网站开发学的啥企业做淘宝客网站有哪些
DockView是一款Mac电脑上的软件,它可以增强Dock的功能,让用户更方便地管理和切换应用程序。
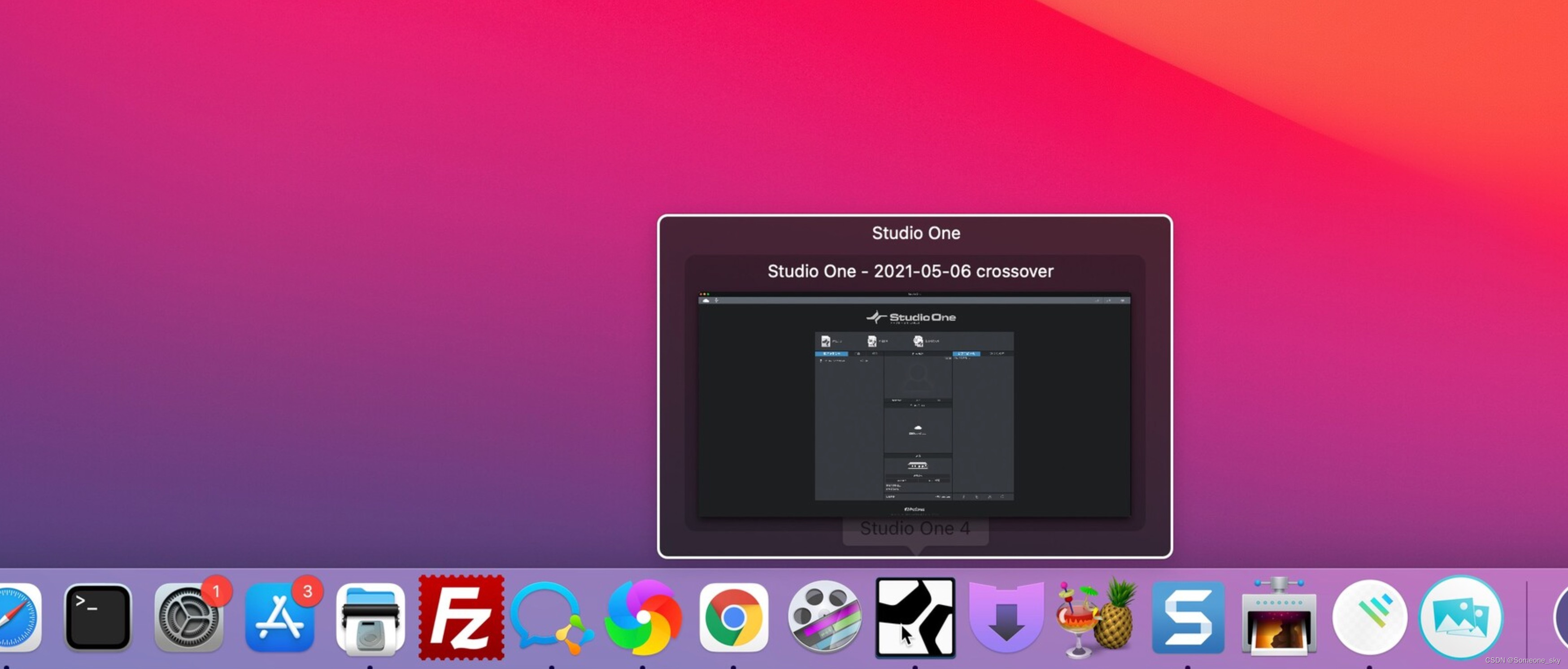 DockView的主要功能是在 DockQ,栏上显示每个窗口的缩略图,并提供了一些相关的操作选项。当用户将鼠标悬停在Dock栏上的应用程序图标上时,会显示与该程序相关的所有打开窗口的缩略图。
DockView的主要功能是在 DockQ,栏上显示每个窗口的缩略图,并提供了一些相关的操作选项。当用户将鼠标悬停在Dock栏上的应用程序图标上时,会显示与该程序相关的所有打开窗口的缩略图。
通过DockView,用户可以快速浏览和切换窗口,而无需通过Alt+ Tab或EXpose等其他方式进行操作。用户可以直接点击缩略图来切换到所需的窗口,这极大地提高了工作效率。
除了浏览和切换窗口,DockView还提供了一些其他的实用功能。用户可以通过鼠标右键点击缩略图来进行窗口管理操作,如最小化、关闭、调整大小等。而且,DockView还支持通过键盘快捷键来进行相关操作,进一步提升了操作的便利性。
DockView还允许用户自定义软件的外观和行为。用户可以根据自己的偏好设置缩略图的大小、显示效果和其他选项。这样,用户可以根据自己的需求来个性化软件的使用体验。
总体而言,DockView是一款实用的Mac软件,提供了方便快捷的窗口管理功能。它可以帮助用户 更高效Q地处理和切换多个窗口,提升工作效率。