大航母网站建设案例网站建设管理实训报告
在数字时代,我们常常需要在各种文档、资料之间穿梭,然而,有时候我们需要的并不是数字版,而是纸质版。那么,在哪里打印资料比较便宜呢?
琢贝云打印以其超低的价格,优质的打印服务,赢得了广大用户的青睐。打印价格3分起每页,无论你需要打印多少资料,都可以在自己满意的预算内完成。而且,他们还提供快递邮寄服务,无论你在哪里,都能享受到快递送货上门的服务。
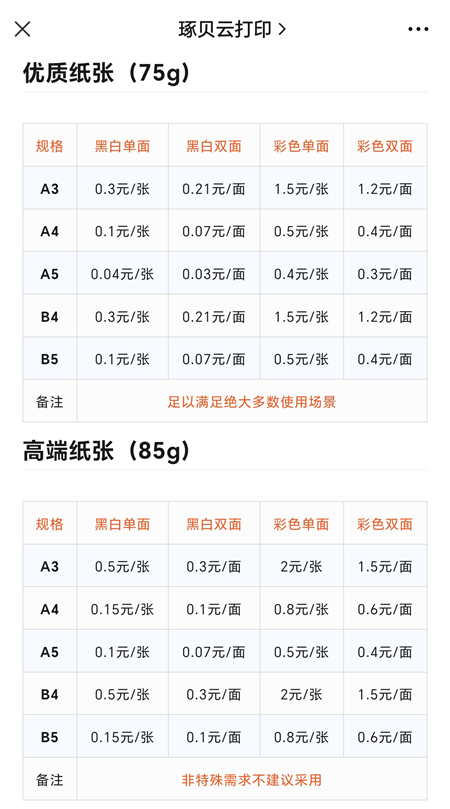
同时,经过小编个人了解得知:满10元还可以参与活动包邮到家。
琢贝云打印采用的是先进的激光打印技术,确保了打印出的文字清晰、颜色鲜明,无论是学术论文、简历、还是照片,都能以高质量呈现。而且,激光打印的耐用性也让你无需担心打印的资料会因为时间的流逝而褪色。

在纸张上,采用的是75克优质纸张,可能很多小伙伴并未关心过纸张的参数,但是一般情况下打印店均采用70克的普通纸张。另外,在琢贝云打印在线打印平台打印文件资料,支持通过电脑网页和手机微信、QQ小程序线上下单。
以微信为例,你只需在微信中搜索“琢贝云打印”,进入小程序后上传你需要打印的文件,选择你的打印要求,系统会自动计算出价格,然后你就可以选择支付方式进行支付。支付完成后,你只需等待快递送货上门即可。
总的来说,“琢贝云打印”微信小程序是一个实惠、便捷的打印解决方案。如果你需要大量打印资料,或者需要高质量的打印服务,琢贝云打印都是一个值得考虑的选择。下次你需要打印资料时,不妨试试琢贝云打印,相信你一定会被它的价格和服务所吸引。