企业网站搜索引擎推广方法网站如何生成静态
用过element-ui的有知道,展开这个箭头无法自定义,一点办法都没有,官方根本就没提供预留任何位置给你操作。
从下面图中,可以看到有两个插槽,默认插槽和表头插槽。

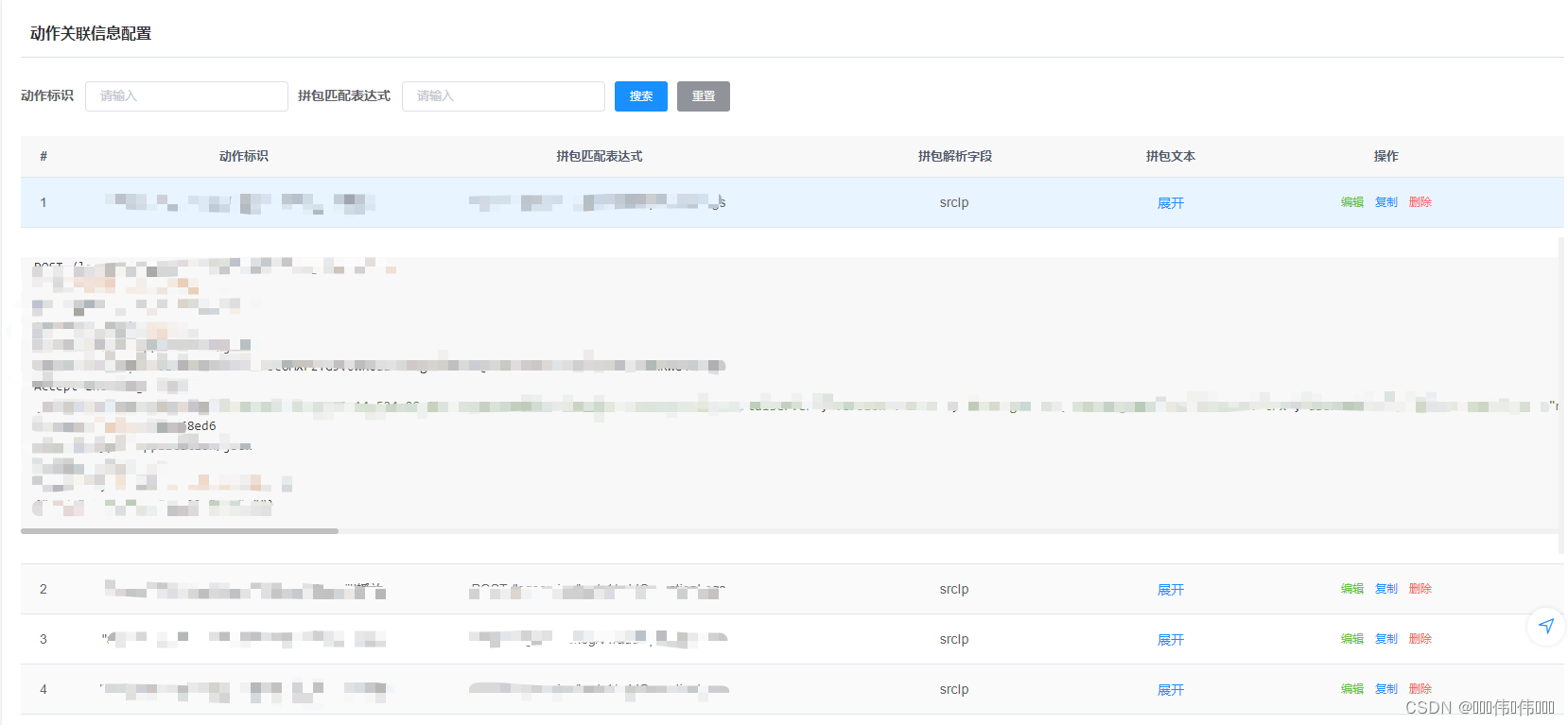
我们来扩展一个自定义插槽来实现我们想要的功能。
我这里目录如下:
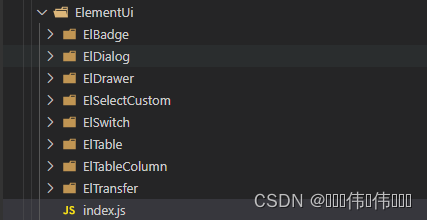
index.js 文件中(用的是模块自动导入)
const modulesFiles = require.context('@/components/ElementUi', true, /index\.vue$/)const modules = modulesFiles.keys().reduce((modules, modulePath) => {const moduleName = modulePath.replace(/^\.\/(.*)\/index\.vue$/, '$1')const value = modulesFiles(modulePath)modules[moduleName] = value.defaultreturn modules
}, {})const whiteList = ['ElTabs']export default vue => {for (let key in modules) {if (whiteList.includes(key)) continuevue.component(key, modules[key])}
}
main.js 文件中 (注意优先级)
import Element from 'element-ui'
import ElementUiCustom from '@/components/ElementUi'Vue.use(Element, { size: Cookies.get('size') || 'medium' })
Vue.use(ElementUiCustom)
找到node_modules\element-ui\packages\table 和 node_modules\element-ui\packages\table-column
文件夹,直接提取结合上面操作就能实现整体覆盖,当然需要注意删除一部分组件代码,想el-tooltip 这里面的代码是用到语法不支持想项目的编译,不过不急,删除不支持的文件导入即可。
接下来只需要找到两个位置就能实现我们需要达到我们的目的了
- 找到src\components\ElementUi\ElTable\config.js
- 约67行位置找到expand键对应的函数,最好是全替换一下,这个代码块是没显示行号,我注释标注了一下
expand: {renderHeader: function (h, { column }) {return column.label || ''},renderCell: function (h, { row, store, isExpanded }) {const classes = ['el-table__expand-icon']/* 判断行有改动 */ if (isExpanded && !this.$scopedSlots.expand) {classes.push('el-table__expand-icon--expanded')}const callback = function (e) {e.stopPropagation()store.toggleRowExpansion(row)}return (<div class={classes} on-click={callback}>/* 使用插槽 */{this.$scopedSlots.expand ? this.$scopedSlots.expand(isExpanded) : <i class="el-icon el-icon-arrow-right"></i>}</div>)},sortable: false,resizable: false,className: 'el-table__expand-column',},
再次找到src\components\ElementUi\ElTableColumn
找到setColumnRendershanshu :约134行位置,约149行位置用call调用一下。下面加了注释标注
setColumnRenders(column) {// renderHeader 属性不推荐使用。if (this.renderHeader) {console.warn('[Element Warn][TableColumn]Comparing to render-header, scoped-slot header is easier to use. We recommend users to use scoped-slot header.')} else if (column.type !== 'selection') {column.renderHeader = (h, scope) => {const renderHeader = this.$scopedSlots.headerreturn renderHeader ? renderHeader(scope) : column.label}}let originRenderCell = column.renderCell// TODO: 这里的实现调整if (column.type === 'expand') {// 对于展开行,renderCell 不允许配置的。在上一步中已经设置过,这里需要简单封装一下。/* 在这里call一下this */ column.renderCell = (h, data) => <div class="cell">{originRenderCell.call(this, h, data)}</div>this.owner.renderExpanded = (h, data) => {return this.$scopedSlots.default ? this.$scopedSlots.default(data) : this.$slots.default}} else {originRenderCell = originRenderCell || defaultRenderCell// 对 renderCell 进行包装column.renderCell = (h, data) => {let children = nullif (this.$scopedSlots.default) {children = this.$scopedSlots.default(data)} else {children = originRenderCell(h, data)}const prefix = treeCellPrefix(h, data)const props = {class: 'cell',style: {},}if (column.showOverflowTooltip) {props.class += ' el-tooltip'props.style = { width: (data.column.realWidth || data.column.width) - 1 + 'px' }}return (<div {...props}>{prefix}{children}</div>)}}return column},
重点来了,如何使用呢
<el-table-column align="center" type="expand" label="拼包文本" width="80"><template #expand><el-link type="primary" :size="layoutSize" :underline="false">展开</el-link></template><template slot-scope="{ row, column: col }"><highlight :html="row.textAfterPacket" /></template>
</el-table-column>