生物科技网站建设 中企动力北京网站建设金手指
Python支持跨平台软件开发
作为一种高级编程语言,Python 以其丰富的库和跨平台支持而备受开发人员欢迎。Python 通过将应用程序的可移植性最大化,使得开发人员可以轻松地在不同的操作系统平台上构建和部署软件。
跨平台支持
Python 支持各种不同的操作系统平台,包括 Windows、Linux、Unix、MacOS 等。这意味着开发人员可以使用一个 Python 应用程序的源代码来构建适用于多个平台的二进制文件。同时,Python 还支持大量的第三方库和框架,可大大简化应用程序的开发过程。
Python 的跨平台支持让开发人员可以从不同的平台构建应用程序,也可以将应用程序部署到各种平台上,包括云计算平台和移动设备上。这种灵活性和便利性使得 Python 成为许多开发者不可或缺的工具。
软件开发
Python 的跨平台功能使得开发人员可以在不同的平台上编写应用程序。同时,相对于其他语言,Python 写起来更加简洁、清晰易懂。Python 还提供了大量的库和框架,可以快速创建网络应用、数据库应用、科学应用等等。
这种便利性和快速开发的特性,使得 Python 成为许多开发者喜爱的编程语言。Python 提供了许多流行的框架,包括 Flask、Django、Pyramid、Tornado 等等。这些框架可以大大简化应用程序的开发过程,并提供了功能丰富的库以支持各种不同的应用程序需求。
结论
总之,Python 的跨平台支持使得它成为了许多开发人员喜欢使用的编程语言。Python 提供了丰富的库和框架,以及编写清晰、简洁的代码的能力。Python 应用程序可以被轻松地部署到各种平台上,包括云计算平台和移动设备上。无论你是一个初学者还是经验丰富的 Python 开发人员,跨平台特性都是 Python 独特的魅力之一。
最后的最后
本文由chatgpt生成,文章没有在chatgpt生成的基础上进行任何的修改。以上只是chatgpt能力的冰山一角。作为通用的Aigc大模型,只是展现它原本的实力。
对于颠覆工作方式的ChatGPT,应该选择拥抱而不是抗拒,未来属于“会用”AI的人。
🧡AI职场汇报智能办公文案写作效率提升教程 🧡 专注于AI+职场+办公方向。
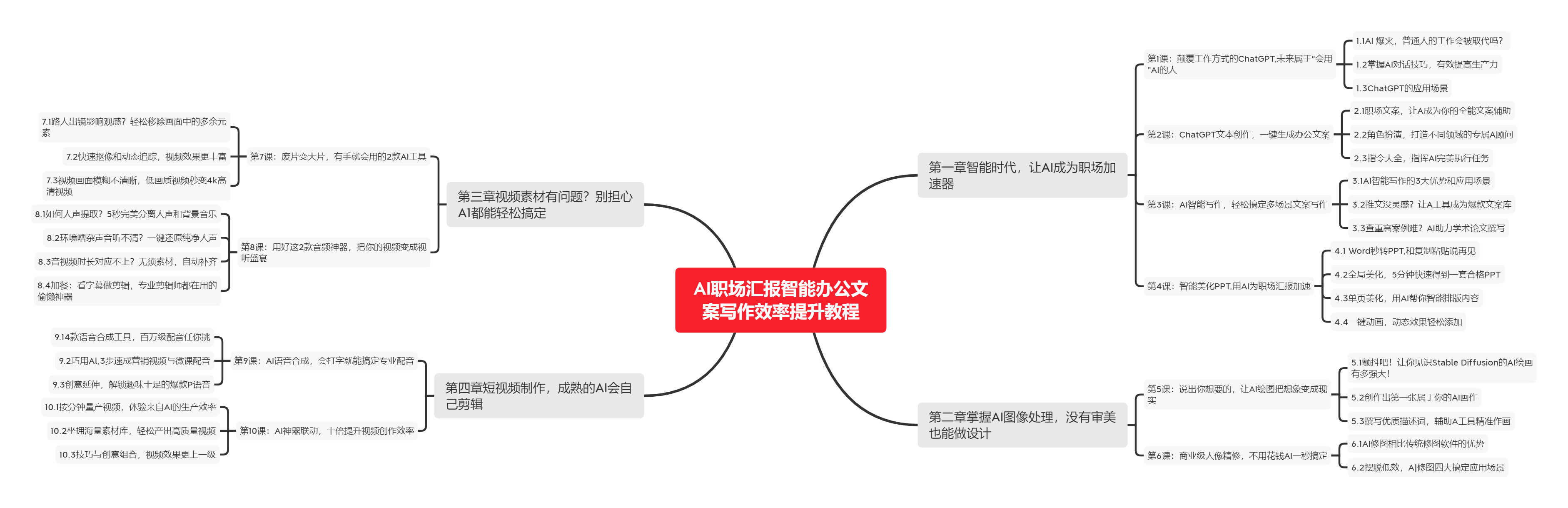
下图是课程的整体大纲

下图是AI职场汇报智能办公文案写作效率提升教程中用到的ai工具

🚀 优质教程分享 🚀
- 🎄可以学习更多的关于人工只能/Python的相关内容哦!直接点击下面颜色字体就可以跳转啦!
| 学习路线指引(点击解锁) | 知识定位 | 人群定位 |
|---|---|---|
| 🧡 AI职场汇报智能办公文案写作效率提升教程 🧡 | 进阶级 | 本课程是AI+职场+办公的完美结合,通过ChatGPT文本创作,一键生成办公文案,结合AI智能写作,轻松搞定多场景文案写作。智能美化PPT,用AI为职场汇报加速。AI神器联动,十倍提升视频创作效率 |
| 💛Python量化交易实战 💛 | 入门级 | 手把手带你打造一个易扩展、更安全、效率更高的量化交易系统 |
| 🧡 Python实战微信订餐小程序 🧡 | 进阶级 | 本课程是python flask+微信小程序的完美结合,从项目搭建到腾讯云部署上线,打造一个全栈订餐系统。 |