社交网站开发语言雅虎搜索
文章目录
- 如何打造自己的大模型
- 1 新时代职场人应用AIGC的5重境界
- 2 人人需要掌握的大模型原理
- 职场人都能听懂的大语音模型的训练过程
- 职场人都能听得懂的大语言模型的Transformer推理过程
- 3 如何构建自己的大模型
- 需要具备三个方面的能力
- LangChain是什么?
- LangChain主要功能
- LangChain核心组成
如何打造自己的大模型
1 新时代职场人应用AIGC的5重境界
- 第一、简单对话 + Ctrl-C/V 结果:人人都行
- 第二、Prompt Engineering:系统掌握 Prompt 提示词技能,赋能工作真正提效
- 第三、把AIGC融入业务流程,指挥AIGC做复杂任务:掌握好 AIGC 技能、真正懂业务领域知识
- 第四、拥有自己的大模型:懂大模型原理、基于开源大模型微调(Fine-tune)、有行业数据壁垒
- 第五、参与设计训练大模型:OpenAI等大模型公司
思考:自己处于哪种境界?
2 人人需要掌握的大模型原理
职场人都能听懂的大语音模型的训练过程
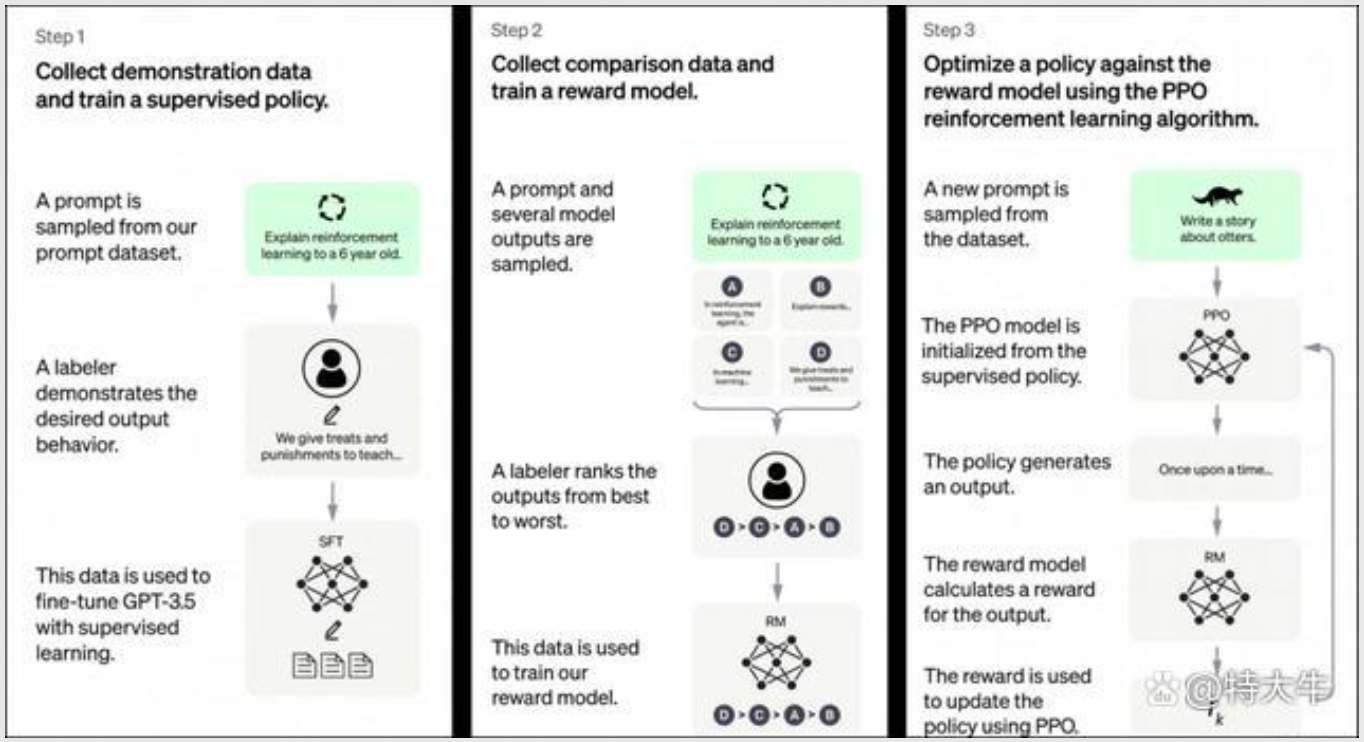
- 第一阶段:传统的有监督训练
- 第二阶段:奖励模型
- 第三阶段:运用奖励模型,一问一回答一打分,不断进行反馈迭代强化学习
职场人都能听得懂的大语言模型的Transformer推理过程
- Transformer:在 Transformer 之前,最大的问题就是遗忘(记不住上下文信息)
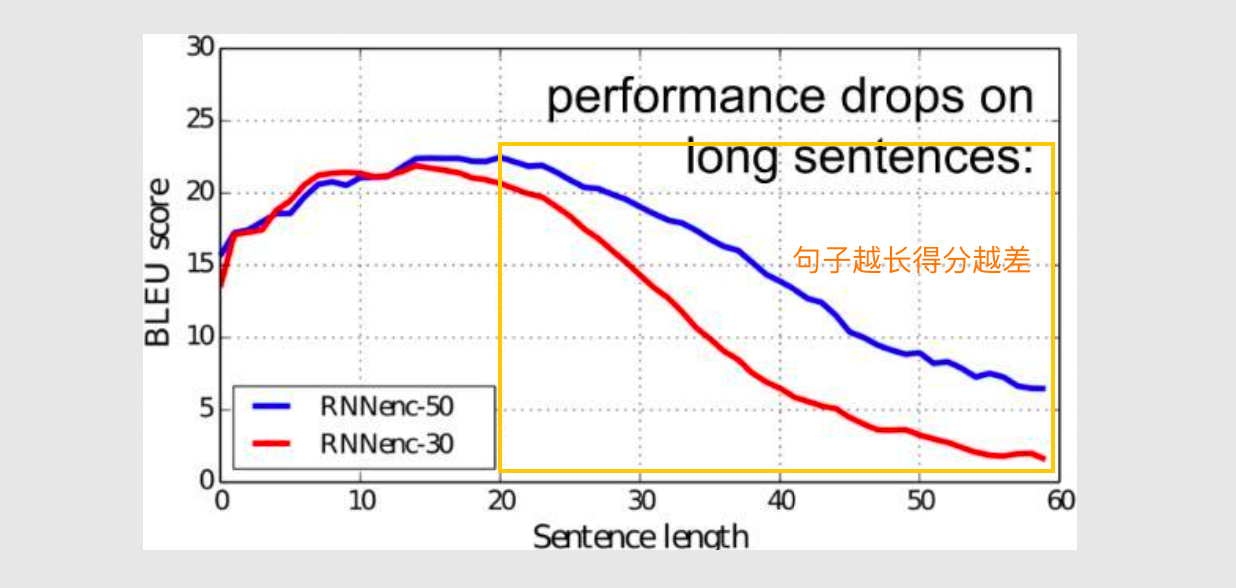
- Transformer:通过**注意力机制(Attention)**解决遗忘问题
- The:第一个,前面没有关联
- FBI:前面会关联 The
- is:前面会关联 FBI
- chasing:前面会关联 FBI、is
- …

- Transformer:整个流程设计(大模型的核心)——2017年提出
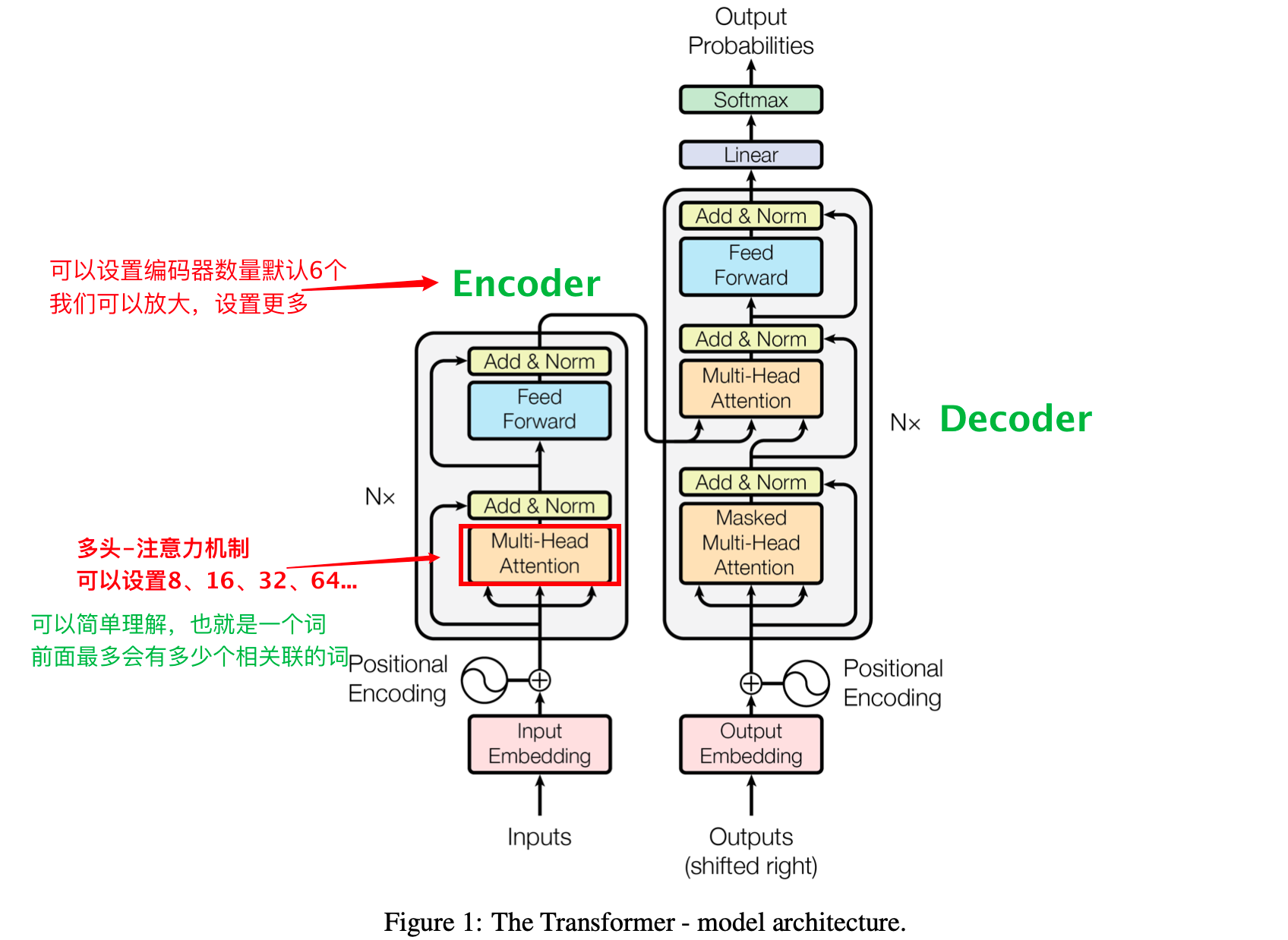
- Transformer:Encoder 将输入“序列”中的信息提取出来
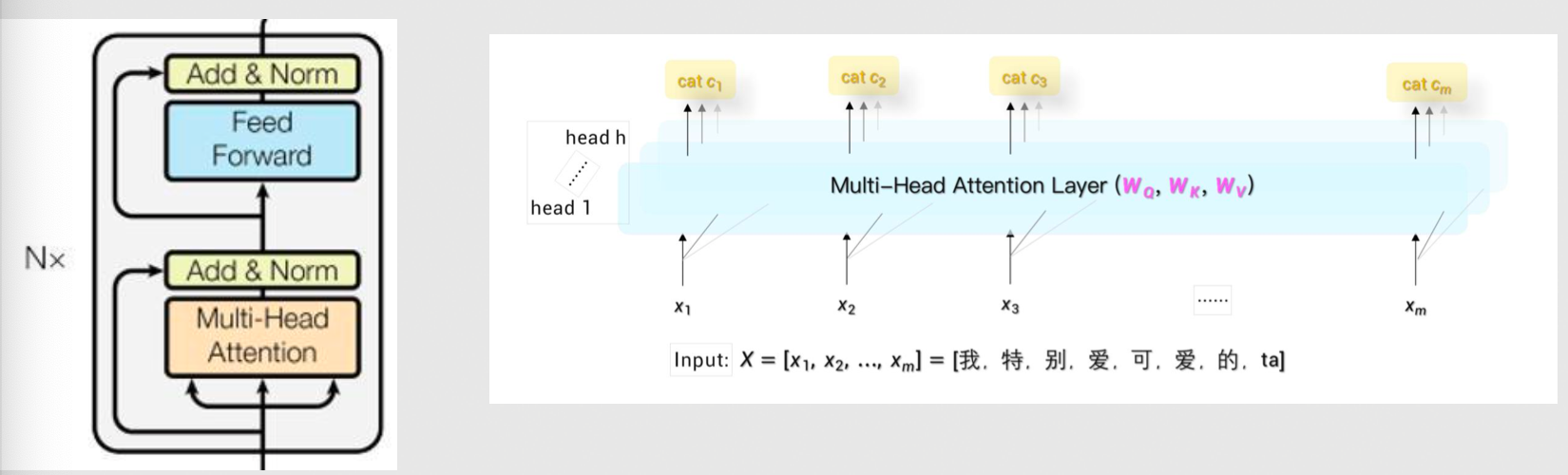
- Transformer:Encoder-Attention 将重要信息提取出来
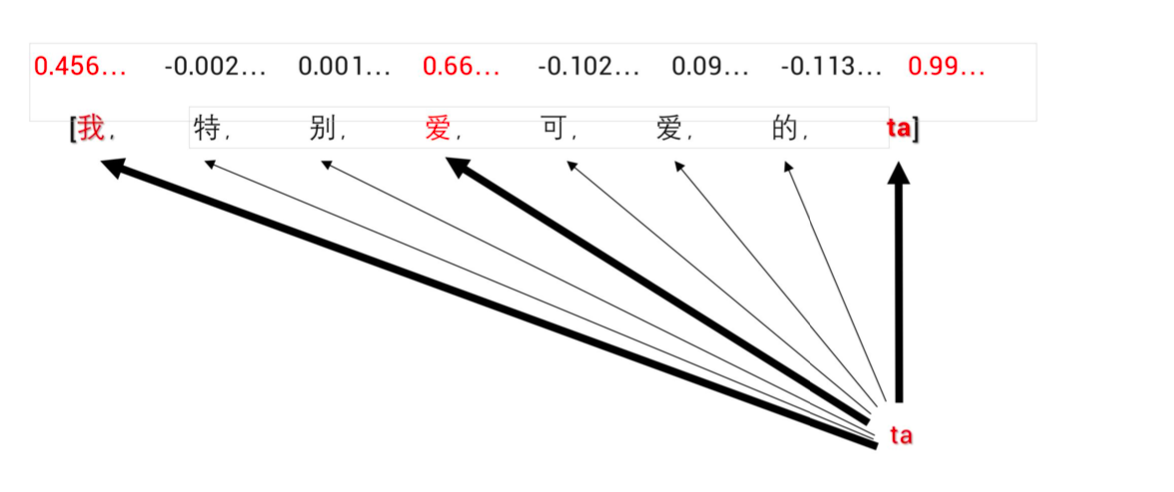
- Transformer:Encoder-Attention 将重要信息提取出来,会有一些更复杂的计算细节
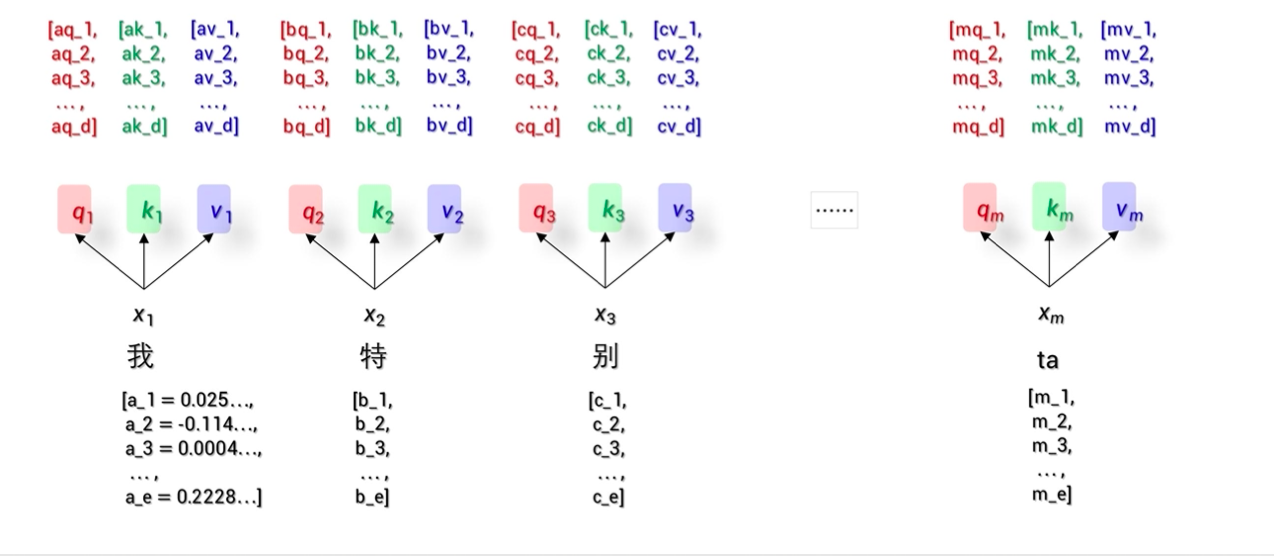
3 如何构建自己的大模型
需要具备三个方面的能力
- Prompt Engineer(提示词工程)
- LangChain(一个框架的名字)
- Fine-tuning(微调)
LangChain是什么?
- 面向大模型的开发框架
- 简单实现复杂功能的 AIGC 应用
- 多组件封装

- LangChain 推荐资料:https://wx.zsxq.com/dweb2/index/topic_detail/211842521158511
LangChain主要功能

LangChain核心组成
- 组件
- 封装
- 模块

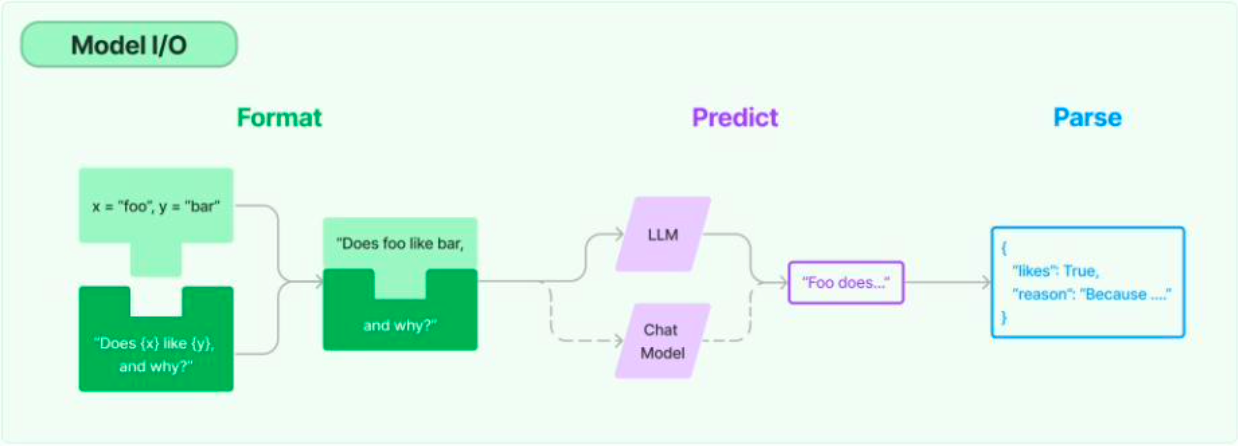
- LangChain 核心组成:I/O模块
- Prompts:主要管理、协助构建送入 Model 的输入
- Language Modes:用何种 Model
- Output parsers:解析输出结果
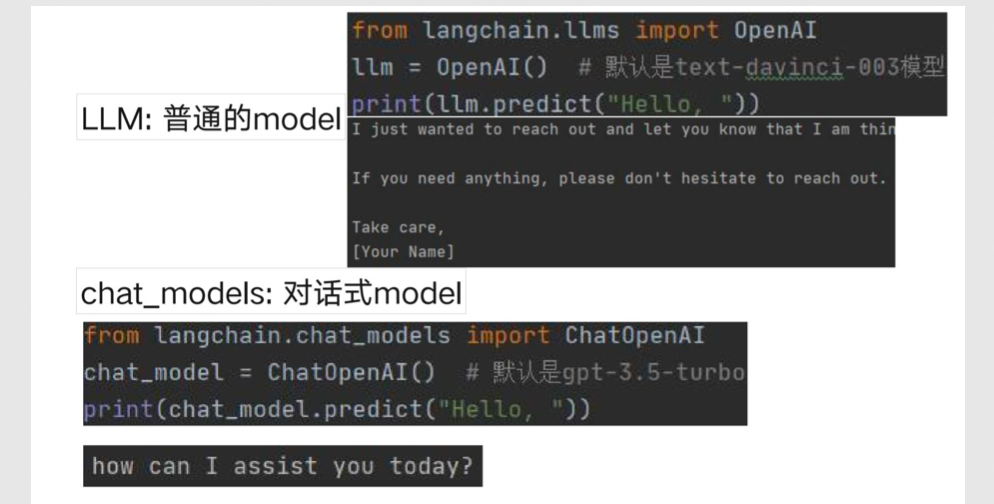
- LangChain 核心组成:I/O模块流程
- Prompts:归一化
- Language Modes:预测
- Output parsers:归一化
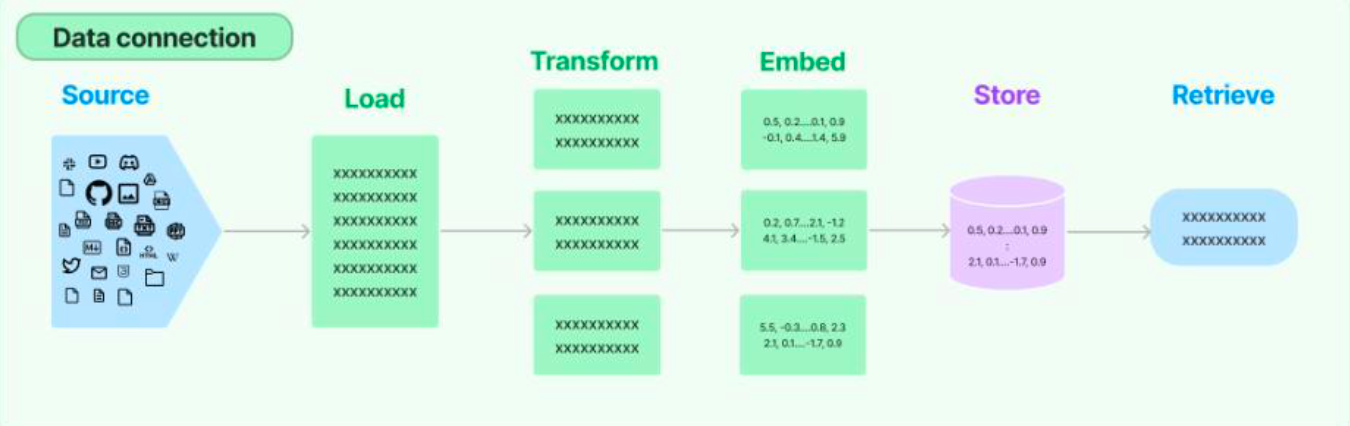
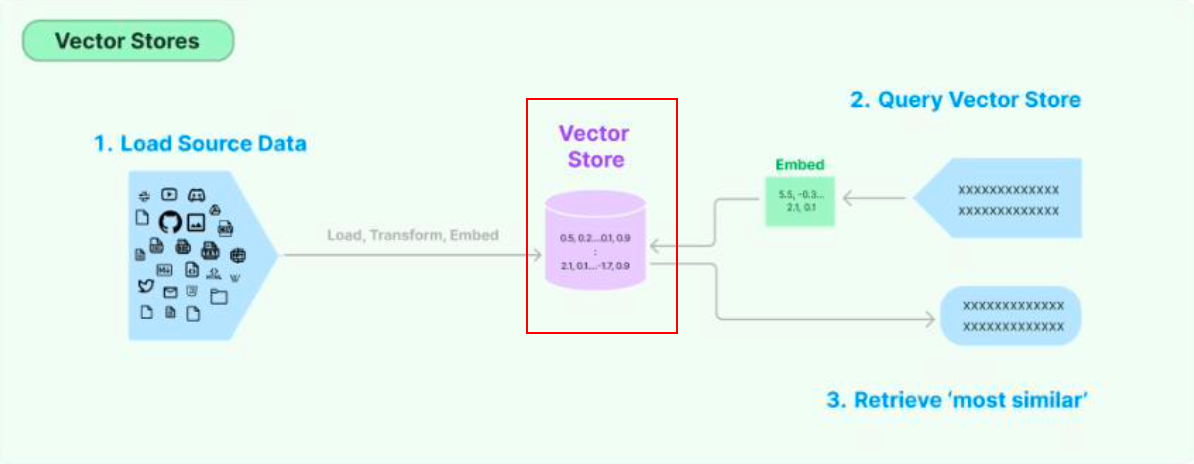
- LangChain 核心组成:数据链路(Data Connection)模块
- Source:支持各种异构数据源
- Load:加载
- Transform:变换
- Embed:向量化
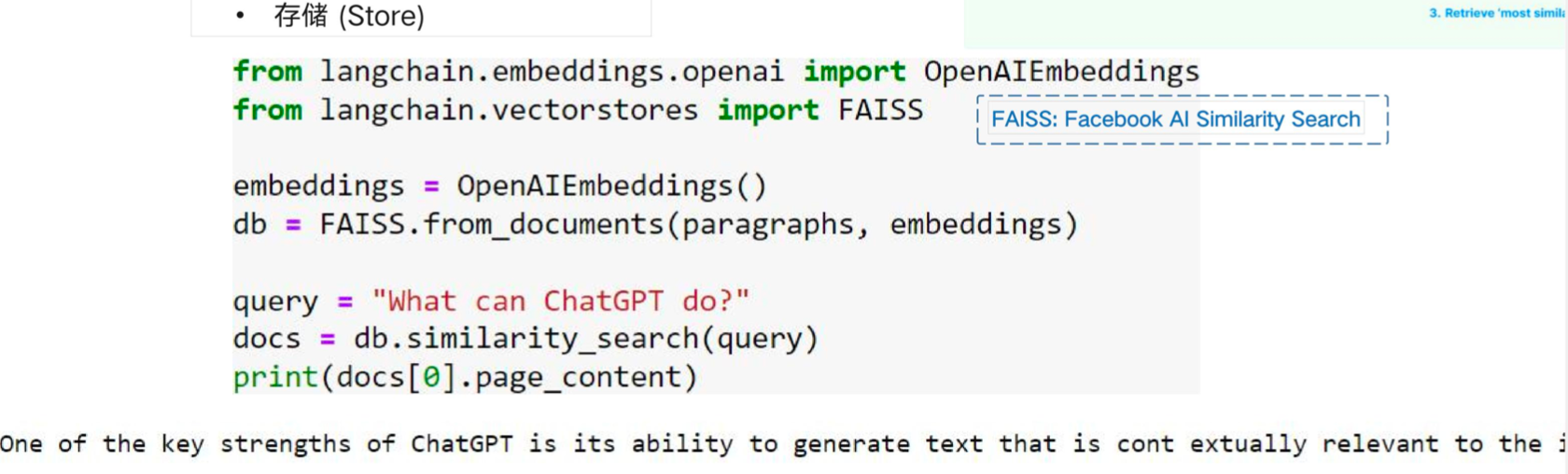
- Store:存储向量数据库
- Retrieve:检索
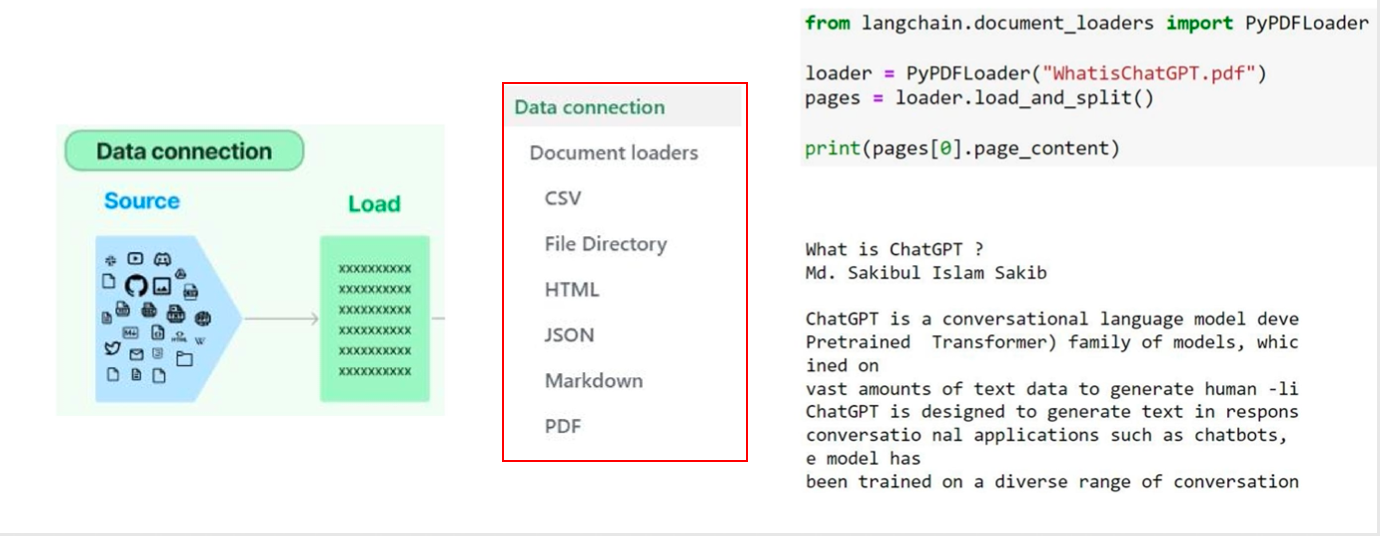
- LangChain 核心组成:数据链路(Data Connection)模块——Load
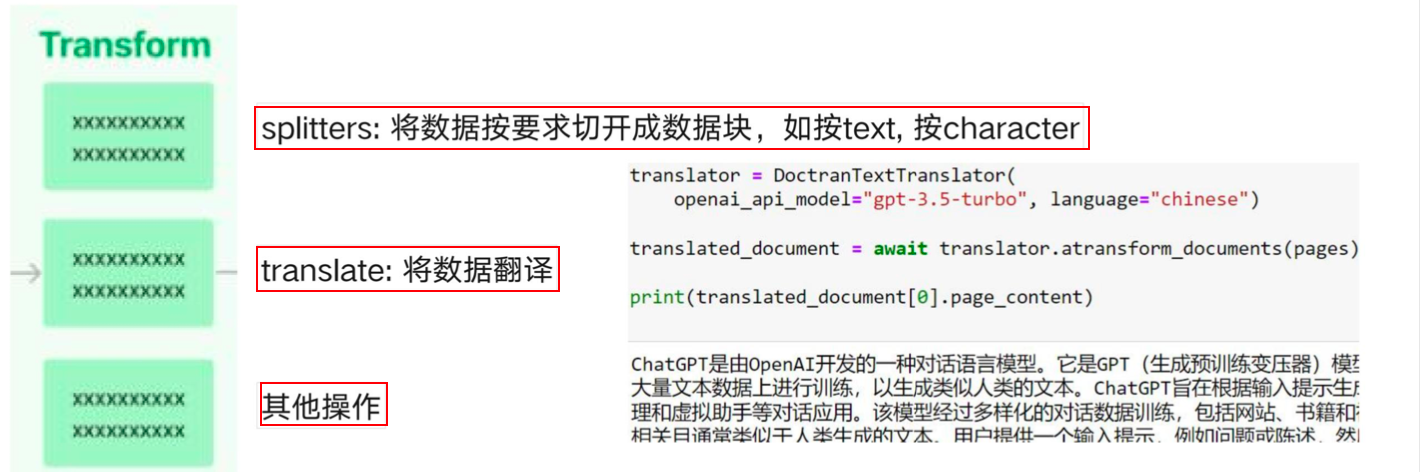
- LangChain 核心组成:数据链路(Data Connection)模块——Transform
- LangChain 核心组成:数据链路(Data Connection)模块——Embed

- LangChain 核心组成:数据链路(Data Connection)模块——Embed-相识度核心原理(“向量”距离)

- LangChain 核心组成:数据链路(Data Connection)模块——Vector Store
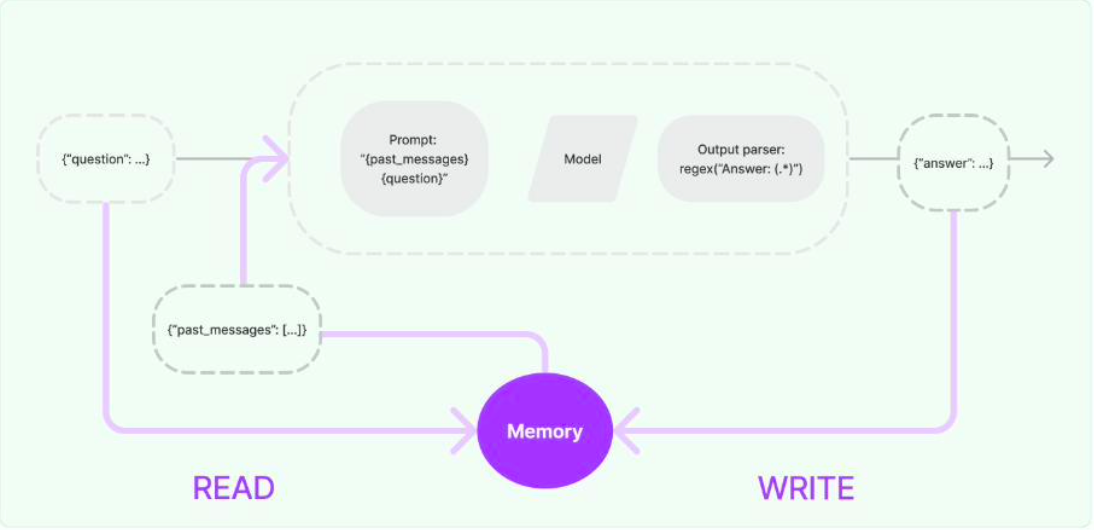
- LangChain 核心组成:记忆(Memory)模块,针对多轮对话强相关