网站建设服务器介绍图片深圳网站公司制作
目录
- 基本概念
- 节点类型
- ast.Assign
- ast.Name
- ast.Constant
- ast.Call
- ast.Attribute
- 结点的遍历
- ast源码
- 示例
- 结点的修改
- 示例
- 参考链接
基本概念
在 python 中,我们可以通过自带的 ast 模块来对解析遍历语法树,通过ast.parse()可以将字符串代码解析为抽象语法树,然后通过ast.dump()可以打印这棵语法树。
除了ast模块外,还有 astor 模块,其中的 astor.to_sourse() 函数可以将语法树Node转换为代码, astor.dump_tree() 可以很好地格式化整棵树。
除了这些基础操作外,我们还可以遍历和修改整棵语法树。
比如,对于a = 10 来说,我们可以先解析成抽象语法树,然后打印所有的结点,如下所示。根据输出,我们可以看到根节点是Module类型的,然后其body是Assign类型的。对于Assign类型的结点,可以继续划分为Name结点(表示变量名)和Constant结点(表示变量内容)。
node = ast.parse('a = 10')
print(astor.dump_tree(node))
# Module(body=[Assign(targets=[Name(id='a')], value=Constant(value=10, kind=None), type_comment=None)], type_ignores=[])
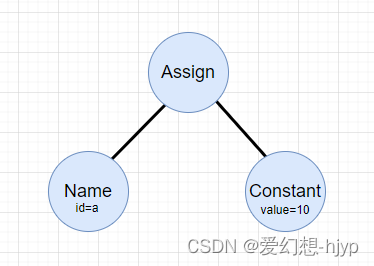
节点类型
上面的简单示例向我们展示了几种基本结点类型(Assign、Name、Constant),接下来我们将会展示其他几种常见的结点类型和示例,完整的节点类型可以查阅节点类型。大体上,我们可以把结点类型分为叶子结点类型和非叶子结点类型,比如Assign就是非叶子结点类型,Name和Constant是叶子结点类型,因为他们不会有子结点了。
ast.Assign
Assign 类型用来表示赋值语句,比如a = 10、 b = a 这样的赋值语句都是Assign结点类型,他并不是一个叶子结点,因为它的下面一般还有 Name 结点。
ast.Name
Name类型用来表示一个变量的名称,是一个叶子结点。比如对于b = a 这样的赋值语句,子结点就是两个Name。
node = ast.parse('a = b')
print(astor.dump_tree(node.body[0]))
# Assign(targets=[Name(id='a')], value=Name(id='b'), type_comment=None)
ast.Constant
表示一个不可变内容,它可以是Number 、string,只要其内容是不可变的,都是ast.Constant类型的结点,它是一个叶子结点。
node = ast.parse('a = 100')
print(astor.dump_tree(node.body[0]))
# Assign(targets=[Name(id='a')], value=Constant(value=100, kind=None), type_comment=None)node = ast.parse('a = "paddle"')
print(astor.dump_tree(node.body[0]))
# Assign(targets=[Name(id='a')], value=Constant(value='paddle', kind=None), type_comment=None)
ast.Call
表示函数的调用,比如paddle.to_tensor()。非叶子节点类型,一般包含三个属性:func、args、 keywords。
- func:代表调用函数的名称,一般是一个
ast.Name或ast.Constant类型的结点,如果是连续调用,会是一个ast.Call结点。 - args:代表函数传入的位置参数和可变参数。
- keywords:代表函数传入的关键字参数。
node = ast.parse('paddle.to_tensor(1, a = 10)')
print(astor.dump_tree(node.body[0]))# Expr(value=Call(func=Attribute(value=Name(id='paddle'), attr='to_tensor'),args=[Constant(value=1, kind=None)],keywords=[keyword(arg='a', value=Constant(value=10, kind=None))]))
对于上面的例子,我们通过可视化可以看到,顶层是一个ast.Expr类型的结点,表示一个表达式。下面是ast.Call 结点,Call 结点包含 一个ast.Attribute结点,表示调用者和调用的方法名,paddle是调用者,to_tensor是方法名;一个ast.Constant类型的args,表示函数的位置参数;一个ast.keyword,表示函数的关键字参数。
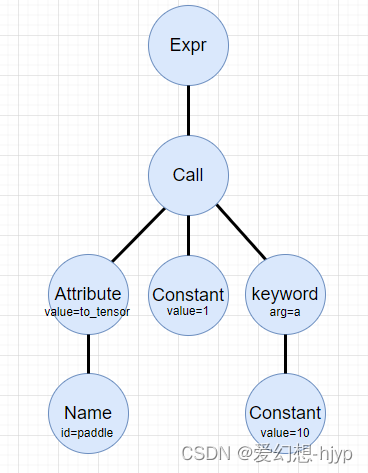
下面我们看一个比较复杂的示例,多个函数的连续调用。根据输出结果可以看到,最后的调用reshape在最外层,然后一直向内递归,子结点还是ast.Call类型的结点。
node = ast.parse('a.to_tensor(1, a = 10).reshape(1)')
print(astor.dump_tree(node.body[0]))Expr(value=Call(func=Attribute(value=Call(func=Attribute(value=Name(id='a'), attr='to_tensor'), args=[Constant(value=1, kind=None)],keywords=[keyword(arg='a', value=Constant(value=10, kind=None))]),attr='reshape'),args=[Constant(value=1, kind=None)],keywords=[]))
ast.Attribute
上面的例子中出现了ast.Attribute结点,Attribute结点可以理解为属性,是一个非叶子结点。它包含两个字段,value字段和attr字段。对于a.shape来说value指明调用者,即a;attr指明调用的方法名,即shape。
node = ast.parse('a.shape')
print(astor.dump_tree(node.body[0]))Expr(value=Attribute(value=Name(id='a'), attr='shape'))
结点的遍历
在ast模块中,可以借助继承ast.NodeVisitor类来完成结点的遍历,该类具有两种访问结点的方法,一种是针对所有结点类型通用的访问方法generic_visit(),另一种是针对某个类型结点的访问方法 visit_xxx,其中xxx代表具体的结点类型。generic_visit()函数是遍历每个结点的入口函数,随后会调用visitor()函数,获取该结点的类型,然后判断是否有遍历该类型结点的函数,如果有则调用 visit_xxx类型的方法,如果没有则调用通用generic_visit()方法。
ast源码
class NodeVisitor(object):def visit(self, node):"""Visit a node."""method = 'visit_' + node.__class__.__name__visitor = getattr(self, method, self.generic_visit)return visitor(node)def generic_visit(self, node):# 可以看到 generic_visit函数会调用visit函数,然后寻找并调用特定类型的visit函数。 """Called if no explicit visitor function exists for a node."""for field, value in iter_fields(node):if isinstance(value, list):for item in value:if isinstance(item, AST):self.visit(item)elif isinstance(value, AST):self.visit(value)def visit_Constant(self, node):value = node.valuetype_name = _const_node_type_names.get(type(value))if type_name is None:for cls, name in _const_node_type_names.items():if isinstance(value, cls):type_name = namebreakif type_name is not None:method = 'visit_' + type_nametry:visitor = getattr(self, method)except AttributeError:passelse:import warningswarnings.warn(f"{method} is deprecated; add visit_Constant",PendingDeprecationWarning, 2)return visitor(node)return self.generic_visit(node)
示例
下面是一个例子,我们定义了一个继承ast.NodeVisitor的类,并且重写了visit_attribute方法,这样在遍历到ast.Attribute结点时,会输出当前调用的属性名或方法名,对于其他类型的结点则会输出结点类型。
class CustomVisitor(ast.NodeVisitor):def visit_Attribute(self, node):print('----' + node.attr)ast.NodeVisitor.generic_visit(self, node)def generic_visit(self, node):print(node.__class__.__name__)ast.NodeVisitor.generic_visit(self, node)code = textwrap.dedent('''import paddlex = paddle.to_tensor([1, 2, 3])axis = 0y = paddle.max(x, axis=axis)'''
)
node = ast.parse(code)
visitor = CustomVisitor()
visitor.generic_visit(node)
需要注意的是,当我们重写visit_xxx函数后,一定要记得再次调用
ast.NodeVisitor.generic_visit(self, node),这样才会继续遍历整棵语法树。
结点的修改
对于结点的修改可以借助ast.NodeTransformer 类来完成,ast.NodeTransformer继承自ast.NodeVisitor类,重写了generic_visit方法,该方法可以传入一个结点,并且返回修改后的结点,从而完成语法树的修改。
示例
在该示例中,我们定义了CustomVisitor类来修改ast.Call 结点。具体来说,当遍历到Call类型的结点后,流程如下:
- 首先会调用
get_full_attr方法获取整个api名称,如果是普通方法调用,则会返回完整的调用名称,比如torch.tensor()会返回torch.tensor;如果是连续的方法调用,比如x.exp().floor(),则会返回ClassMethod.floor。 - 然后调用
ast.NodeVisitor.generic_visit(self, node),进行深度优先的修改,这样就可以一层层递归,先修改内层,再修改外层。 - 如果是普通的方法调用,则修改结点后返回;
- 如果是连续的方法调用,需要先通过
astor.to_source(node)获取前缀方法,即调用者,保留前缀方法名称的同时,修改目前的方法名后返回。具体是通过'{}.{}()'实现的。
def get_full_attr(node):# torch.nn.fucntional.reluif isinstance(node, ast.Attribute):return get_full_attr(node.value) + '.' + node.attr# x.abs() -> 'x'elif isinstance(node, ast.Name):return node.id# for example ast.Callelse:return 'ClassMethod'class CustomVisitor(ast.NodeTransformer):def visit_Call(self, node):# 获取api的全称full_func = get_full_attr(node.func)# post orderast.NodeVisitor.generic_visit(self, node)# 如果是普通方法调用,直接改写整个结点即可if full_func == 'torch.tensor':# 将 torch.tensor() 改写为 paddle.to_tensor()code = 'paddle.to_tensor()'new_node = ast.parse(code).body[0]return new_node.value# 如果是类方法调用,需要取前面改写后的方法作为 func.value if full_func == 'ClassMethod.floor':# 获取前缀方法作为 func.valuenew_func = astor.to_source(node).strip('\n')new_func = new_func[0: new_func.rfind('.')]# 将 floor() 改写为 floor2()code = '{}.{}()'.format(new_func, 'floor2')new_node = ast.parse(code).body[0]return new_node.value# 其余结点不修改return nodecode = textwrap.dedent('''import torchx = torch.tensor([1, 2, 3])x = x.exp().floor()'''
)
node = ast.parse(code)
visitor = CustomVisitor()
node = visitor.generic_visit(node)
result_code = astor.to_source(node)
print(result_code)
参考链接
https://blog.csdn.net/ThinkTimes/article/details/110831176?ydreferer=aHR0cHM6Ly9jbi5iaW5nLmNvbS8%3D
https://greentreesnakes.readthedocs.io/en/latest/
https://github.com/PaddlePaddle/PaConvert