奢华网站模板如何创建一个自己的公众号
使用conda或anaconda的小伙伴们都知道,图形界面时不靠谱的,而在命令行下,所有的操作就会稳定很多,且极少出现问题。因此,熟记conda的命令行就变得十分有用。但对于我这样近50岁依旧奋斗在代码第一线的大龄程序员而已,要熟记所有命令行已经变得十分困难了。此文总结了常用的conda命令,一遍我需要时查阅。
环境管理
列出所有环境
conda env list
conda info --envs
创建新环境
conda create --name your_env_name python=version
在创建环境时最好指定python版本号,比如:
conda create --name my_dev_env python=3.11
这样环境创建时,会自动为你创建好相应的python环境。
也可以在创建环境时,安装特定的python包,比如:
conda create --name my_dev_env python=3.11 numpy spicy
这样环境初创时,就会预装numpy,spicy等包。
从现存的环境克隆新环境
conda create --name new_env_name --clone cur_env_name
进入/退出指定环境
conda activate env_name
conda deactivate
删除指定环境
这里使用–all参数删除环境所有相关的数据。
conda remove --name env_name --all
显示/导出环境配置
使用以下命令可以显示当前环境的配置信息,包括安装的包和版本。
conda env export
你会得到以下输出: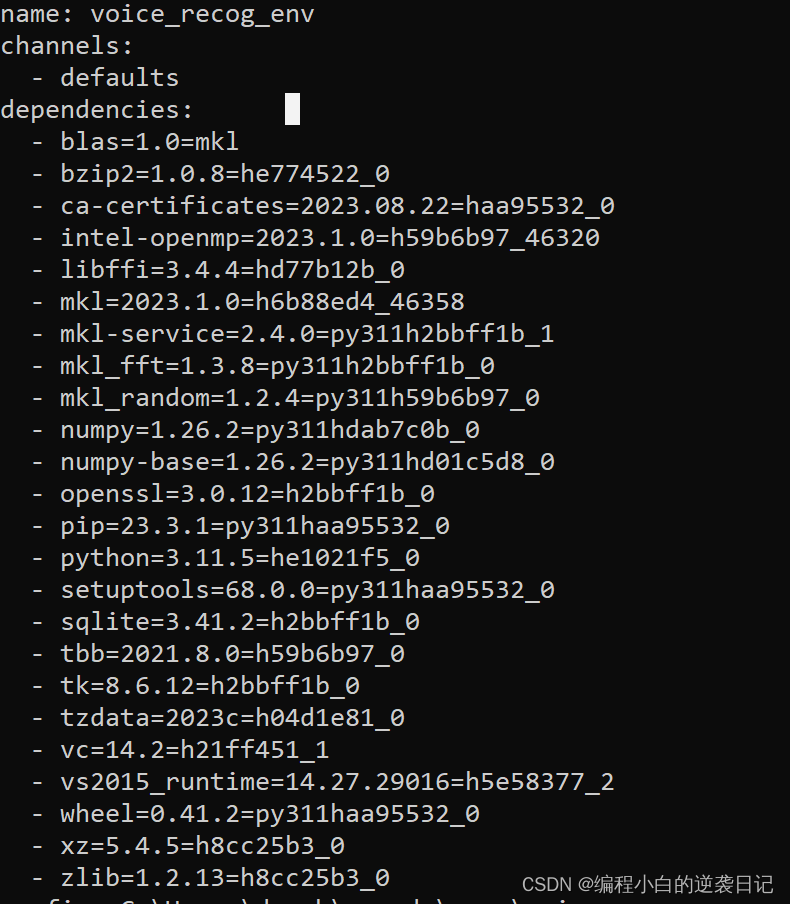
此外,你还可以将以上信息输出到文本文件,保存或分享给其他人。
conda env export > environment.yml
安装包管理
列举当前环境的所有包
以下命令会列出当前环境的包及其版本。
conda list
列举指定环境(非活跃)的包
以下命令会列出指定环境的包及其版本,该环境可以不是当前活跃的环境。
conda list -n env_name
在当前环境安装包
conda install package_name
也可以指定安装源,你可以在https://anaconda.org/conda-forge查找目前有效的安装源。
conda install -c "source path" package_name
比如说,你在conda-forge上查找numpy,就会得到以下的安装源,你可以直接复制以下的命令来安装numpy。

在指定环境(非活跃)安装包
conda install -n env_name package_name
其他conda命令
获取conda的版本
conda --version
或者
conda -V
查看conda命令帮助
conda --help
或
conda -h
查看特定命令的帮助
以下命令查看conda update的帮助信息或conda remove的帮助信息。
conda update --help
conda remove --help