网站建设找c宋南南公司用于做网站的费用怎么做账
目录
- 前言
- 一、关于STM32 I/O端口位的基本结构讲解
- 二、模拟I2C编写前的需知道的知识
- 1、I2C简介
- 2、根据时序编写模拟I2C程序重要的两点
- Ⅰ、主机发送数据给从机时的时序控制
- Ⅱ、主机接收来自从机的数据时的时序控制
- Ⅲ、完整的I2C时序图(按写程序的思想分割时序,每一个对应一个功能)
- 三、模拟I2C分解时序编写程序
- 1、起始信号
- 2、一个字节即8bit数据发送
- 3、释放SDA,等待接收从机应答信号
- 4、读取从机的一个字节8bit数据
- 5、发送应答/非应答信号
- 6、停止信号
- 四、读取 AT24C02 EEPROM驱动程序(下面程序很长,不需要可以跳过)
- 1、iic.h文件
- 2、iic.c文件
- 3、24cxx.h文件
- 4、24cxx.c文件
前言
这一篇文章是我大学时候写了一半的草稿,为了不让其荒废,我重新梳理完善,让大家都能明白IIC通信的原理及编写出其通信协议的程序。我相信很多同学学I2C的时候基本只是单纯看别人的文章或者是看人家人家的视频,然后做实验只是照着人家的程序敲了一遍,拿着人家的程序和I2C时序(好像懂了),真正自己写就并非能写得出来了。
这其实是大家对MCU的IO输出和I2C时序没有理解透,说真的,MCU里面最常用的UART、I2C、SPI这三个传输协议里面,I2C协议是最简单的,为什么这么说呢,初学者会认为I2C通信要写设备地址、又要写寄存器地址,还整什么应答的,哪有UART简单(只有起始位、数据位、校验位、停止位)。那我和你说说,UART的TX线是我方主动发送,确实不用注意什么,但是接收呢?我方只能老老实实遵循双方协定的波特率去接收它方发送过来的数据,也就是说时钟要精准,并且要根据时钟精准拿捏每一位的数据,这样读取出来的数据才无误,大家可以看看我之前写的模拟串口文章,而I2C的时钟是由我方主机端控制的,也就是说时钟频率只要在它方允许范围内,我们是能正常通信的,这为什么这么说呢?时钟其实就是脉冲信号,而每一个脉冲就是让它方从机每走一步的动力,因此在允许范围呢,它方从机被我方死死拿捏了。
废话不多说,开讲…
一、关于STM32 I/O端口位的基本结构讲解
其实这个我在之前就发表过STM32与IO控制相关的文章了,大家也可阅读“STM32IO文章”。
下图是我在STM32中文参考手册截取出来的。
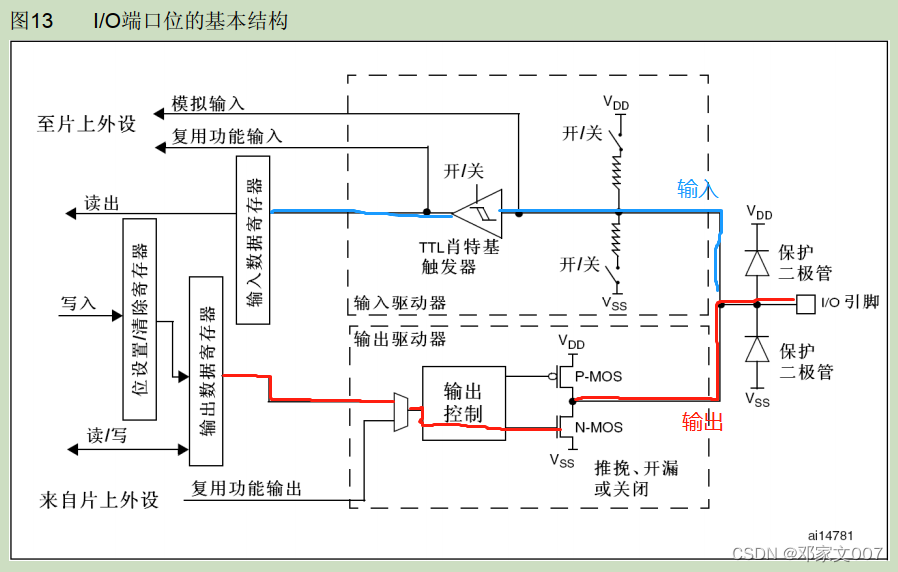
这里我讲一下为什么我们在写模拟I2C的时候需要将SDA线上的IO配置为开漏输出。上图中的上P-MOS管和下N-MOS管组合成了推挽输出电路,电子工程师一般叫图腾柱输出电路,这个电路优点在于输出响应快,而且驱动能力强。其工作原理就是设置输出高电平,那么上部分的P-MOS的G极低电平(Vgs<0),P-MOS被激活,因此P-MOS的S、D极导通,向外推出VDD电平,而下部分正好与上部分相反,N-MOS管处于非激活状态;当设置输出低电平时,那么下部分的N-MOS的G极高电平(Vgs>0),N-MOS被激活,因此N-MOS的S、D极导通,将外部电平值拉下低电平。(提示:上下两管公用极是漏极D)
好,经过推挽电路的讲解大家已经知道其工作原理了,而开漏输出就是只使用了下管电路,也就是上图红色标线的线路,当G极为低电平是,N-MOS处于非激活状态,也就是S、D极不导通,那么电路处于高阻太,I2C的SDA线就呈现只有上拉电阻拉高的高电平状态,也就是说此时SDA电平信号是不受我方主机控制的,从机可以随意控制高、低电平。在STM32中文参考手册有一段话,如下图所示:

也就是说,我们设置开漏模式是可以读取IO的输入电平的,因此我们要读取SDA线上从机的信号,务必要将SDA输出的IO为高电平,才能有效读取从机输入的电平信号。
二、模拟I2C编写前的需知道的知识
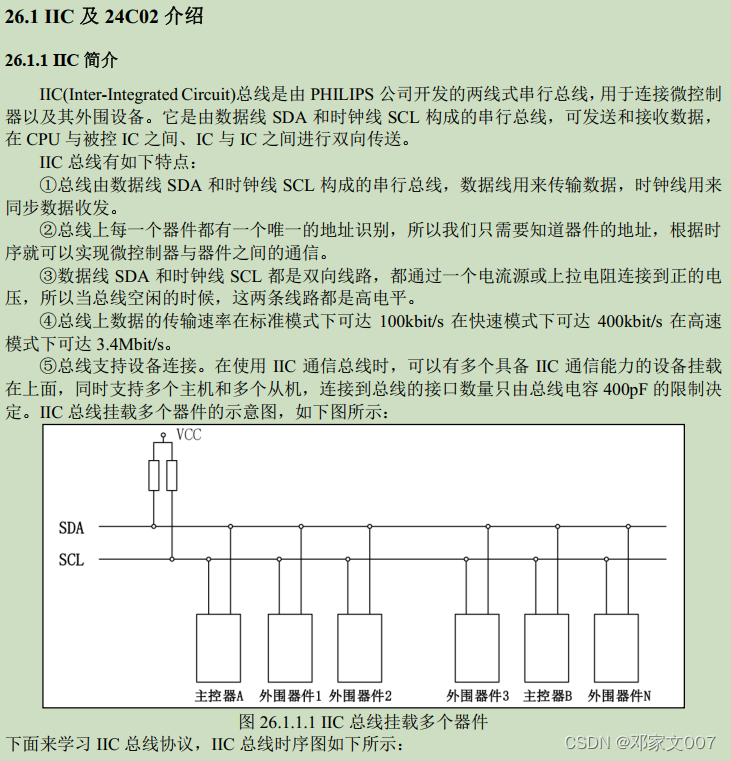
1、I2C简介
这里我就使用正点原子的开发指南贴给大家看啦,当个搬运工。


2、根据时序编写模拟I2C程序重要的两点
大家看了I2C简介后应该对其有大致了解了吧,能影响、控制I2C通讯的有三个通讯状态:1、SCL低电平,数据传输无效; 2、SDA下降沿信号触发I2C起始信号; 3、SDA上升沿信号触发I2C停止信号。也就是说I2C通讯中途一定要避免这后面两个事件发送。
Ⅰ、主机发送数据给从机时的时序控制

上部分的时序是时钟SCL,下部分的是数据SDA。细心观察的你们肯定发现了,发送数据的电平占用了前1//4周期的低电平时钟 和 后1/4周期的低电平时钟,这是为什么呢,因为我们在1/2周期的高电平时钟期间内才设置发送数据位的电平信号,那么很可能会触发前面说的起始信号和停止信号事件,这是我们不期望的,所以我们可以利用前后1/4周期的低电平时钟这个无效数据传输期间把发送的数据位的电平信号提前和延后来避免。
Ⅱ、主机接收来自从机的数据时的时序控制

前面1/2时钟周期我们需要释放SDA,不过前提是我们主机持有SDA才需要释放,比如主机发送完8bit数据后需要接收从机的应答信号,因此需要要先释放SDA,然后等待接收从机应答信号;如果是主机接收完来自从机的8bit数据后是不需要释放SDA的,因为这个期间是从机持有SDA,而不是主机持有SDA,因此接收完数据后的主机应该持回SDA,发送应答信号给从机,如果主机继续接收下一个字节数据,那么就需要先释放SDA,再去接收数据了。
前面也知道,释放SDA(I2C总线空闲)需要SDA和SCL都为高电平。这里我们提前在SCL为低电平无效数据传输阶段先把SDA拉到高电平,前面也说过了,反正上、下边沿信号触发起始、停止信号,而且其还有一个妙处就是在SCL高电平时,并没有立即读取SDA电平信号,而是延迟了1/4个时钟周期,这里巧妙在立即读取数据时,I2C的SDA可能还没有释放完毕,还有就算SDA释放完了,可能从机还没有将它要发送的应答信号或者是发送数据的第一个bit信号还未发送出来,那我方主机就可能读取的信号不正确了,延迟可以确保读取的数据准确性。
经过上面分析,也就是无论是主机发送数据后接收应答信号,还是主机连接接收从机数据,都需要先释放SDA。这里我们也可以用实际IIC通讯过程图分析,如下图所示:

写操作没什么好说的,就是主机持有SDA发送数据,然后释放SDA,读取从机发送的数据。而读操作大家应该也注意到了我用①②标注的红色框框的读一个字节的操作过程吧,大家会说明明主机在发送从机地址与读写操作后,已经在等待接收从机应答前释放了SDA了,而①在读的时候又重复释放了SDA,会不会有问题呀。答案是没问题的,因为在前面就说过我们SDA是使用开漏输出的,释放SDA就是让SDA线处于高电平,也就是说此时MCU这边是没有IO与SDA线呈现高阻态(可认为就是断开的),因此重复断开是完全不影响数据的读取结果的(都断开了,再断现在是没有改变的),除了这个原因外,①的重复释放SDA,是为了保证模拟时序的完整性。
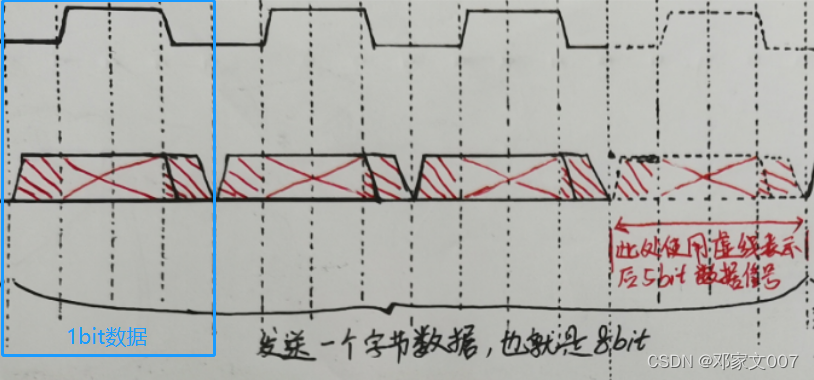
Ⅲ、完整的I2C时序图(按写程序的思想分割时序,每一个对应一个功能)
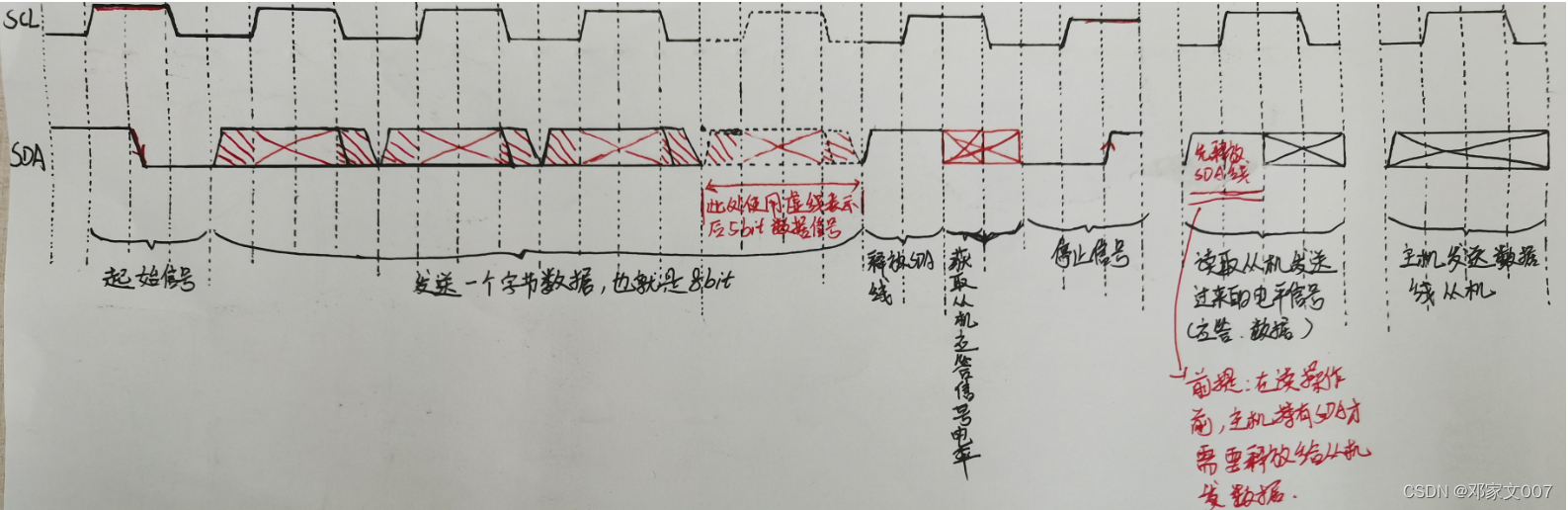
细心的你们应该发现了一点,除了其实信号和停止信号的时序只有3/4个时钟周期的,而接收bit位数据信号和发送bit位数据的时序都是一个周期的(前1/4低电平时钟 + 中1/2高电平时钟 + 后1/4低电平时钟),也就是说这样编写出来的I2C通讯时序是绝对完整的。
三、模拟I2C分解时序编写程序
时序图中,一个时钟分为四段,每一段时长是2us,也就是一个时钟周期是8us,频率为125KHz,那么传输速度就是125K bit/s。
1、起始信号

/* 产生IIC起始信号 */
void iic_start(void)
{ /* 空闲状态 */IIC_SCL(1);IIC_SDA(1);iic_delay(); //延时2us/* START信号: 当SCL为高时, SDA从高变成低, 表示起始信号 *//* 下降沿信号,iic开始信号 */IIC_SCL(1);IIC_SDA(0); iic_delay();/* 时钟低电平,数据传输无效,持有SDA,钳住数据 */IIC_SCL(0); IIC_SDA(0); iic_delay();
}
2、一个字节即8bit数据发送
/* IIC发送一个字节* data: 要发送的数据*/
void iic_send_byte(uint8_t data)
{uint8_t t;/* SDA数据电平状态保持在 前1/4低电平时钟 + 1/2高电平时钟 + 后1/4时钟,确保在1/2高电平时钟期间没有SDA的边沿跳变信号*/for (t = 0; t < 8; t++){ /* 继上一个低电平时钟无效数据前一半 */IIC_SCL(0);IIC_SDA((data & 0x80) >> 7); /* 高位先发送 */iic_delay();IIC_SCL(1);IIC_SDA((data & 0x80) >> 7); /* 高位先发送 */iic_delay();iic_delay();IIC_SCL(0);IIC_SDA((data & 0x80) >> 7); /* 高位先发送 */iic_delay();data <<= 1; /* 左移1位,用于下一次发送 */}
}
3、释放SDA,等待接收从机应答信号

/* 等待应答信号到来* 返回值1,接收应答失败* 0,接收应答成功*/
uint8_t iic_wait_ack(void)
{uint8_t waittime = 0;uint8_t rack = 0;/* 主机释放SDA线(此时外部器件可以拉低SDA线) */IIC_SCL(0); //继主机发送一字节后的前低电平1/4时钟IIC_SDA(1); iic_delay();IIC_SCL(1); /* SCL=1, 此时从机可以返回ACK */IIC_SDA(1); //继续释放SDA线,为读取从机的应答信号iic_delay();while (IIC_READ_SDA) /* 等待应答 */{waittime++;if (waittime > 250){iic_stop();rack = 1;break;}}IIC_SCL(0); /* SCL=0, 结束ACK检查 */iic_delay();return rack;
}
4、读取从机的一个字节8bit数据

/* IIC读取一个字节* 返回接收到的数据*/
uint8_t iic_read_byte(void)
{uint8_t i, receive = 0;for (i = 0; i < 8; i++ ) /* 接收1个字节数据 */{receive <<= 1; /* 高位先输出,所以先收到的数据位要左移 */IIC_SCL(0);IIC_SDA(1);iic_delay();/* 先输出高电平时钟,并且延时1/4时钟,确保读取的是正确的电平信号,如果不延时的话,我们立即读取的电平信号可能是从机还未设置输出对应的数据电平 *//* 而SDA设置高电平,那么SCL和SDA都为高,也就是把主机SDA释放,给从机持有SDA发送数据,那么主机接收从机发送的数据 */IIC_SCL(1);IIC_SDA(1);iic_delay();if (IIC_READ_SDA){receive++;}iic_delay();IIC_SCL(0);iic_delay();}return receive;
}
5、发送应答/非应答信号

/* 产生ACK应答 */
void iic_ack(void)
{IIC_SCL(0); /* 产生一个时钟 */IIC_SDA(0); /* SCL 0 -> 1 时 SDA = 0,表示应答 */iic_delay();/* 应答信号 */IIC_SCL(1); /* 产生一个时钟 */IIC_SDA(0);iic_delay();iic_delay();IIC_SCL(0);IIC_SDA(0); iic_delay();
}/* 不产生ACK应答 */
void iic_nack(void)
{IIC_SCL(0); /* 产生一个时钟 */IIC_SDA(1); /* SCL 0 -> 1 时 SDA = 0,表示应答 */iic_delay();/* 非应答信号 */IIC_SCL(1); /* 产生一个时钟 */IIC_SDA(1);iic_delay();iic_delay();IIC_SCL(0);IIC_SDA(1); iic_delay();
}
6、停止信号
/* 产生IIC停止信号 */
void iic_stop(void)
{/* STOP信号: 当SCL为高时, SDA从低变成高, 表示停止信号 */IIC_SCL(0);IIC_SDA(0); iic_delay();/* 时钟有效 */IIC_SCL(1);IIC_SDA(0);iic_delay();/* 上升沿信号,iic停止信号 */IIC_SCL(1);IIC_SDA(1); /* 发送I2C总线结束信号 */iic_delay();
}
四、读取 AT24C02 EEPROM驱动程序(下面程序很长,不需要可以跳过)
1、iic.h文件
#ifndef __IIC_H
#define __IIC_H#include "main.h"/******************************************************************************************/
/* 引脚 定义 */#define IIC_SCL_GPIO_PORT GPIOH
#define IIC_SCL_GPIO_PIN GPIO_PIN_4
#define IIC_SCL_GPIO_CLK_ENABLE() do{ __HAL_RCC_GPIOH_CLK_ENABLE(); }while(0) /* PB口时钟使能 */#define IIC_SDA_GPIO_PORT GPIOH
#define IIC_SDA_GPIO_PIN GPIO_PIN_5
#define IIC_SDA_GPIO_CLK_ENABLE() do{ __HAL_RCC_GPIOH_CLK_ENABLE(); }while(0) /* PB口时钟使能 *//******************************************************************************************//* IO操作 */
#define IIC_SCL(x) do{ x ? \HAL_GPIO_WritePin(IIC_SCL_GPIO_PORT, IIC_SCL_GPIO_PIN, GPIO_PIN_SET) : \HAL_GPIO_WritePin(IIC_SCL_GPIO_PORT, IIC_SCL_GPIO_PIN, GPIO_PIN_RESET); \}while(0) /* SCL */#define IIC_SDA(x) do{ x ? \HAL_GPIO_WritePin(IIC_SDA_GPIO_PORT, IIC_SDA_GPIO_PIN, GPIO_PIN_SET) : \HAL_GPIO_WritePin(IIC_SDA_GPIO_PORT, IIC_SDA_GPIO_PIN, GPIO_PIN_RESET); \}while(0) /* SDA */#define IIC_READ_SDA HAL_GPIO_ReadPin(IIC_SDA_GPIO_PORT, IIC_SDA_GPIO_PIN) /* 读取SDA *//* IIC所有操作函数 */
void iic_init(void); /* 初始化IIC的IO口 */
void iic_start(void); /* 发送IIC开始信号 */
void iic_stop(void); /* 发送IIC停止信号 */
void iic_ack(void); /* IIC发送ACK信号 */
void iic_nack(void); /* IIC不发送ACK信号 */
uint8_t iic_wait_ack(void); /* IIC等待ACK信号 */
void iic_send_byte(uint8_t txd);/* IIC发送一个字节 */
uint8_t iic_read_byte(void);/* IIC读取一个字节 */#endif
2、iic.c文件
#include "iic.h"/* 初始化IIC */
void iic_init(void)
{GPIO_InitTypeDef gpio_init_struct;IIC_SCL_GPIO_CLK_ENABLE(); /* SCL引脚时钟使能 */IIC_SDA_GPIO_CLK_ENABLE(); /* SDA引脚时钟使能 */gpio_init_struct.Pin = IIC_SCL_GPIO_PIN;gpio_init_struct.Mode = GPIO_MODE_OUTPUT_PP; /* 推挽输出 */gpio_init_struct.Pull = GPIO_PULLUP; /* 上拉 */gpio_init_struct.Speed = GPIO_SPEED_FREQ_VERY_HIGH; /* 快速 */HAL_GPIO_Init(IIC_SCL_GPIO_PORT, &gpio_init_struct);/* SCL */gpio_init_struct.Pin = IIC_SDA_GPIO_PIN;gpio_init_struct.Mode = GPIO_MODE_OUTPUT_OD; /* 开漏输出 */HAL_GPIO_Init(IIC_SDA_GPIO_PORT, &gpio_init_struct);/* SDA *//* SDA引脚模式设置,开漏输出,上拉, 这样就不用再设置IO方向了, 开漏输出的时候(=1), 也可以读取外部信号的高低电平 */iic_stop(); /* 停止总线上所有设备 */
}/* IIC延时函数,用于控制IIC读写速度,这是定义1/4个时钟时长 */
static void iic_delay(void)
{delay_us(2); /* 2us的延时, 读写速度在250Khz以内 */
}/* 产生IIC起始信号 */
void iic_start(void)
{ /* 空闲状态 */IIC_SCL(1);IIC_SDA(1);iic_delay();/* START信号: 当SCL为高时, SDA从高变成低, 表示起始信号 *//* 下降沿信号,iic开始信号 */IIC_SCL(1);IIC_SDA(0); iic_delay();/* 时钟低电平,数据传输无效,持有SDA,钳住数据 */IIC_SCL(0); IIC_SDA(0); iic_delay();
}/* 产生IIC停止信号 */
void iic_stop(void)
{/* STOP信号: 当SCL为高时, SDA从低变成高, 表示停止信号 */IIC_SCL(0);IIC_SDA(0); iic_delay();/* 时钟有效 */IIC_SCL(1);IIC_SDA(0);iic_delay();/* 上升沿信号,iic停止信号 */IIC_SCL(1);IIC_SDA(1); /* 发送I2C总线结束信号 */iic_delay();
}/* 等待应答信号到来* 返回值1,接收应答失败* 0,接收应答成功*/
uint8_t iic_wait_ack(void)
{uint8_t waittime = 0;uint8_t rack = 0;/* 主机释放SDA线(此时外部器件可以拉低SDA线) */IIC_SCL(0); //继主机发送一字节后的前低电平1/4时钟IIC_SDA(1); iic_delay();IIC_SCL(1); /* SCL=1, 此时从机可以返回ACK */IIC_SDA(1); //继续释放SDA线,为读取从机的应答信号iic_delay();while (IIC_READ_SDA) /* 等待应答 */{waittime++;if (waittime > 250){iic_stop();rack = 1;break;}}IIC_SCL(0); /* SCL=0, 结束ACK检查 */iic_delay();return rack;
}/* 产生ACK应答 */
void iic_ack(void)
{IIC_SCL(0); /* 产生一个时钟 */IIC_SDA(0); /* SCL 0 -> 1 时 SDA = 0,表示应答 */iic_delay();/* 应答信号 */IIC_SCL(1); /* 产生一个时钟 */IIC_SDA(0);iic_delay();iic_delay();IIC_SCL(0);IIC_SDA(0);iic_delay();
}/* 不产生ACK应答 */
void iic_nack(void)
{IIC_SCL(0); /* 产生一个时钟 */IIC_SDA(1); /* SCL 0 -> 1 时 SDA = 0,表示应答 */iic_delay();/* 非应答信号 */IIC_SCL(1); /* 产生一个时钟 */IIC_SDA(1);iic_delay();iic_delay();IIC_SCL(0);IIC_SDA(1);iic_delay();
}/* IIC发送一个字节* data: 要发送的数据*/
void iic_send_byte(uint8_t data)
{uint8_t t;/* SDA数据电平状态保持在 前1/4低电平时钟 + 1/2高电平时钟 + 后1/4时钟,确保在1/2高电平时钟期间没有SDA的边沿跳变信号*/for (t = 0; t < 8; t++){ /* 继上一个低电平时钟无效数据前一半 */IIC_SCL(0);IIC_SDA((data & 0x80) >> 7); /* 高位先发送 */iic_delay();IIC_SCL(1);IIC_SDA((data & 0x80) >> 7); /* 高位先发送 */iic_delay();iic_delay();IIC_SCL(0);IIC_SDA((data & 0x80) >> 7); /* 高位先发送 */iic_delay();data <<= 1; /* 左移1位,用于下一次发送 */}
}/* IIC读取一个字节* 返回接收到的数据*/
uint8_t iic_read_byte(void)
{uint8_t i, receive = 0;for (i = 0; i < 8; i++ ) /* 接收1个字节数据 */{receive <<= 1; /* 高位先输出,所以先收到的数据位要左移 */IIC_SCL(0);IIC_SDA(1);iic_delay();/* 先输出高电平时钟,并且延时1/4时钟,确保读取的是正确的电平信号,如果不延时的话,我们立即读取的电平信号可能是从机还未设置输出对应的数据电平 *//* 而SDA设置高电平,那么SCL和SDA都为高,也就是把主机SDA释放,给从机持有SDA发送数据,那么主机接收从机发送的数据 */IIC_SCL(1);IIC_SDA(1);iic_delay();if (IIC_READ_SDA){receive++;}iic_delay();IIC_SCL(0);iic_delay();}return receive;
}
3、24cxx.h文件
#ifndef __24CXX_H
#define __24CXX_H#include "main.h"#define AT24C01 127
#define AT24C02 255
#define AT24C04 511
#define AT24C08 1023
#define AT24C16 2047
#define AT24C32 4095
#define AT24C64 8191
#define AT24C128 16383
#define AT24C256 32767/* 开发板使用的是24c02,所以定义EE_TYPE为AT24C02 */#define EE_TYPE AT24C02void at24cxx_init(void); /* 初始化IIC */
uint8_t at24cxx_check(void); /* 检查器件 */
uint8_t at24cxx_read_one_byte(uint16_t addr); /* 指定地址读取一个字节 */
void at24cxx_write_one_byte(uint16_t addr,uint8_t data); /* 指定地址写入一个字节 */
void at24cxx_write(uint16_t addr, uint8_t *pbuf, uint16_t datalen); /* 从指定地址开始写入指定长度的数据 */
void at24cxx_read(uint16_t addr, uint8_t *pbuf, uint16_t datalen); /* 从指定地址开始读出指定长度的数据 */
void at24cxx_write_one_page_byte(uint16_t addr, uint8_t *data, uint16_t datalen); /* 读取一页,也就是8个字节 */
void at24cxx_read_n_byte(uint16_t addr, uint8_t *data, uint16_t datalen); /* 从指定地址开始读出指定长度的数据 */#endif
4、24cxx.c文件
#include "myiic.h"
#include "24cxx.h"/*** @brief 初始化IIC接口* @param 无* @retval 无*/
void at24cxx_init(void)
{iic_init();
}/*** @brief 在AT24CXX指定地址读出一个数据* @param readaddr: 开始读数的地址* @retval 读到的数据*/
uint8_t at24cxx_read_one_byte(uint16_t addr)
{uint8_t temp = 0;iic_start(); /* 发送起始信号 *//* 根据不同的24CXX型号, 发送高位地址* 1, 24C16以上的型号, 分2个字节发送地址* 2, 24C16及以下的型号, 分1个低字节地址 + 占用器件地址的bit1~bit3位 用于表示高位地址, 最多11位地址* 对于24C01/02, 其器件地址格式(8bit)为: 1 0 1 0 A2 A1 A0 R/W* 对于24C04, 其器件地址格式(8bit)为: 1 0 1 0 A2 A1 a8 R/W* 对于24C08, 其器件地址格式(8bit)为: 1 0 1 0 A2 a9 a8 R/W* 对于24C16, 其器件地址格式(8bit)为: 1 0 1 0 a10 a9 a8 R/W* R/W : 读/写控制位 0,表示写; 1,表示读;* A0/A1/A2 : 对应器件的1,2,3引脚(只有24C01/02/04/8有这些脚)* a8/a9/a10: 对应存储整列的高位地址, 11bit地址最多可以表示2048个位置, 可以寻址24C16及以内的型号*/ if (EE_TYPE > AT24C16) /* 24C16以上的型号, 分2个字节发送地址 */{iic_send_byte(0xA0); /* 发送写命令, IIC规定最低位是0, 表示写入 */iic_wait_ack(); /* 每次发送完一个字节,都要等待ACK */iic_send_byte(addr >> 8); /* 发送高字节地址 */}else {iic_send_byte(0xA0 + ((addr >> 8) << 1)); /* 发送器件 0xA0 + 高位a8/a9/a10地址,写数据 */}iic_wait_ack(); /* 每次发送完一个字节,都要等待ACK */iic_send_byte(addr % 256); /* 发送低位地址 */iic_wait_ack(); /* 等待ACK, 此时地址发送完成了 */iic_start(); /* 重新发送起始信号 */ iic_send_byte(0xA1); /* 进入接收模式, IIC规定最低位是1, 表示读取 */iic_wait_ack(); /* 每次发送完一个字节,都要等待ACK */temp = iic_read_byte(); /* 接收一个字节数据后返回非应答信号 */iic_nack(); /* 发送nACK */ iic_stop(); /* 产生一个停止条件 */return temp;
}/*** @brief 在AT24CXX指定地址写入一个数据* @param addr: 写入数据的目的地址* @param data: 要写入的数据* @retval 无*/
void at24cxx_write_one_byte(uint16_t addr, uint8_t data)
{/* 原理说明见:at24cxx_read_one_byte函数, 本函数完全类似 */iic_start(); /* 发送起始信号 */if (EE_TYPE > AT24C16) /* 24C16以上的型号, 分2个字节发送地址 */{iic_send_byte(0xA0); /* 发送写命令, IIC规定最低位是0, 表示写入 */iic_wait_ack(); /* 每次发送完一个字节,都要等待ACK */iic_send_byte(addr >> 8); /* 发送高字节地址 */}else{iic_send_byte(0xA0 + ((addr >> 8) << 1)); /* 发送器件 0xA0 + 高位a8/a9/a10地址,写数据 */}iic_wait_ack(); /* 每次发送完一个字节,都要等待ACK */iic_send_byte(addr % 256); /* 发送低位地址 */iic_wait_ack(); /* 等待ACK, 此时地址发送完成了 *//* 因为写数据的时候,不需要进入接收模式了,所以这里不用重新发送起始信号了 */iic_send_byte(data); /* 发送1字节 */iic_wait_ack(); /* 等待ACK */iic_stop(); /* 产生一个停止条件 */delay_ms(10); /* 注意: EEPROM 写入比较慢,必须等到10ms后再写下一个字节 */
}/*** @brief 检查AT24CXX是否正常* @note 检测原理: 在器件的末地址写如0X55, 然后再读取, 如果读取值为0X55* 则表示检测正常. 否则,则表示检测失败.** @param 无* @retval 检测结果* 0: 检测成功* 1: 检测失败*/
uint8_t at24cxx_check(void)
{uint8_t temp;uint16_t addr = EE_TYPE;temp = at24cxx_read_one_byte(addr); /* 避免每次开机都写AT24CXX */if (temp == 0x55) /* 读取数据正常 */{return 0;}else /* 排除第一次初始化的情况 */{at24cxx_write_one_byte(addr, 0x55); /* 先写入数据 */temp = at24cxx_read_one_byte(255); /* 再读取数据 */if (temp == 0x55)return 0;}return 1;
}/*** @brief 在AT24CXX里面的指定地址开始读出指定个数的数据* @param addr : 开始读出的地址 对24c02为0~255* @param pbuf : 数据数组首地址* @param datalen : 要读出数据的个数* @retval 无*/
void at24cxx_read(uint16_t addr, uint8_t *pbuf, uint16_t datalen)
{while (datalen--){*pbuf++ = at24cxx_read_one_byte(addr++);}
}/*** @brief 在AT24CXX里面的指定地址开始写入指定个数的数据* @param addr : 开始写入的地址 对24c02为0~255* @param pbuf : 数据数组首地址* @param datalen : 要写入数据的个数* @retval 无*/
void at24cxx_write(uint16_t addr, uint8_t *pbuf, uint16_t datalen)
{while (datalen--){at24cxx_write_one_byte(addr, *pbuf);addr++;pbuf++;}
}/* 只能连续写入8个字节 */
void at24cxx_write_one_page_byte(uint16_t addr, uint8_t *data, uint16_t datalen)
{/* 原理说明见:at24cxx_read_one_byte函数, 本函数完全类似 */iic_start(); /* 发送起始信号 */if (EE_TYPE > AT24C16) /* 24C16以上的型号, 分2个字节发送地址 */{iic_send_byte(0xA0); /* 发送写命令, IIC规定最低位是0, 表示写入 */iic_wait_ack(); /* 每次发送完一个字节,都要等待ACK */iic_send_byte(addr >> 8); /* 发送高字节地址 */}else{iic_send_byte(0xA0 + ((addr >> 8) << 1)); /* 发送器件 0xA0 + 高位a8/a9/a10地址,写数据 */}iic_wait_ack(); /* 每次发送完一个字节,都要等待ACK */iic_send_byte(addr % 256); /* 发送低位地址 */iic_wait_ack(); /* 等待ACK, 此时地址发送完成了 *//* 因为写数据的时候,不需要进入接收模式了,所以这里不用重新发送起始信号了 */while (datalen--){iic_send_byte(*data); /* 发送1字节 */iic_wait_ack(); /* 等待ACK */data++;} iic_stop(); /* 产生一个停止条件 */
}void at24cxx_read_n_byte(uint16_t addr, uint8_t *data, uint16_t datalen)
{int i;iic_start(); /* 发送起始信号 */if (EE_TYPE > AT24C16) /* 24C16以上的型号, 分2个字节发送地址 */{iic_send_byte(0xA0); /* 发送写命令, IIC规定最低位是0, 表示写入 */iic_wait_ack(); /* 每次发送完一个字节,都要等待ACK */iic_send_byte(addr >> 8); /* 发送高字节地址 */}else {iic_send_byte(0xA0 + ((addr >> 8) << 1)); /* 发送器件 0xA0 + 高位a8/a9/a10地址,写数据 */}iic_wait_ack(); /* 每次发送完一个字节,都要等待ACK */iic_send_byte(addr % 256); /* 发送低位地址 */iic_wait_ack(); /* 等待ACK, 此时地址发送完成了 */iic_start(); /* 重新发送起始信号 */ iic_send_byte(0xA1); /* 进入接收模式, IIC规定最低位是1, 表示读取 */iic_wait_ack(); /* 每次发送完一个字节,都要等待ACK */for(i = 0; i < datalen; i++){if(datalen == i+1) {data[i] = iic_read_byte(); /* 接收一个字节数据后返回非应答信号 */iic_nack(); /* 发送nACK */} else {data[i] = iic_read_byte(); /* 接收一个字节数据后返回应答信号 */iic_ack(); /* 发送ACK */}}iic_stop(); /* 产生一个停止条件 */
}