南京网站开发南京乐识专心国内公关公司排名
目录
- 概述
- TCP连接可靠性
- 1. 三次握手过程
- 2. 四次挥手过程
- 3. 为什么挥手需要四次?
- 传输可靠性
- TCP核心API
- TCP传输初始化配置&建立连接
- 客户端创建Socket建立连接
- 服务端创建ServerSocket监听连接
- ServerSocket 和 Socket的关系
- Socket基本数据类型传输
- 客户端数据传输
- 服务端数据接收
- TCP连接客户端、服务端完整代码
- 服务端代码:
- 客户端代码
- 执行结果
概述
-
TCP是什么
英语:Transmission Control Protocol,缩写为 TCP
TCP是传输控制协议;是一种面向连接的、可靠的、基于字节流的传输层通信协议,由IETF的RFC 793定义
与UDP一样完成第四层传输层所指定的功能与职责 -
TCP的机制
三次握手、四次挥手
具有校验机制、可靠、数据传输稳定 -
TCP能做什么
聊天消息传输、推送
单人语音、视频聊天等
几乎UDP能做的都能做,但需要考虑复杂性、性能问题
限制:无法进行广播,多播等操作
TCP连接可靠性
1. 三次握手过程
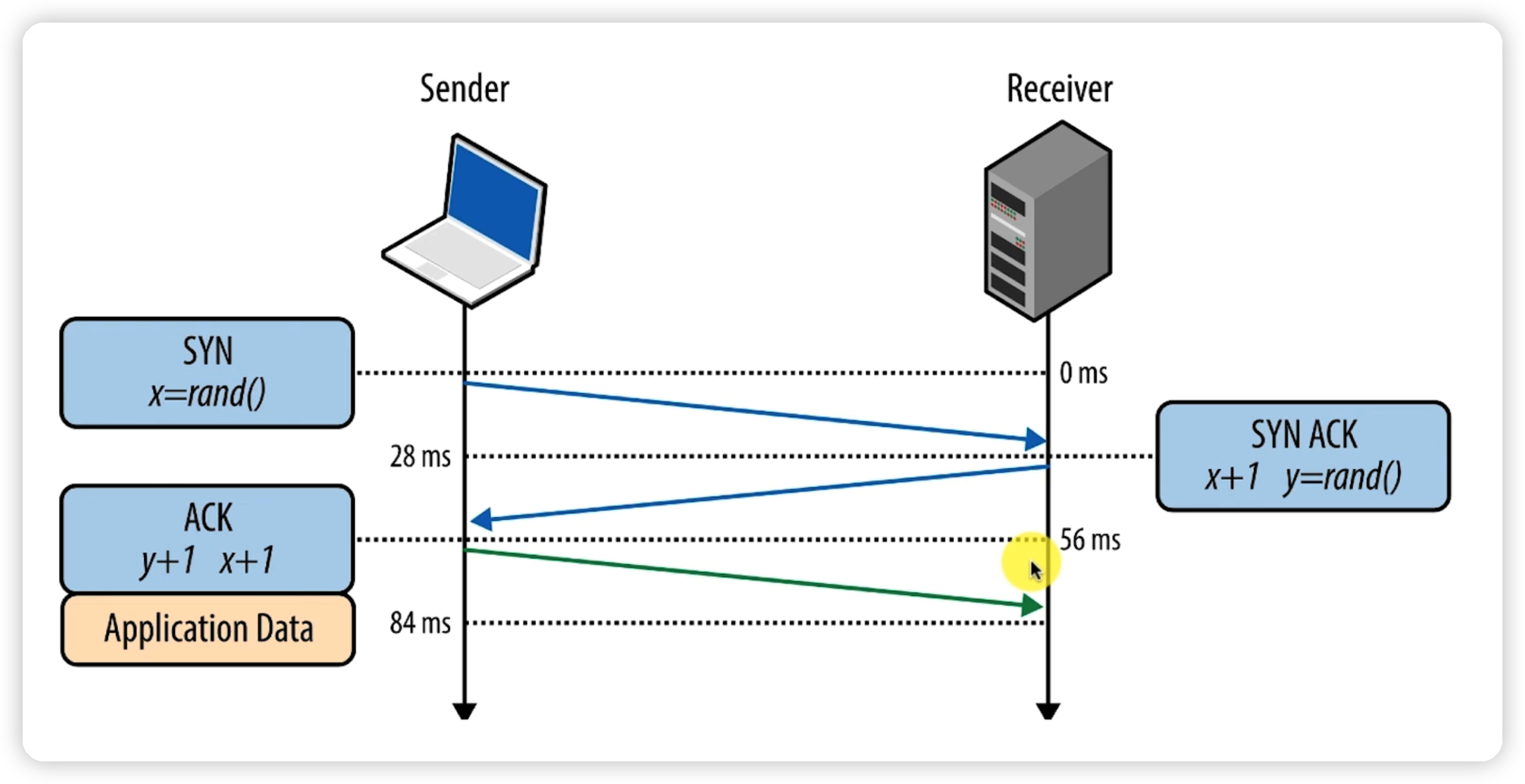
三次握手的过程包括:
第一次握手:客户端发送SYN包,携带自己的序列号。
第二次握手:服务器端回复SYN+ACK包,确认收到客户端的SYN包,并携带自己的序列号。
第三次握手:客户端回复ACK包,确认收到的SYN+ACK包,完成握手过程。
这个过程确保了后续数据的可靠传输和完整性,保障了网络通信的稳定性和可靠性。
2. 四次挥手过程
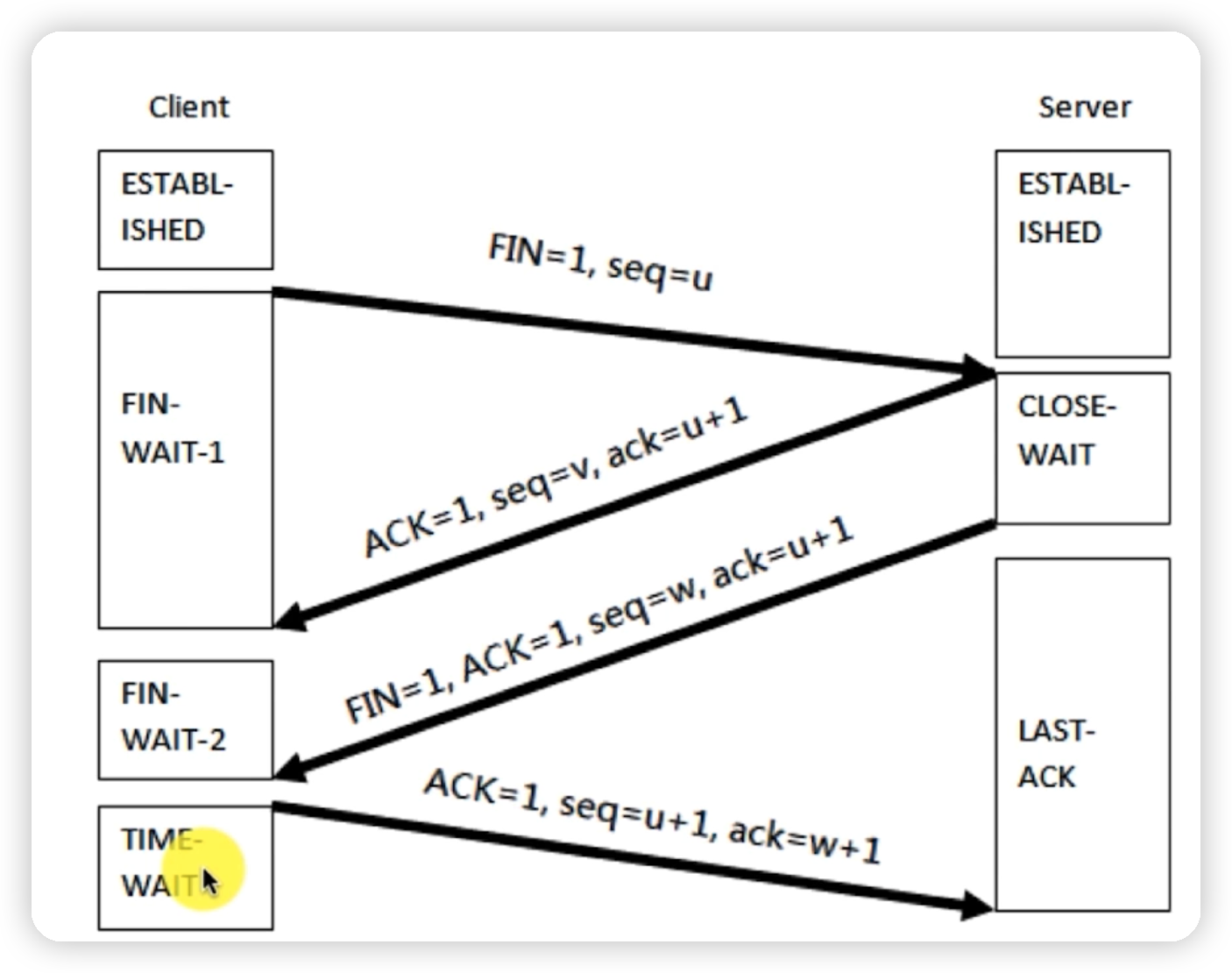
四次挥手是TCP协议中用于终止连接的过程,这个过程涉及到客户端和服务端之间发送四个数据包。由于TCP连接是全双工的,因此每个方向都必须单独进行关闭。在四次挥手中,首先进行关闭的一方将执行主动关闭,而另一方则执行被动关闭。1234
以下是四次挥手的详细步骤:
第一次挥手:客户端发送一个FIN报文,用来关闭客户端到服务器的数据传送。此时客户端进入FIN_WAIT_1状态.
第二次挥手:服务器收到FIN报文后,发送一个ACK报文作为响应,确认序号为收到序号加1。此时服务器进入CLOSE_WAIT状态。
第三次挥手:服务器完成数据发送任务后,发送一个FIN报文,用来关闭服务器到客户端的数据传送。此时服务器进入LAST_ACK状态。
第四次挥手:客户端收到FIN报文后,发送一个ACK报文作为响应,确认序号为收到序号加1。此时客户端进入TIME_WAIT状态。客户端在等待一段时间(通常为2MSL,即最大报文段寿命)后,如果没有收到服务器的任何响应,则进入CLOSE状态。
这个过程确保了双方都能正确关闭连接,避免了数据丢失。
3. 为什么挥手需要四次?
由于 TCP 的半关闭(half-close)特性,TCP 提供了连接的一端在结束它的发送后还能接收来自另一端数据的能力。
任何一方都可以在数据传送结束后发出连接释放的通知,待对方确认后进入半关闭状态。当另一方也没有数据再发送的时候,则发出连接释放通知,对方确认后就完全关闭了TCP连接。
通俗的来说,两次握手就可以释放一端到另一端的 TCP 连接,完全释放连接一共需要四次握手。
可以用下面这个例子理解:
举个例子:A 和 B 打电话,通话即将结束后,A 说 “我没啥要说的了”,B 回答 “我知道了”,于是 A 向 B 的连接释放了。但是 B 可能还会有要说的话,于是 B 可能又巴拉巴拉说了一通,最后 B 说“我说完了”,A 回答“知道了”,于是 B 向 A 的连接释放了,这样整个通话就结束了。
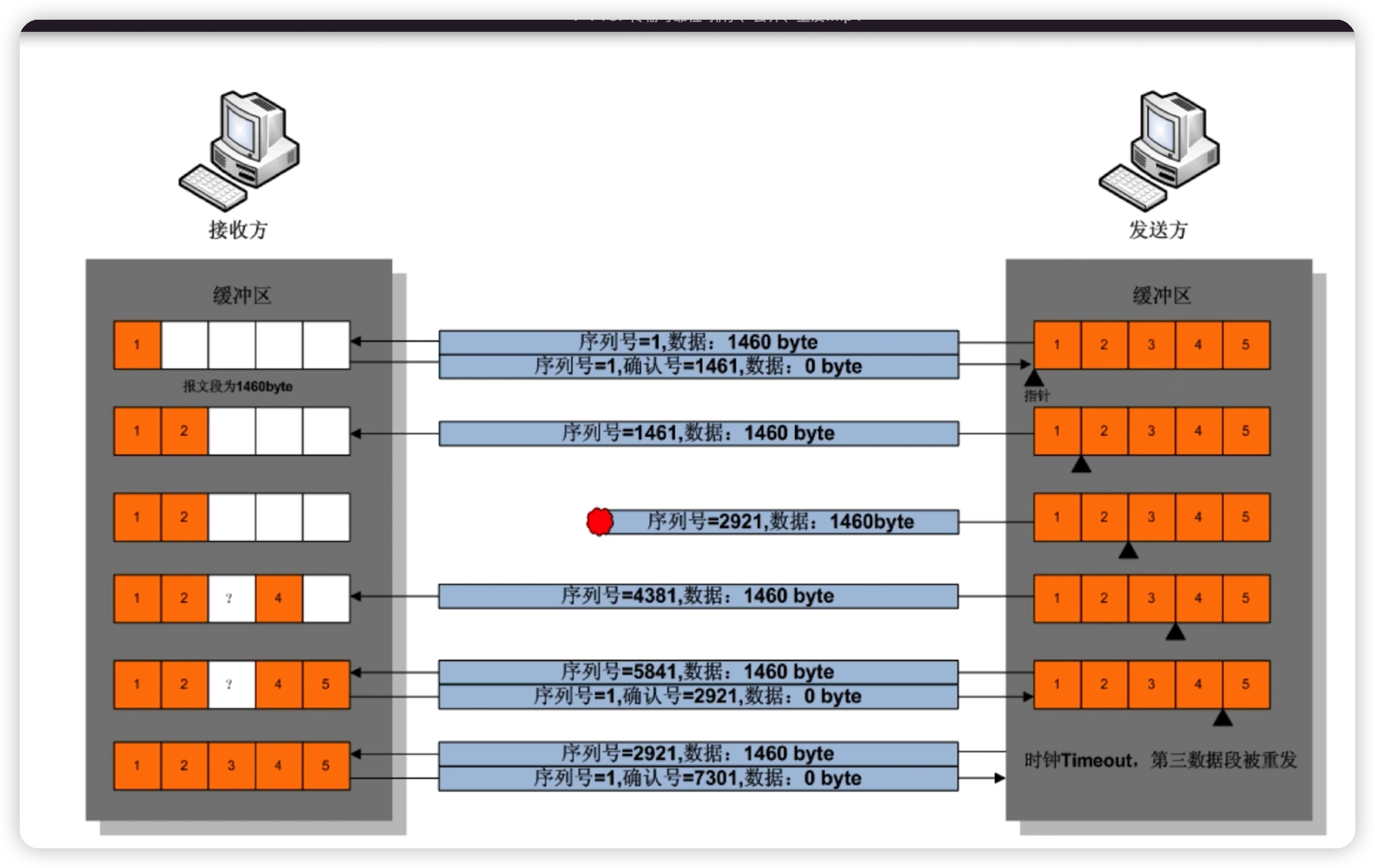
传输可靠性
- 排序、顺序发送、顺序组装
- 丢弃、超时
- 重发机制-定时器
数据传输示意图
TCP核心API
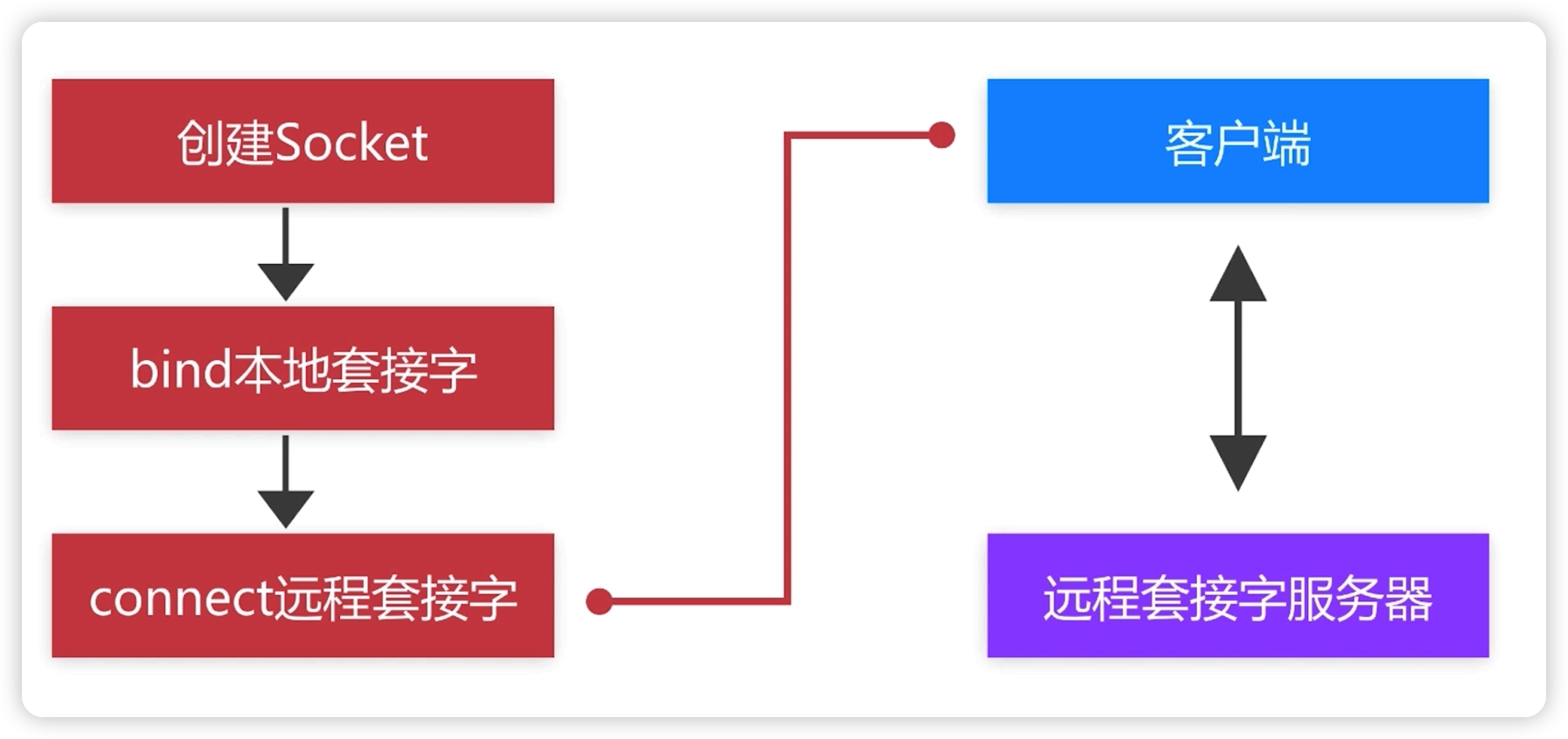
socket():创建—个Socket
bind():绑定一个Socket到一个本地地址和端口上
connect():连接到远程套接字
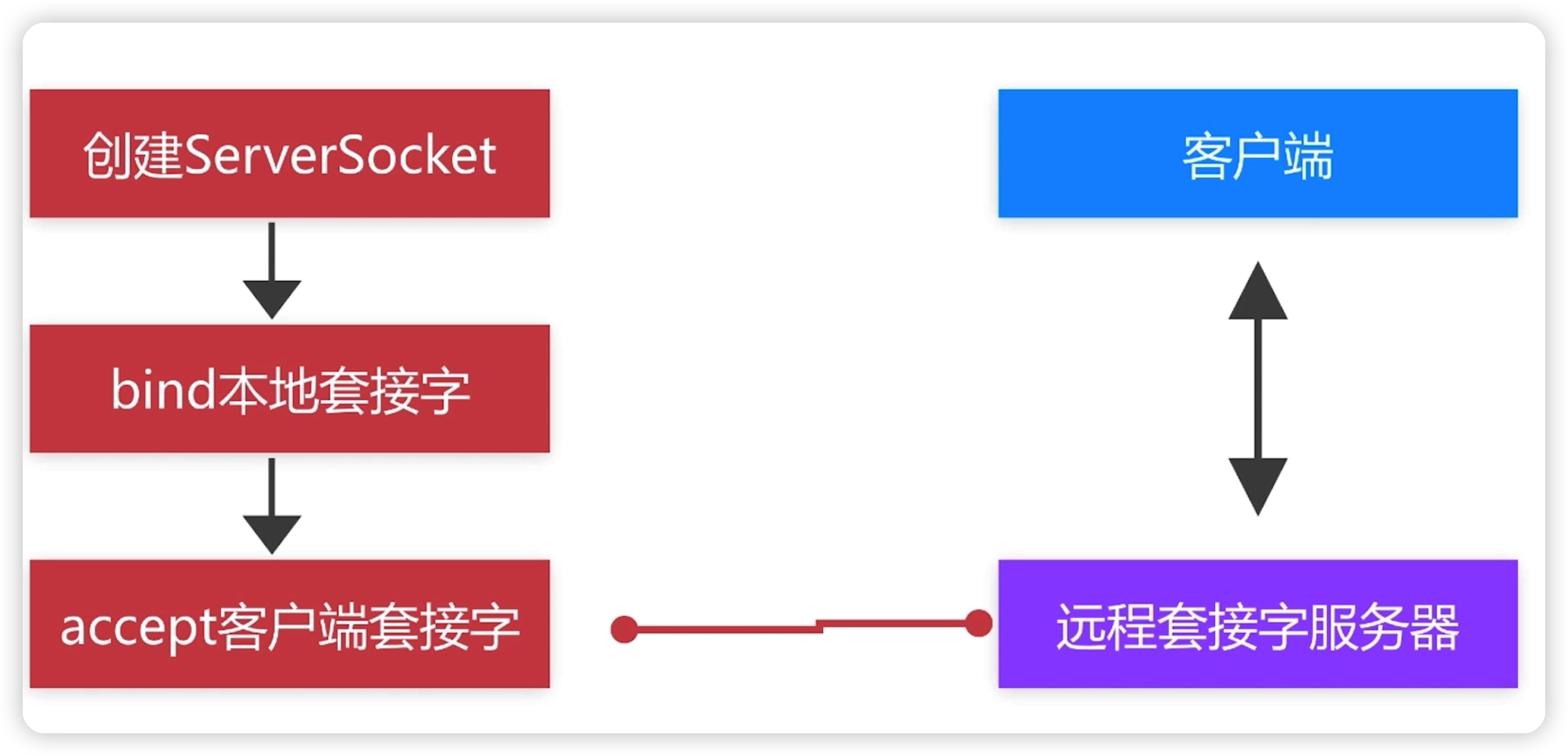
accept():接受一个新的连接
write():把数据写入到Socket输出流
read():从Socket输入流读取数据
客户端Socket创建流程:
服务端ServerSocket创建流程:
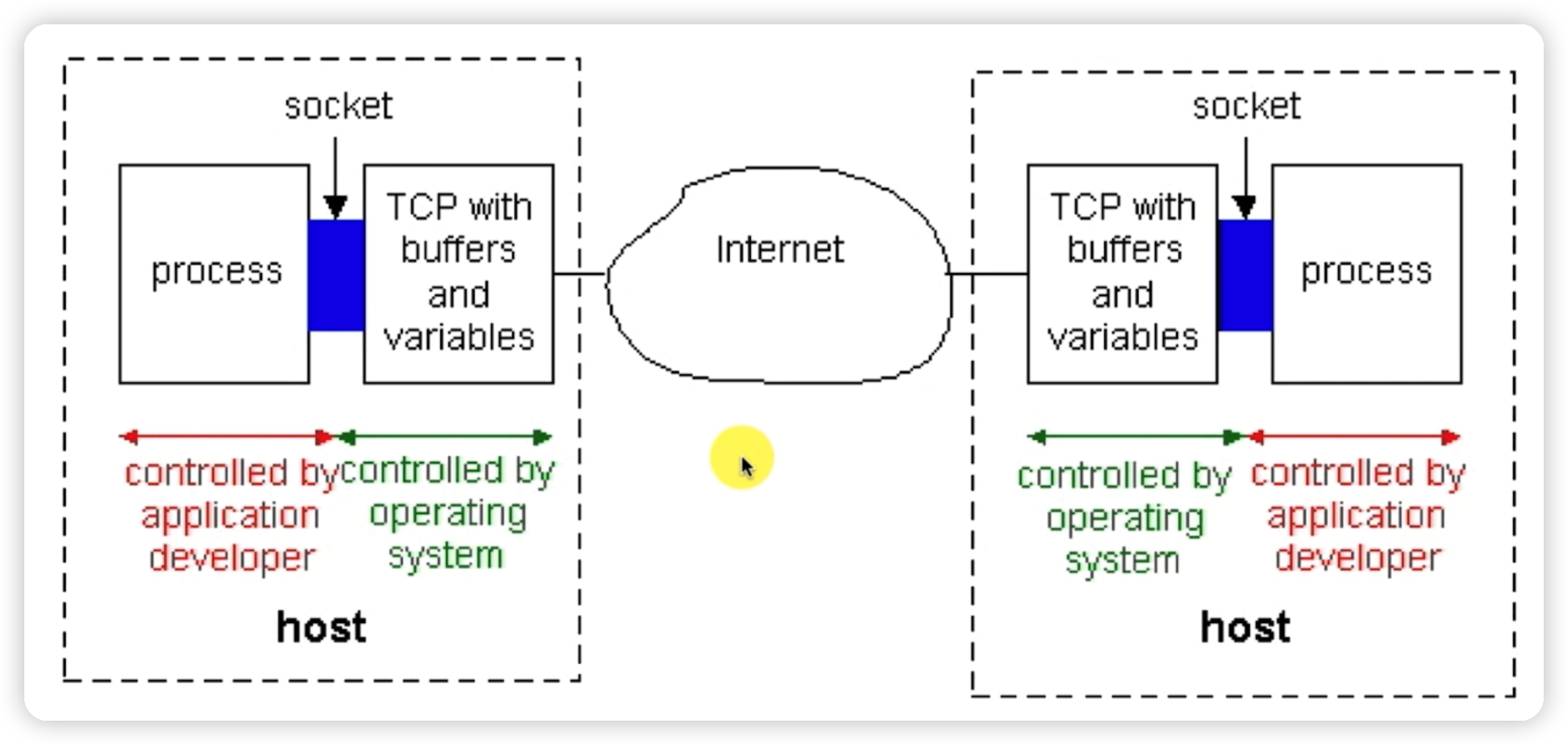
Socket和进程的关系:
TCP传输初始化配置&建立连接
- 初始化服务器TCP链接监听
- 初始化客户端发起链接操作
- 服务器Socket链接处理
客户端创建Socket建立连接
- 创建Socket基本方法和构造函数
private static Socket createSocket() throws IOException {/*// 无代理模式,等效于空构造函数Socket socket = new Socket(Proxy.NO_PROXY);// 新建一份具有HTTP代理的套接字,传输数据将通过www.baidu.com:8080端口转发Proxy proxy = new Proxy(Proxy.Type.HTTP,new InetSocketAddress(Inet4Address.getByName("www.baidu.com"), 8800));socket = new Socket(proxy);// 新建一个套接字,并且直接链接到本地20000的服务器上socket = new Socket("localhost", PORT);// 新建一个套接字,并且直接链接到本地20000的服务器上socket = new Socket(Inet4Address.getLocalHost(), PORT);// 新建一个套接字,并且直接链接到本地20000的服务器上,并且绑定到本地20001端口上socket = new Socket("localhost", PORT, Inet4Address.getLocalHost(), LOCAL_PORT);socket = new Socket(Inet4Address.getLocalHost(), PORT, Inet4Address.getLocalHost(), LOCAL_PORT);*/Socket socket = new Socket();// 绑定到本地20001端口socket.bind(new InetSocketAddress(Inet4Address.getLocalHost(), LOCAL_PORT));return socket;}
- 初始化Socket的基本配置
private static void initSocket(Socket socket) throws SocketException {// 设置读取超时时间为2秒socket.setSoTimeout(2000);// 是否复用未完全关闭的Socket地址,对于指定bind操作后的套接字有效socket.setReuseAddress(true);// 是否开启Nagle算法socket.setTcpNoDelay(true);// 是否需要在长时无数据响应时发送确认数据(类似心跳包),时间大约为2小时socket.setKeepAlive(true);// 对于close关闭操作行为进行怎样的处理;默认为false,0// false、0:默认情况,关闭时立即返回,底层系统接管输出流,将缓冲区内的数据发送完成// true、0:关闭时立即返回,缓冲区数据抛弃,直接发送RST结束命令到对方,并无需经过2MSL等待// true、200:关闭时最长阻塞200毫秒,随后按第二情况处理socket.setSoLinger(true, 20);// 是否让紧急数据内敛,默认false;紧急数据通过 socket.sendUrgentData(1);发送socket.setOOBInline(true);// 设置接收发送缓冲器大小socket.setReceiveBufferSize(64 * 1024 * 1024);socket.setSendBufferSize(64 * 1024 * 1024);// 设置性能参数:短链接,延迟,带宽的相对重要性socket.setPerformancePreferences(1, 1, 0);}
- 客户端手动连接
public static void main(String[] args) throws IOException {Socket socket = createSocket();initSocket(socket);// 链接到本地20000端口,超时时间3秒,超过则抛出超时异常socket.connect(new InetSocketAddress(Inet4Address.getLocalHost(), PORT), 3000);System.out.println("已发起服务器连接,并进入后续流程~");System.out.println("客户端信息:" + socket.getLocalAddress() + " P:" + socket.getLocalPort());System.out.println("服务器信息:" + socket.getInetAddress() + " P:" + socket.getPort());try {// 发送接收数据todo(socket);} catch (Exception e) {System.out.println("异常关闭");}// 释放资源socket.close();System.out.println("客户端已退出~");}
服务端创建ServerSocket监听连接
- 创建ServerSocket方法
private static ServerSocket createServerSocket() throws IOException {// 创建基础的ServerSocketServerSocket serverSocket = new ServerSocket();// 绑定到本地端口20000上,并且设置当前可允许等待链接的队列为50个//serverSocket = new ServerSocket(PORT);// 等效于上面的方案,队列设置为50个//serverSocket = new ServerSocket(PORT, 50);// 与上面等同// serverSocket = new ServerSocket(PORT, 50, Inet4Address.getLocalHost());return serverSocket;}
- 初始化ServerSocket配置
private static void initServerSocket(ServerSocket serverSocket) throws IOException {// 是否复用未完全关闭的地址端口serverSocket.setReuseAddress(true);// 等效Socket#setReceiveBufferSizeserverSocket.setReceiveBufferSize(64 * 1024 * 1024);// 设置serverSocket#accept超时时间// serverSocket.setSoTimeout(2000);// 设置性能参数:短链接,延迟,带宽的相对重要性serverSocket.setPerformancePreferences(1, 1, 1);}
- 监听服务端固定端口,并且接受客户端建立连接
private static final int PORT = 20000;public static void main(String[] args) throws IOException {ServerSocket server = createServerSocket();initServerSocket(server);// 绑定到本地端口上server.bind(new InetSocketAddress(Inet4Address.getLocalHost(), PORT), 50);System.out.println("服务器准备就绪~");System.out.println("服务器信息:" + server.getInetAddress() + " P:" + server.getLocalPort());// 等待客户端连接for (; ; ) {// 得到客户端Socket client = server.accept();// 客户端构建异步线程ClientHandler clientHandler = new ClientHandler(client);// 启动线程clientHandler.start();}}
ServerSocket 和 Socket的关系
serverSocket 和 Socket 都是 Java 中用于网络通信的类,但它们有不同的作用。
Socket 是用于建立连接的类,它可以让客户端和服务器之间相互通信。
ServerSocket 是用于监听连接请求的类,它在服务器端等待客户端的连接请求,并在连接成功后与客户端建立对应的 Socket 连接。
具体工作原理可以简单描述为:
当客户端与服务器建立连接时,客户端通过创建 Socket 对象实现,服务器端则通过创建 ServerSocket 对象实现。
客户端向服务器发送连接请求,请求中包含了要连接的服务器地址和端口号。
ServerSocket 接收到连接请求后,会生成一个 Socket 对象与客户端连接,并返回此连接对应的 Socket 对象。
客户端和服务器之间即可通过这个连接进行通信。
总之,ServerSocket 是用于监听连接请求的类,而 Socket 则是用于实现连接并进行通信的类。
Socket基本数据类型传输
基础类型数据传输
- byte、 char、 short
- boolean、 int、 long
- float、 double、 string
客户端数据传输
- 客户端使用Socket输出流将客户端的数据传输出去
- 建立连接之后将各种数据类型的数据转换成byte字节数组,然后通过ByteBuffer工具统一放入字节流
(这里使用到了一个ByteBuffer工具,这是一个字节缓冲区,后面会详细介绍) - 最后通过Socket的输出流把数据发送给服务端
代码如下:
private static void todo(Socket client) throws IOException {// 得到Socket输出流OutputStream outputStream = client.getOutputStream();// 得到Socket输入流InputStream inputStream = client.getInputStream();byte[] buffer = new byte[256];ByteBuffer byteBuffer = ByteBuffer.wrap(buffer);// bytebyteBuffer.put((byte) 126);// charchar c = 'a';byteBuffer.putChar(c);// intint i = 2323123;byteBuffer.putInt(i);// boolboolean b = true;byteBuffer.put(b ? (byte) 1 : (byte) 0);// Longlong l = 298789739;byteBuffer.putLong(l);// floatfloat f = 12.345f;byteBuffer.putFloat(f);// doubledouble d = 13.31241248782973;byteBuffer.putDouble(d);// StringString str = "Hello你好!";byteBuffer.put(str.getBytes());// 发送到服务器outputStream.write(buffer, 0, byteBuffer.position() + 1);// 接收服务器返回int read = inputStream.read(buffer);System.out.println("收到数量:" + read);// 资源释放outputStream.close();inputStream.close();}
服务端数据接收
- 获取监听到连接的客户端Socket套接字流
- 将流读取出来,转换成ByteBuffer
- 最后根据不同的数据类型将ByteBuffer中的数据读取并且打印出来
/*** 客户端消息处理*/private static class ClientHandler extends Thread {private Socket socket;ClientHandler(Socket socket) {this.socket = socket;}@Overridepublic void run() {super.run();System.out.println("新客户端连接:" + socket.getInetAddress() +" P:" + socket.getPort());try {// 得到套接字流OutputStream outputStream = socket.getOutputStream();InputStream inputStream = socket.getInputStream();byte[] buffer = new byte[256];int readCount = inputStream.read(buffer);ByteBuffer byteBuffer = ByteBuffer.wrap(buffer, 0, readCount);// bytebyte be = byteBuffer.get();// charchar c = byteBuffer.getChar();// intint i = byteBuffer.getInt();// boolboolean b = byteBuffer.get() == 1;// Longlong l = byteBuffer.getLong();// floatfloat f = byteBuffer.getFloat();// doubledouble d = byteBuffer.getDouble();// Stringint pos = byteBuffer.position();String str = new String(buffer, pos, readCount - pos - 1);System.out.println("收到数量:" + readCount + " 数据:"+ be + "\n"+ c + "\n"+ i + "\n"+ b + "\n"+ l + "\n"+ f + "\n"+ d + "\n"+ str + "\n");outputStream.write(buffer, 0, readCount);outputStream.close();inputStream.close();} catch (Exception e) {System.out.println("连接异常断开");} finally {// 连接关闭try {socket.close();} catch (IOException e) {e.printStackTrace();}}System.out.println("客户端已退出:" + socket.getInetAddress() +" P:" + socket.getPort());}}
TCP连接客户端、服务端完整代码
服务端代码:
package cn.kt.SocketDemoL4;import java.io.IOException;
import java.io.InputStream;
import java.io.OutputStream;
import java.net.Inet4Address;
import java.net.InetSocketAddress;
import java.net.ServerSocket;
import java.net.Socket;
import java.nio.ByteBuffer;public class Server {private static final int PORT = 20000;public static void main(String[] args) throws IOException {ServerSocket server = createServerSocket();initServerSocket(server);// 绑定到本地端口上server.bind(new InetSocketAddress(Inet4Address.getLocalHost(), PORT), 50);System.out.println("服务器准备就绪~");System.out.println("服务器信息:" + server.getInetAddress() + " P:" + server.getLocalPort());// 等待客户端连接for (; ; ) {// 得到客户端Socket client = server.accept();// 客户端构建异步线程ClientHandler clientHandler = new ClientHandler(client);// 启动线程clientHandler.start();}}private static ServerSocket createServerSocket() throws IOException {// 创建基础的ServerSocketServerSocket serverSocket = new ServerSocket();// 绑定到本地端口20000上,并且设置当前可允许等待链接的队列为50个//serverSocket = new ServerSocket(PORT);// 等效于上面的方案,队列设置为50个//serverSocket = new ServerSocket(PORT, 50);// 与上面等同// serverSocket = new ServerSocket(PORT, 50, Inet4Address.getLocalHost());return serverSocket;}private static void initServerSocket(ServerSocket serverSocket) throws IOException {// 是否复用未完全关闭的地址端口serverSocket.setReuseAddress(true);// 等效Socket#setReceiveBufferSizeserverSocket.setReceiveBufferSize(64 * 1024 * 1024);// 设置serverSocket#accept超时时间// serverSocket.setSoTimeout(2000);// 设置性能参数:短链接,延迟,带宽的相对重要性serverSocket.setPerformancePreferences(1, 1, 1);}/*** 客户端消息处理*/private static class ClientHandler extends Thread {private Socket socket;ClientHandler(Socket socket) {this.socket = socket;}@Overridepublic void run() {super.run();System.out.println("新客户端连接:" + socket.getInetAddress() +" P:" + socket.getPort());try {// 得到套接字流OutputStream outputStream = socket.getOutputStream();InputStream inputStream = socket.getInputStream();byte[] buffer = new byte[256];int readCount = inputStream.read(buffer);ByteBuffer byteBuffer = ByteBuffer.wrap(buffer, 0, readCount);// bytebyte be = byteBuffer.get();// charchar c = byteBuffer.getChar();// intint i = byteBuffer.getInt();// boolboolean b = byteBuffer.get() == 1;// Longlong l = byteBuffer.getLong();// floatfloat f = byteBuffer.getFloat();// doubledouble d = byteBuffer.getDouble();// Stringint pos = byteBuffer.position();String str = new String(buffer, pos, readCount - pos - 1);System.out.println("收到数量:" + readCount + " 数据:"+ be + "\n"+ c + "\n"+ i + "\n"+ b + "\n"+ l + "\n"+ f + "\n"+ d + "\n"+ str + "\n");outputStream.write(buffer, 0, readCount);outputStream.close();inputStream.close();} catch (Exception e) {System.out.println("连接异常断开");} finally {// 连接关闭try {socket.close();} catch (IOException e) {e.printStackTrace();}}System.out.println("客户端已退出:" + socket.getInetAddress() +" P:" + socket.getPort());}}
}客户端代码
package cn.kt.SocketDemoL4;import java.io.IOException;
import java.io.InputStream;
import java.io.OutputStream;
import java.net.Inet4Address;
import java.net.InetSocketAddress;
import java.net.Socket;
import java.net.SocketException;
import java.nio.ByteBuffer;public class Client {private static final int PORT = 20000;private static final int LOCAL_PORT = 20001;public static void main(String[] args) throws IOException {Socket socket = createSocket();initSocket(socket);// 链接到本地20000端口,超时时间3秒,超过则抛出超时异常socket.connect(new InetSocketAddress(Inet4Address.getLocalHost(), PORT), 3000);System.out.println("已发起服务器连接,并进入后续流程~");System.out.println("客户端信息:" + socket.getLocalAddress() + " P:" + socket.getLocalPort());System.out.println("服务器信息:" + socket.getInetAddress() + " P:" + socket.getPort());try {// 发送接收数据todo(socket);} catch (Exception e) {System.out.println("异常关闭");}// 释放资源socket.close();System.out.println("客户端已退出~");}private static Socket createSocket() throws IOException {/*// 无代理模式,等效于空构造函数Socket socket = new Socket(Proxy.NO_PROXY);// 新建一份具有HTTP代理的套接字,传输数据将通过www.baidu.com:8080端口转发Proxy proxy = new Proxy(Proxy.Type.HTTP,new InetSocketAddress(Inet4Address.getByName("www.baidu.com"), 8800));socket = new Socket(proxy);// 新建一个套接字,并且直接链接到本地20000的服务器上socket = new Socket("localhost", PORT);// 新建一个套接字,并且直接链接到本地20000的服务器上socket = new Socket(Inet4Address.getLocalHost(), PORT);// 新建一个套接字,并且直接链接到本地20000的服务器上,并且绑定到本地20001端口上socket = new Socket("localhost", PORT, Inet4Address.getLocalHost(), LOCAL_PORT);socket = new Socket(Inet4Address.getLocalHost(), PORT, Inet4Address.getLocalHost(), LOCAL_PORT);*/Socket socket = new Socket();// 绑定到本地20001端口socket.bind(new InetSocketAddress(Inet4Address.getLocalHost(), LOCAL_PORT));return socket;}private static void initSocket(Socket socket) throws SocketException {// 设置读取超时时间为2秒socket.setSoTimeout(2000);// 是否复用未完全关闭的Socket地址,对于指定bind操作后的套接字有效socket.setReuseAddress(true);// 是否开启Nagle算法socket.setTcpNoDelay(true);// 是否需要在长时无数据响应时发送确认数据(类似心跳包),时间大约为2小时socket.setKeepAlive(true);// 对于close关闭操作行为进行怎样的处理;默认为false,0// false、0:默认情况,关闭时立即返回,底层系统接管输出流,将缓冲区内的数据发送完成// true、0:关闭时立即返回,缓冲区数据抛弃,直接发送RST结束命令到对方,并无需经过2MSL等待// true、200:关闭时最长阻塞200毫秒,随后按第二情况处理socket.setSoLinger(true, 20);// 是否让紧急数据内敛,默认false;紧急数据通过 socket.sendUrgentData(1);发送socket.setOOBInline(true);// 设置接收发送缓冲器大小socket.setReceiveBufferSize(64 * 1024 * 1024);socket.setSendBufferSize(64 * 1024 * 1024);// 设置性能参数:短链接,延迟,带宽的相对重要性socket.setPerformancePreferences(1, 1, 0);}private static void todo(Socket client) throws IOException {// 得到Socket输出流OutputStream outputStream = client.getOutputStream();// 得到Socket输入流InputStream inputStream = client.getInputStream();byte[] buffer = new byte[256];ByteBuffer byteBuffer = ByteBuffer.wrap(buffer);// bytebyteBuffer.put((byte) 126);// charchar c = 'a';byteBuffer.putChar(c);// intint i = 2323123;byteBuffer.putInt(i);// boolboolean b = true;byteBuffer.put(b ? (byte) 1 : (byte) 0);// Longlong l = 298789739;byteBuffer.putLong(l);// floatfloat f = 12.345f;byteBuffer.putFloat(f);// doubledouble d = 13.31241248782973;byteBuffer.putDouble(d);// StringString str = "Hello你好!";byteBuffer.put(str.getBytes());// 发送到服务器outputStream.write(buffer, 0, byteBuffer.position() + 1);// 接收服务器返回int read = inputStream.read(buffer);System.out.println("收到数量:" + read);// 资源释放outputStream.close();inputStream.close();}
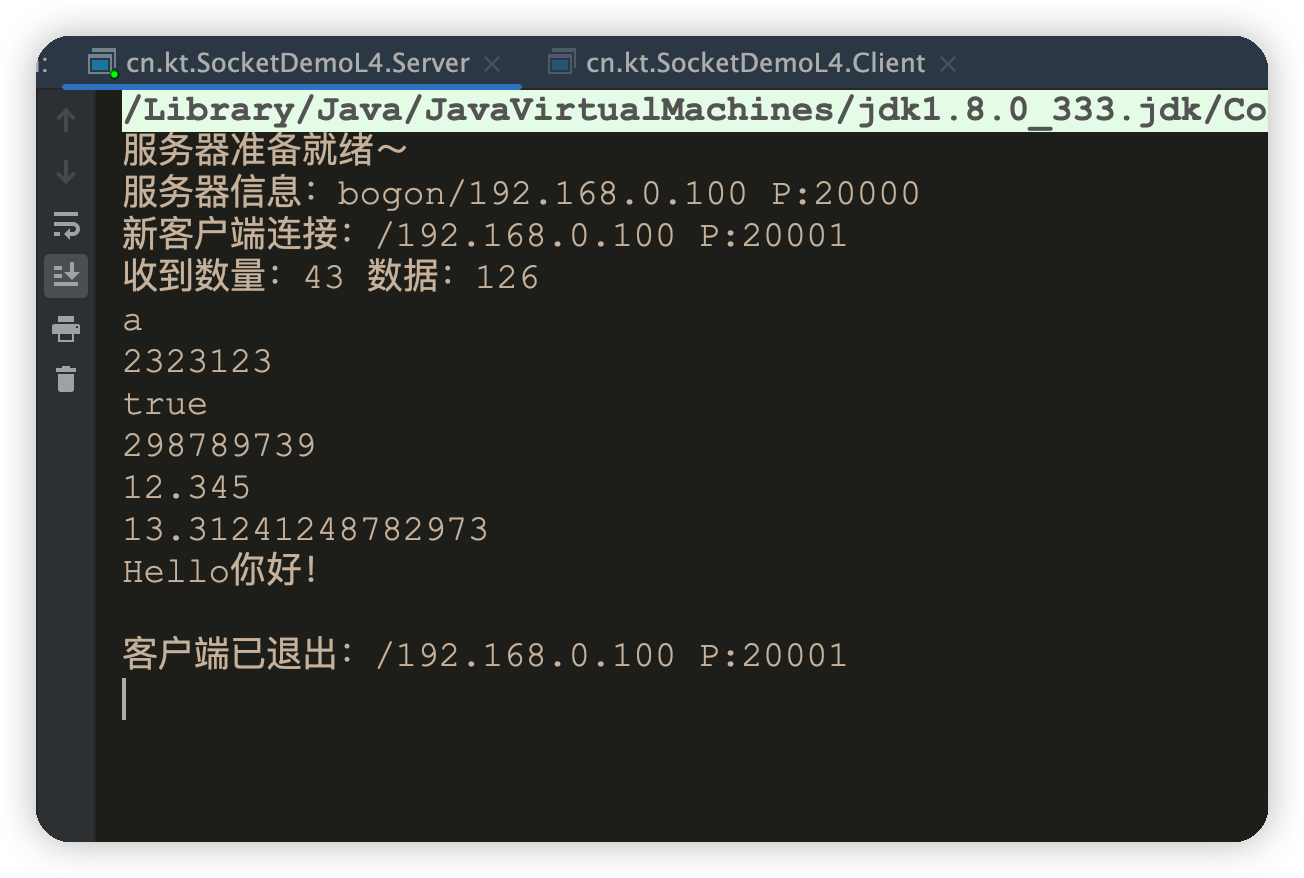
}执行结果
-
运行服务端
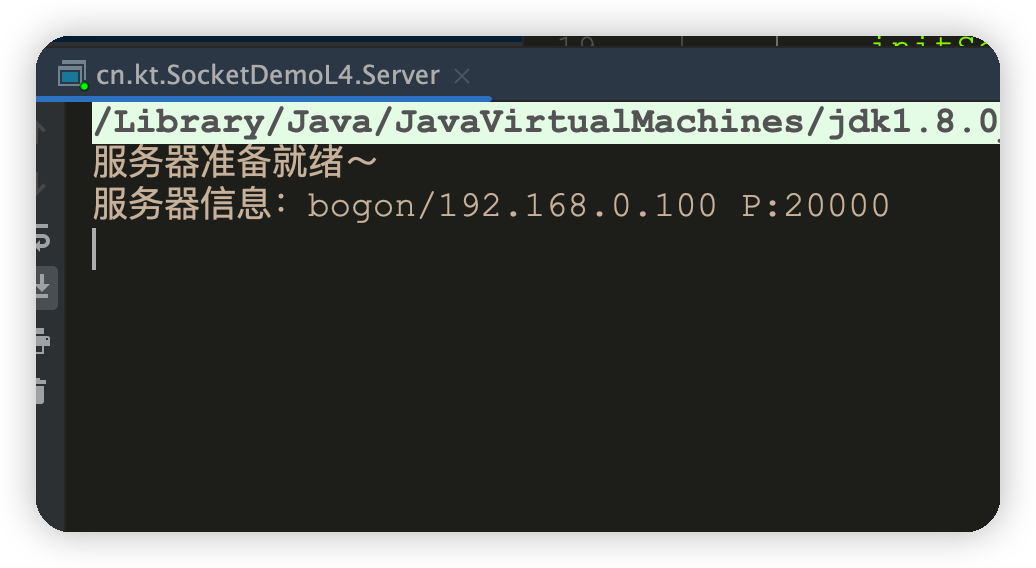
-
运行客户端
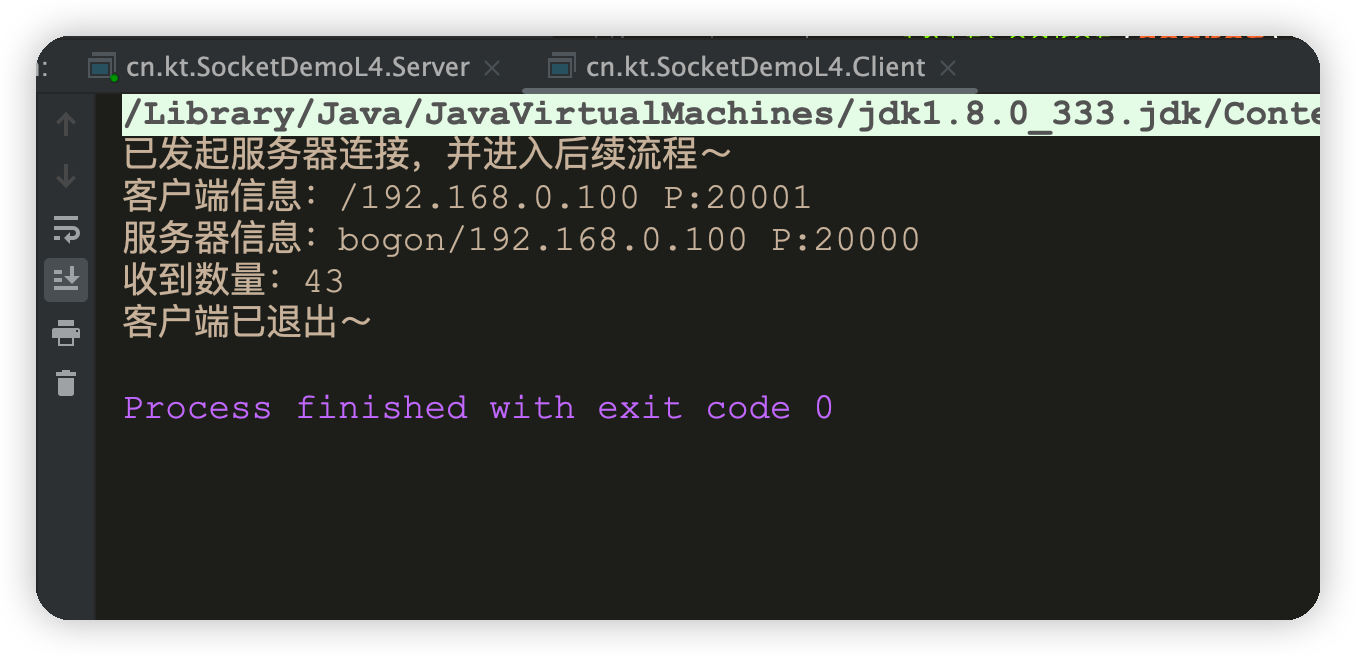
-
服务端接收到消息并输出