网站 php 源码自己建网站还是淘宝
为了进行核心态和用户态两种状态的切换,引入了中断机制。
中断是计算机系统中的一种事件,它会打断CPU当前正在执行的程序,转而执行另一个程序或者执行特定的处理程序。中断可以来自外部设备(如键盘、鼠标、网络等)、软件(如操作系统或应用程序)或者由CPU内部产生(如指令错误、内存访问错误等)。
异常是指在程序执行过程中出现的一些不正常情况,如除零错误、内存访问越界、非法指令等。当异常发生时,CPU会立即中断当前程序的执行,并根据异常类型跳转到相应的异常处理程序进行处理。
总的来说,中断和异常都是计算机系统中用来处理突发事件和错误情况的机制,它们可以保证系统的稳定性和可靠性。
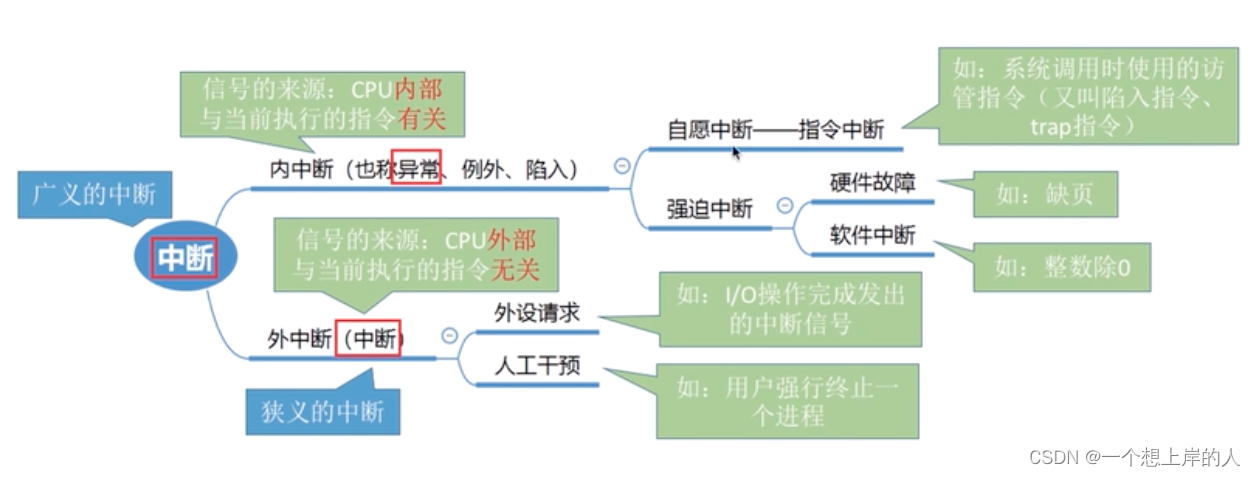
一、中断(外中断)
来自于CPU执行指令之外的事件发生导致中断,例如I/O中断,时钟中断等。
中断处理过程(408重要常考点!)
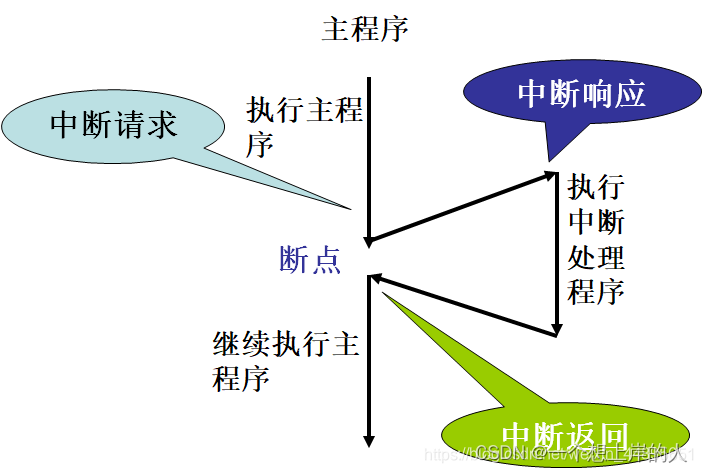
第一部分由中断隐指令(硬件)完成:
1. 关中断
2. 保存断点
3. 中断服务程序寻址
第二部分由中断服务程序(软件)完成:
4.保存现场和屏蔽字
5.开中断
6.执行中断服务程序
7.关中断
8.恢复现场和屏蔽字
9.开中断
10.中断返回
二、异常(内中断)
在操作系统中,异常(Exception)(也称内中断或软中断)通常是指由程序执行过程中的错误或异常引起的中断。当程序出现异常时,操作系统需要采取相应的措施来保证系统的稳定性和安全性。
它们可以由以下几种情况触发:
-
算术异常:当程序进行算术运算时,如除以零或溢出等错误情况发生时,会触发算术异常。
-
内存访问异常:当程序试图访问不存在的内存地址、非法的内存操作或访问受保护的内存区域时,会触发内存访问异常。
-
指令异常:当程序执行非法或未定义的指令时,会触发指令异常。
-
栈异常:当程序的函数调用堆栈出现错误或溢出时,会触发栈异常。
内中断的处理通常由操作系统提供的异常处理机制来处理。当发生内中断时,操作系统会暂停当前正在执行的程序,并跳转到相应的异常处理程序进行处理。异常处理程序可以采取一系列的措施,如终止程序执行、进行错误恢复、提供错误信息等。