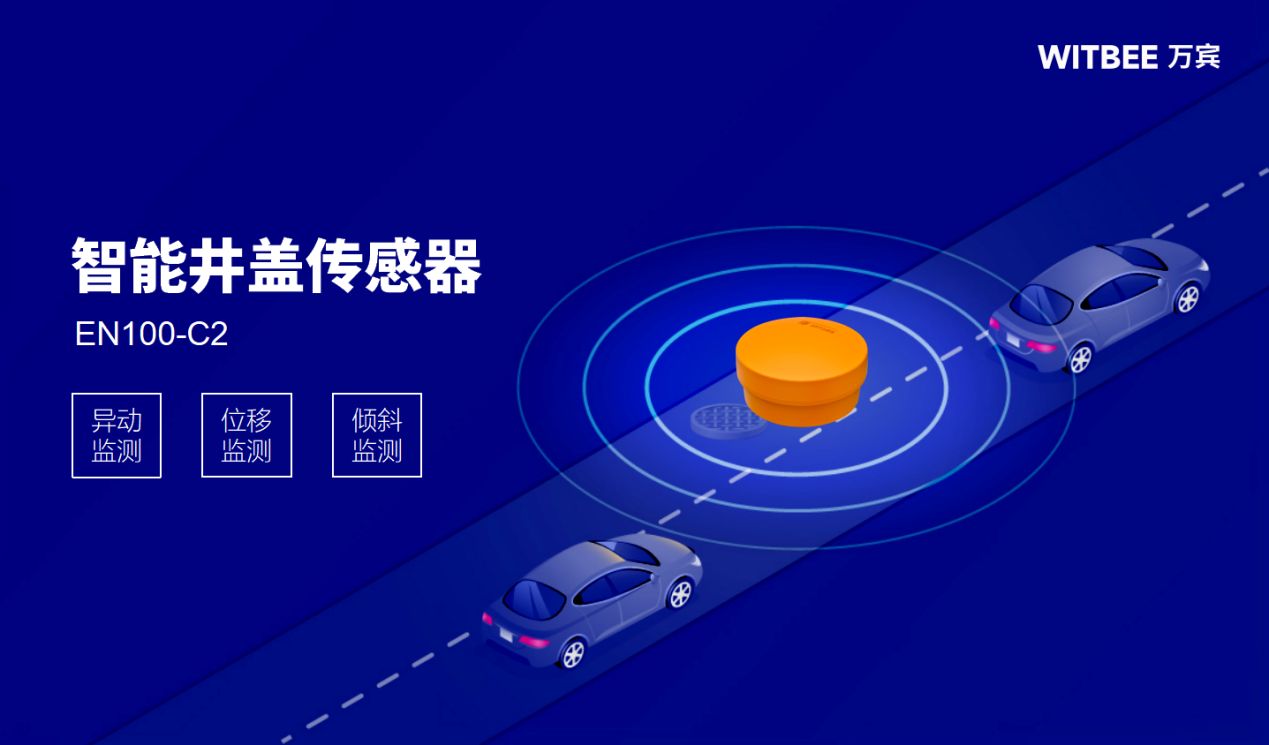
智能井盖位移监测系统依托先进的物联网技术,通过智能井盖传感器实时监测井盖的状态,及时发现异常情况并为城市的安全保驾护航。它还具有远程监测功能,让管理人员不需要离开办公室,便可以随时了解井盖的状态,为防止井盖突发情况提供更多的数据参考。智能井盖传感器达到IP68防护等级,安全性能良好且防水防尘耐腐蚀。尽管现在城市井盖材质不一,但是并不影响在井盖内壁安装智能井盖传感器,它对井盖材质丝毫不挑剔。应用这种智传感器可以为城市生命线提供保障,为城市的繁荣与安宁保驾护航。
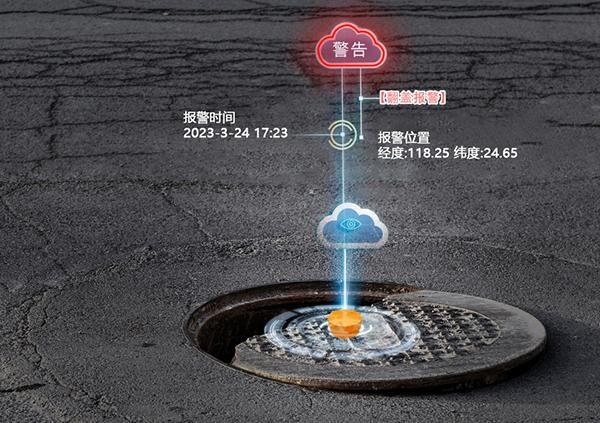
智能井盖位移监测系统可以帮助工作人员在后台了解井盖的数据,可以实时监测井盖的状况以免发生意外事故。当井盖发生位移时WITBEE®万宾®第四代智能井盖传感器EN100-C2会1s内极速反应,同时监测系统会立即收到报警信号。这使得管理人员能够及时掌握井盖的情况,并做好准备和采取相应的措施。七种震动过滤算法是智能井盖传感器的一大优势,对井下的复杂环境毫不畏惧,对可能误报的场景进行过滤,确保监测系统收到的数据更加精准且真实。智能井盖位移监测系统可以记录每个井盖的历史位置和状态数据。政府部门通过对这些数据的分析,可以得出井盖的数据变化规律,为城市规划和市政管理提供有价值的参考信息。
智能井盖传感器在防范城市道路安全问题上发挥着重要的作用,有效提升了城市的紧急应对能力。同时它们也为城市规划和可持续性提供了重要的支持,为减少事故和伤害起到了积极的贡献。