网站技术建设方案十大购物网站排行榜
0、vue2和vue3对比
| 框架版本 | API方式 | 双向绑定原理 | dom | Fragments | Tree-Shaking |
|---|---|---|---|---|---|
| vue2 | 选项式API(Options API) | 基于Object.defineProperty(监听)实现,不能双向绑定对象类型的数据【通过Object.defineProperty里面的set和get做对象劫持,在处理数组等对象类型数据时,则是重写原型方法(push、pop等方法可以被监听)】 | 每次更新diff,都是全量对比 | <template>标签里面只能有一个根节点<div>标签 | import语法引用组件:import xxx from xxx |
| vue3 | 组合式API(Composition API) | 基于Proxy(劫持)实现,能够双向绑定对象类型的数据 | 只对比有标记的,对标记部分进行更新(大大减少静态内容的对比消耗,动态内容是{{}}双向绑定的内容) | <template>标签里面支持多个根节点<div>标签(实现原理:通过虚拟节点实现) | import语法引用组件时,将全局API分块,不使用的功能不会出现在基础包中,减少打包体积:import {aaa} from xxx |
0.1 vue3新特性:
- 重写双向数据绑定
- VDOM性能瓶颈
- Fragments:增加了Suspense teleport和多v-model用法
- Tree-Shaking的支持:在保持代码运行结果不变的情况下,去除无用的代码
- 组合式API(Composition API)
- setup语法糖
0.2 vue3的三种书写风格
- Options API
- setup
- setup 语法糖
// 第一种书写风格:Options API
<template>
</template><script>
export default{data() {return{// 数据}},methods: {}
}
</script><style>
</style>// 第二种书写风格setup
<template><div>{{a}}</div>
</template><script>
setup() {const a = 1// 变量需要手动return才能在dom中使用return{a}
}
</script><style>
</style>// 第三种书写风格setup语法糖(后+lang选择使用是js语言)
<template><div>{{a}}</div>
</template><script setup lang="ts">
const a:number = 1
</script><style>
</style>
1、vue语法
vue语法:
- 插值语法:{{}}
- 指令语法:v-
1.1 插值语法
<template><div><p>{{data}}</p></div>
</template><script setup lang="ts">
const data = {name: '张三',age: 30,like: '吃饭'
}
</script><style scoped>
</style>1.2 vue指令
v-开头的都是vue内置指令
v-text 用来显示文本
v-html 用来展示富文本(支持标签,如<span>xxx</span>,不支持组件,如<组件名>xxx</组件名>)
v-if 用来控制元素的显示隐藏(切换真假DOM,false时注释掉dom节点)
v-else-if 表示 v-if 的v-else-if 可以链式调用
v-else v-if条件收尾语句
v-show 用来控制元素的显示隐藏(false时将节点设置不可见,display:none block Css切换,性能比v-if高)
v-on 简写@ 用来给元素添加/绑定事件(v-on:click语法糖简写@click)
v-bind 简写:用来绑定元素的属性Attr(v-bind:id语法糖简写:id)
v-model 双向绑定
v-for 用来遍历元素
v-on 修饰符 冒泡案例
v-once 性能优化只渲染一次
v-memo 性能优化会有缓存
1.2.1 点击事件:动态事件类型切换
// 动态事件切换
<template>// 静态事件<button @click="clickBtn">按钮点击</button>// 动态事件(动态事件切换)<button @[event]="clickBtn">按钮点击</button></template><script>
// const event = "click" // @[event]等于@click
const event = "doubleClick" // @[event]等于@doubleClick
const clickBtn = ()=>{console.log("点击按钮了……")
}
</script>
1.2.2 点击事件:阻止点击冒泡
点击冒泡:当父级节点和子级节点都有点击事件时,点击子级节点也会触发父级节点的点击事件
// 动态事件切换
<template><div @click="parentClick"><button @[event].stop="clickBtn">按钮点击</button></div>
</template><script>
const parentClick = ()=>{console.log("点击了父级")
}
// const event = "click" // @[event]等于@click
const event = "doubleClick" // @[event]等于@doubleClick
const clickBtn = ()=>{console.log("点击按钮了……")
}
</script>
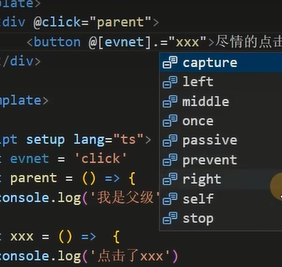
| 属性 | 作用 |
|---|---|
| @[event].stop | 阻止点击冒泡(触发父级节点的点击事件),但是:对单击事件有效,对双击事件无效 |
| @[event].prevent | 阻止提交表单 |
| @[event].once | 只触发一次,后面再点击多少次都不会触发 |
| @[event].capture | |
| @[event].middle | |
| @[event].left | |
| @[event].right | |
| @[event].passive | |
| @[event].self |
1.2.3 v-bind 绑定元素属性
绑定id、class、style……
<template><div :id="id"><p :style="style">段落段落段落</p><button :class="['a', 'b']" @click.middle="clickBtn()">子1按钮</button><button :class="['a']" @[event].passive="clickBtn()">子2按钮</button></div>
</template><script setup>
// 事件
const event = "click" // @[event]等于@click
const clickBtn = ()=>{console.log("点击按钮了……")
}// 属性
const id = "myid"
const style = {color: 'green',border: '1px solid green'
}
</script><style scoped>
#myid{background-color: #ccc;
}
.a{background-color: blue;
}
.b{color: red;
}
</style>
1.2.4 v-model 绑定表单元素(ref,响应式,双向绑定)
响应式的数据:双向绑定(通过ref和reactive)
v-model can only be used on <input>, <textarea> and <select> elements.
<template><div><input v-model="data" type="text"/><p>{{data}}</p></div>
</template><script setup>
import {ref} from 'vue'// 双向绑定(通过ref和reactive)
const data = ref('测试内容')
</script><style scoped>
</style>


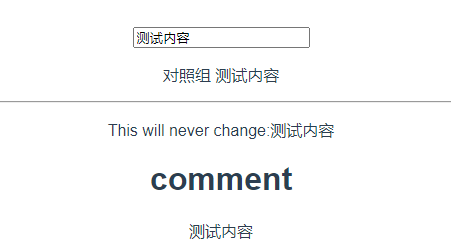
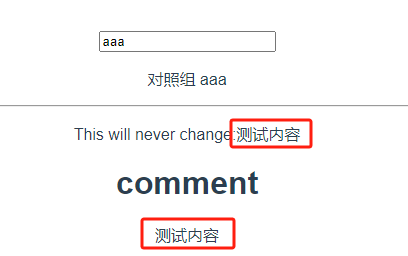
1.2.5 v-once 单次渲染【基本数据类型】(待完善)
v-once:仅渲染元素和组件一次,并跳过之后的更新
在随后的重新渲染,元素/组件及其所有子项将被当作静态内容并跳过染。这可以用来优化更新时的性能。
<template><div><!-- 基本数据类型 --><input v-model="msg" type="text"/><!-- 对照组 --><p>对照组 {{msg}}</p><hr /><!-- v-once 实验组 --><!-- 单个元素 --><p v-once>This will never change:{{msg}}</p><!-- 带有子元素的元素 --><div v-once><h1>comment</h1><p>{{msg}}</p></div><!-- 待完善 --><!-- 组件 --><!-- <A v-once :comment="msg" /> --><!-- v-for指令 --><ul><li v-for="i in list" v-once>{{i}}</li></ul></div>
</template><script setup lang="ts">
import {ref} from 'vue'
// import A from 'A.vue' // 报错
// import B from 'B.vue'const msg = ref('测试内容')
const list:string[] = ['春', '夏', '秋', '东']
</script><style scoped>
</style>
1.2.6 v-memo 单次渲染【数组】(待完善)
<template><div><!-- v-memo 处理对象数据类型 --><!-- v-for指令 --><p v-for="(item, index) in list">对照组 {{index}}--{{item}}</p><hr /><p v-for="(item, index) in list" v-memo="index == 2">v-memo组 {{index}}--{{item}}</p><!-- 组件 --><!-- <A v-once :comment="msg" /> --></div>
</template><script setup lang="ts">
import {ref, computed} from 'vue'
// import A from 'A.vue'
// import B from 'B.vue'const msg = ref('测试内容')
let list = ref(['春', '夏', '秋', '冬'])// 模拟异步更新
// 定时刷新数据函数-----------还没有写出来,报错
const timer = ref(0)
const index = ref(0)
let count = 1
let list = computed({get() {},set(newVal) {console.log("count: ", count++)list = ['赵', '钱', '孙', '李']console.log(list)}
})
// setTimeout(changeData, 3000)
// setTimeout(changeData, 3000)
// setTimeout(changeData, 3000)
// setInterval(changeData, 3000)</script><style scoped>
</style>1.2.7 v-for 遍历
<template><div><input v-for="(item, index) in data" type="text" value="item"/><p :key="index" v-for="(item, index) in data">{{index}}--{{item}}</p></div>
</template><script setup lang="ts">
import {ref} from 'vue'const data:string[] = ['春', '夏', '秋', '东']
</script><style scoped>
</style>

从生成的dom结构来看,使用v-for的标签效果是:循环生成多个完整标签内容(标签+样式+数据),而不仅仅是生成“一个完整标签+多条数据”
2、虚拟dom和diff算法
虚拟DOM就是通过JS来生成一个AST节点树(抽象语法树)
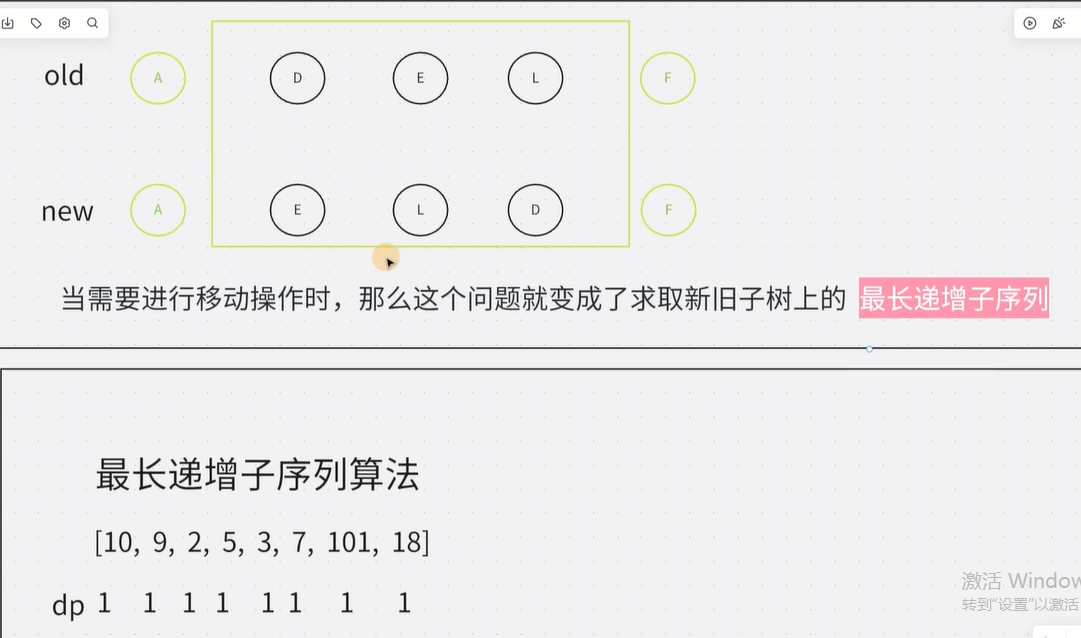
vue3的diff算法:分为三类
- 无key(三步)
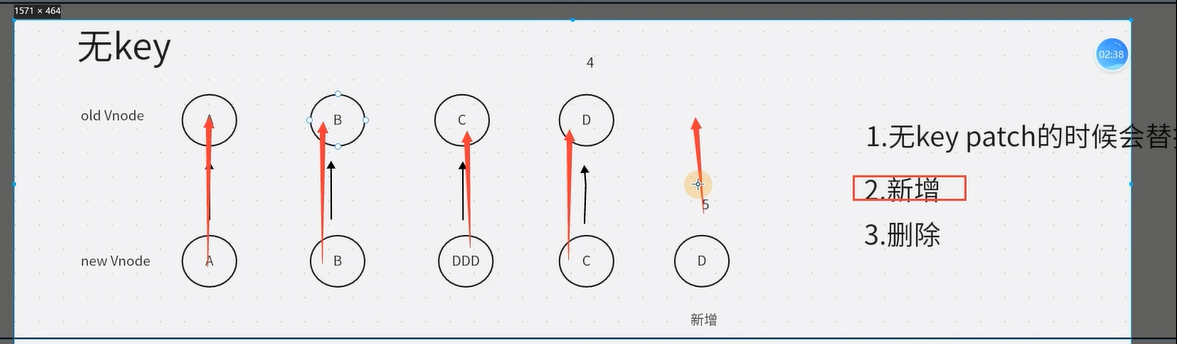
- 有key(五步)
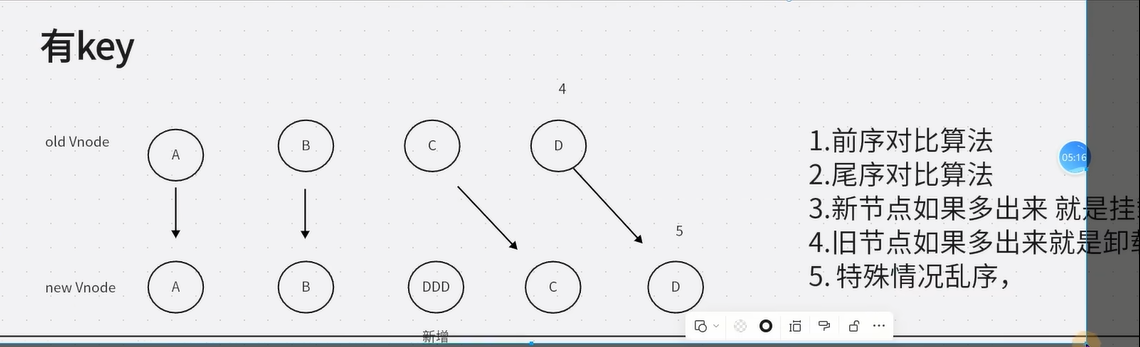
- 前序+尾序
- 乱序(最长递增子序列)

3、Ref 全家桶
- ref:深层次响应式
- shallowRef:浅层次响应式
- isRef:判断是否是ref对象,返回值true或false
- triggerRef:强制视图更新
- customRef:自定义ref
3.1 响应式:ref 、shallowRef、triggerRef 或 reactive
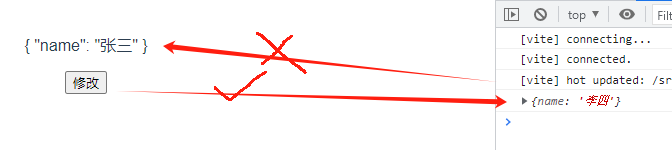
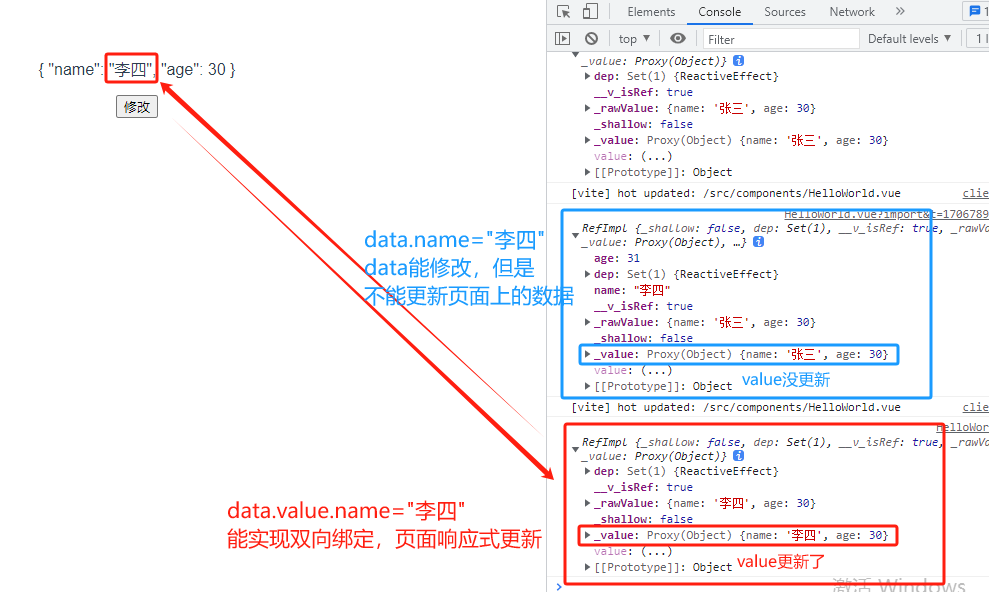
(1)非响应式:修改data之后,页面数据不更新
<template><div><p>{{data}}</p><button @click="clickBtn()">修改</button></div>
</template><script setup lang="ts">
let data = {name: "张三"}
const clickBtn = ()=>{data.name = "李四"console.log(data)
}
</script>
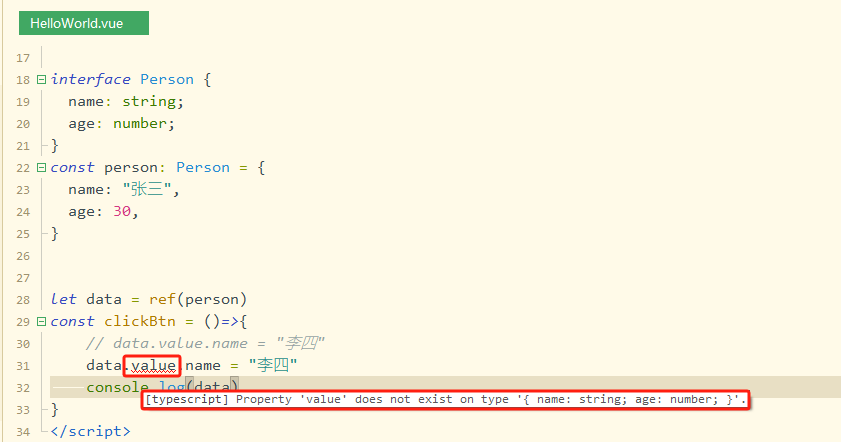
(2)响应式(利用ref双向绑定):修改data之后,页面数据也更新
<template><div><p>{{data}}</p><button @click="clickBtn()">修改</button></div>
</template><script setup lang="ts">
import {ref} from 'vue'
let data = ref({name: "张三"}) // 使用ref
const clickBtn = ()=>{data.value.name = "李四" // 通过value更新console.log(data)
}
</script>
编辑器报错,但能用(不知道HBuilderX为什么报错,B站老师的vscode就没有报错)
(3)响应式:shallowRef
<template><div><p>{{data1}}</p><p>{{data2}}</p><button @click="clickBtn1()">修改(Ref)</button><button @click="clickBtn2()">修改(shallowRef)</button></div>
</template><script setup lang="ts">
import {ref} from 'vue'let data1 = ref({name: "张三"})
let data2 = ref({name: "张三三"})
const clickBtn1 = ()=>{data1.value.name = "李四" // value.name = console.log(data1)
}
const clickBtn2 = ()=>{data2.value = {name: "李四四"} // value = console.log(data2)
}
</script>
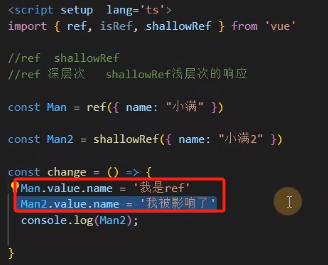
3.2 ref、shallowRef、triggerRef
ref、shallowRef 不能同时使用(在一个事件中),shallowRef 会被影响,即使写成xxx.value.name=xxx也会被改变,造成页面(视图)的更新
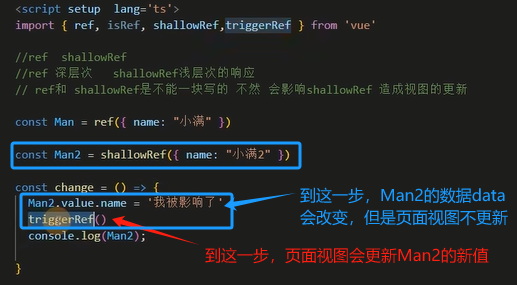
triggerRef 强制更新,shallowRef 会被影响,由于 ref 底层调用了 triggerRef,所以 ref、shallowRef 同时使用时 shallowRef 会被影响
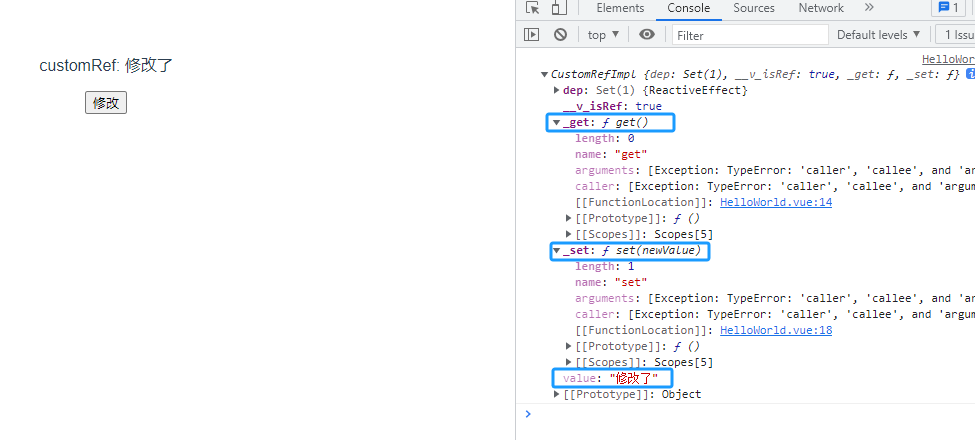
3.3 customRef(自定义ref)
<template><div><p>customRef: {{obj}}</p><button @click="clickBtn()">修改</button></div>
</template><script setup lang="ts">
import {customRef} from 'vue'function MyRef(value){let timer = nullreturn customRef((track,trigger)=>{return{get(){track()return value},set(newValue){// 不防抖,每次点击clickBtn都会触发(然而实际上只更新一次,因为clickBtn中修改每次都是同一个值,并不是变化的)// console.log("触发了")// value = newValue// trigger()// 防抖clearTimeout(timer)timer = setTimeout(()=>{console.log("触发了")value = newValuetimer = nulltrigger()}, 3000)}}})
}const obj = MyRef("王五")const clickBtn = ()=>{obj.value = "修改了"console.log(obj)
}
</script>
3.5 reactive【绑定表单场景中使用较多(?)】
ref、reactive 区别:
- ref 支持所有数据类型,reactive 支持引用类型数据Array、Object、Map、Set)
- ref 取值、赋值都需要加上
.value,reactive 不用
基础版例子
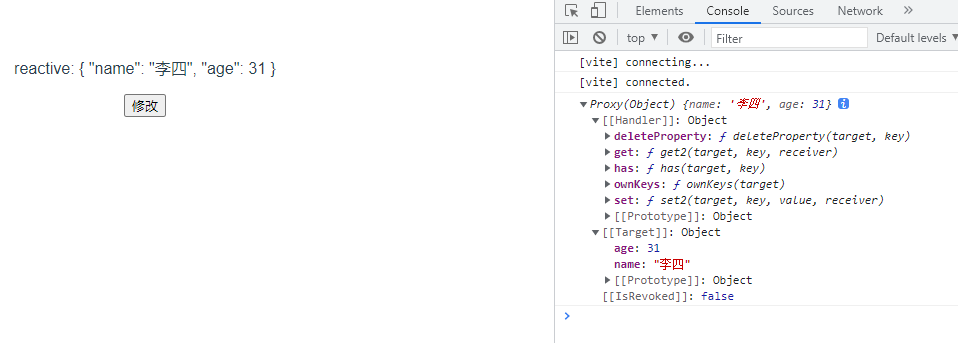
<template><div><p>reactive: {{form}}</p><button @click="clickBtn()">修改</button></div>
</template><script setup lang="ts">
import {reactive} from 'vue'type M = {name: string,age: number
}
let form = reactive<M>({name: "张三",age: 30
})const clickBtn = ()=>{form.name = "李四"form.age = 31console.log(form)
}
</script>
reactive 绑定数组,响应式更新视图
<template><div><ul><li v-for="item in list">{{item}}</li></ul><button @click="clickBtn()">添加</button></div>
</template><script setup lang="ts">
import {reactive} from 'vue'// let list = [] // 非响应式,不会更新视图
let list = reactive([]) // 响应式,动态更新视图
// let list = reactive<string []>([]) // 添加泛型(字符串数组类型)const clickBtn = ()=>{list.push("item")console.log(list)
}
</script>

异步请求场景模拟,不破坏响应式的数据更新方式示例。解决方案:数组+push+解构
<template><div><ul><li v-for="item in list">{{item}}</li></ul><button @click="clickBtn()">添加</button></div>
</template><script setup lang="ts">
import {reactive} from 'vue'// let list = [] // 非响应式,不会更新视图
let list = reactive([]) // 响应式,动态更新视图
// let list = reactive<string []>([]) // 添加泛型(字符串数组类型)// 模拟异步请求,更新数据
const clickBtn = ()=>{setTimeout(()=>{const res = ['one', 'two', 'three'] // 模拟后端返回数据// list = res // 这样赋值,list数据能更新,但是页面视图不会更新// 因为reactive是Proxy代理的对象,直接赋值会覆盖代理对象,破坏响应式方案// 解决方案list.push(...res) // 数组解构console.log(list)}, 300)
}
</script>

解决方案二:对象+数组作为对象的一个属性+直接修改对象的数组属性
<template><div><ul><li v-for="item in list.arr">{{item}}</li></ul><button @click="clickBtn()">添加</button></div>
</template><script setup lang="ts">
import {reactive} from 'vue'// 对象+
let list = reactive<{arr:string[]}>({arr: []
}) // 响应式,动态更新视图// 模拟异步请求,更新数据
const clickBtn = ()=>{setTimeout(()=>{const res = ['one', 'two', 'three'] // 模拟后端返回数据// list = res // 这样赋值,list数据能更新,但是页面视图不会更新// 因为reactive是Proxy代理的对象,直接赋值会覆盖代理对象,破坏响应式方案// 解决方案list.arr = resconsole.log(list)}, 300)
}
</script>

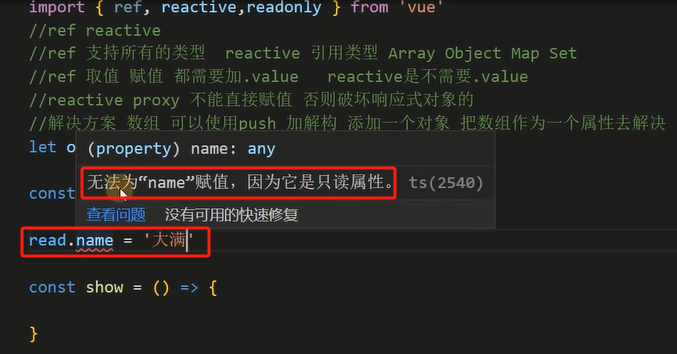
3.6 readonly
把 reactive 的值变成只读
但是 readonly 会受原始变量更新的影响
<script setup lang="ts">
import {reactive} from 'vue'let obj = reactive({name: '张三'})
let obj_read = readonly(obj)
// 不能修改只读属性的值
obj_read.name = '李四' // 编译报错:obj_read 是只读属性
// 能修改原始变量的值
obj.name = '李四'
// 这里,打印 obj、obj_read,发现都会变成'李四'(readonly 会受原始变量更新的影响)
</script>
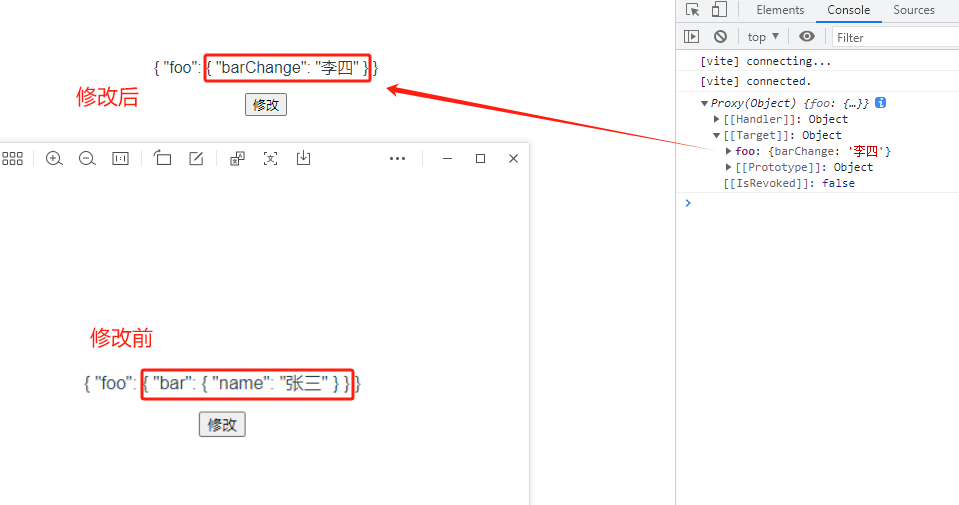
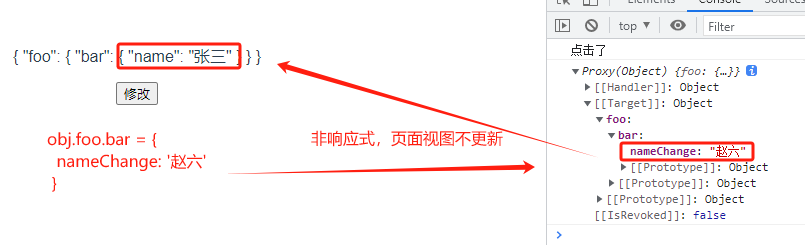
3.7 shallowReactive
<template><div><p>{{obj}}</p><button @click="clickBtn()">修改</button></div>
</template><script setup lang="ts">
import {reactive, shallowReactive} from 'vue'let obj:any = shallowReactive({foo: { // 外层bar: { // 二层name: '张三' // 三层}}
})
const clickBtn = ()=>{console.log("点击了")// 修改外层【正确修改】obj.foo = {barChange: '李四'}// 【错误修改】// 修改二层// obj.foo.bar = {// nameChange: '赵六' // 非响应式// }// obj.foo.bar.value = {// nameChange: '赵六' // 追加元素// }// 修改最内层(三层)// obj.foo.bar.name = '李四' // 非响应式,页面视图不更新// 修改obj// obj = { // 非响应式,页面视图不更新// fooChange: '王五'// }// obj.value = { // 响应式;相当于追加一个元素:value:{fooChange: '王五'}// fooChange: '王五'// }// console.log(obj)
}
</script><style scoped>
</style>修改外层【正确修改】:
修改二层、三层都是非响应式:
修改obj:

3.8 shallowRef、shallowReactive
相同:shallowReactive 也是浅层次响应式,与 shallowRef 会被 ref 影响相同,shallowReactive 也会被 reactive 影响
区别:
shallowRef 实现响应式需要通过.value修改数据,shallowReactive 不需要
// shallowRef
let data = ref({name: "张三"})
const clickBtn1 = ()=>{data.value.name = "李四" // 方式一 value.name = data.value = {name: "李四四"} // 方式二 value = console.log(data)
}// shallowReactive
let obj:any = shallowReactive({foo: { // 外层bar: { // 二层name: '张三' // 三层}}
})
const clickBtn1 = ()=>{obj.foo = {barChange: '李四'}
}
4、to 全家桶
- toRef:将普通数据
转成ref对象(响应式),然后响应式修改对象的值(转成ref对象,修改值需要加.value)。只能修改响应式对象的值。非响应式对象的data会改变,但是视图不会改变。接收参数:toRef(对象名, 对象属性) - toRefs:批量将数据转成ref对象(响应式),然后响应式修改对象的值
- toRaw:与toRef相反,将ref对象转成普通对象/普通类型数据,脱离Proxy代理(Proxy实现双向绑定/响应式,脱离Proxy即非响应式)。只想修改数据、不想更新视图的时候可以用toRaw
// toRef 实现响应式修改数据的值
// 转成ref对象
const like = toRef(person, 'like') // 接收参数:toRef(对象名, 对象属性)
// 响应式修改
like.value = '运动' // like是一个ref对象,所以修改值需要加.value// toRefs
const person = reactive({name: '张三',age: 30,like: '吃饭'
})
// 接收参数:对象名;返回值:对象内的所有属性名
const {name, age, like} = toRefs(person) // 解构取值
// 响应式修改
name.value = '李四'
age.value = 31
like.value = '运动'
完整例子
toRef 的例子
<template><div><p>{{person}}</p><button @click="clickBtn()">修改</button></div>
</template><script setup lang="ts">
import {reactive, toRef} from 'vue'const person = reactive({ // 实现对象类型数据的响应式,可以直接使用reactive(reactive实现对象类型数据的响应式,ref实现所有类型数据的响应式)name: '张三',age: 30,like: '吃饭'
})
const clickBtn = ()=>{const like = toRef(person, 'like') // 接收参数:toRef(对象名, 对象属性)like.value = '运动' // like是一个ref对象,所以修改值需要加.valueconsole.log('like:',like)console.log('person:',person)
}
</script>
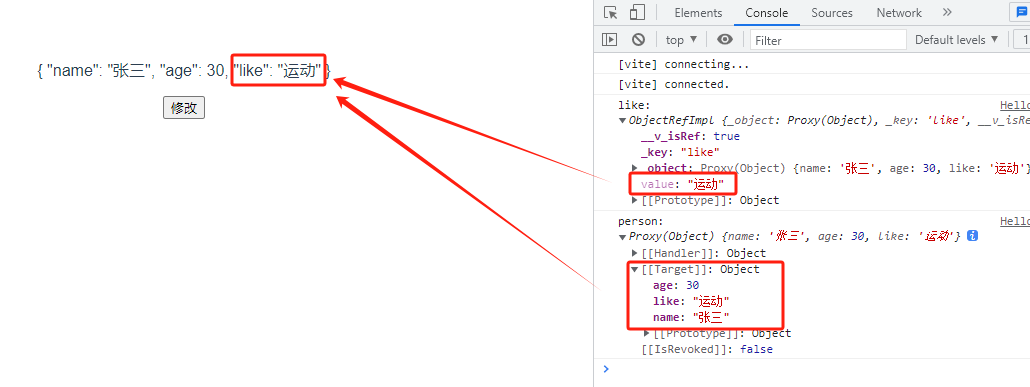
toRefs 的例子
<template><div><p>{{person}}</p><button @click="clickBtn()">修改</button></div>
</template><script setup lang="ts">
import {reactive, toRef, toRefs} from 'vue'const person = reactive({name: '张三',age: 30,like: '吃饭'
})
// toRefs实现原理:批量转成ref对象
// const toRefs = <T extends object>(object:T)=>{
// const map:any = {}
// for(let key in object){
// map[key] = toRef(object, key) // 将对象object中的属性key转成ref对象
// }
// return map // 将object内所有属性转成ref并返回
// }const clickBtn = ()=>{const {name, age, like} = toRefs(person) // 接收参数:对象名;返回值:对象内的所有属性名name.value = '李四'age.value = 31like.value = '运动'console.log('person:',person)
}
</script><style scoped>
</style>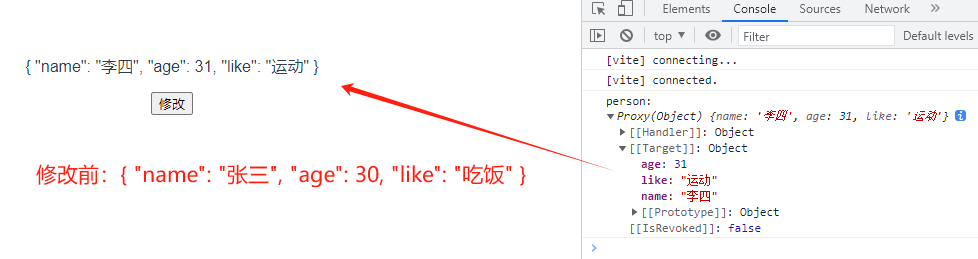
【补充】ts泛型
<script setup lang="ts">
import {ref} from 'vue'
import type {Ref} from 'vue' // 添加泛型(方式2)type Data = {name: string
}
let data1 = ref<Data>({name: "张三"}) // 添加泛型(方式1)
let data2:Ref<Data> = ref({name: "张三"}) // 添加泛型(方式2)当类型比较复杂的时候推荐使用
</script>