懒人模板网站网站建设管理要求
1、benos_payload.bin结构分析
韦东山老师提供的开发文档里已经对程序的结构做了分析,这里不再赘述,下面是讨论mysbi跳转到benos的问题;
2、mysbi跳转到benos的代码

3、跳转产生的疑问
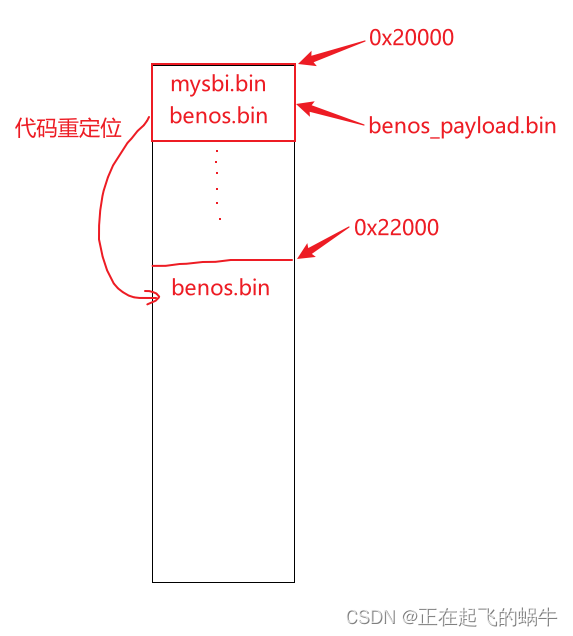
我认为mysbi.bin最后跳转到0x22000地址处执行,此时benos.bin代码不在0x22000地址处,需要代码重定位,但是在mysbi.bin的源文件中并没有进行代码重定位;
4、实际的程序加载内存布局
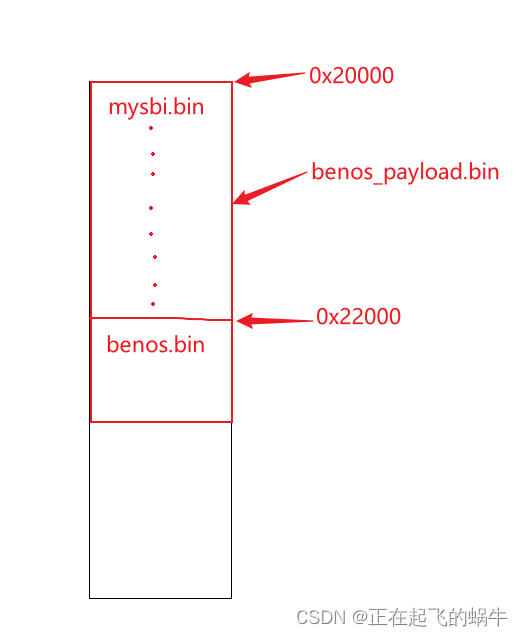
(1)产生疑问的原因:错误的认为benos_payload.bin是紧凑排布的,实际上根据链接脚本,在生成bin文件时已经考虑了偏移量,中间部分被用0填充,可以使用二进制查看软件分析benos_payload.bin,能看到文件0x2000偏移处正好是benos.bin;
(2)结论:将benos_payload.bin加载在IRAM中后,0x22000地址处已经是benos.bin,所以不需要代码重定位;