做美食网站的需求用什么网站做一手楼好
在光学跟踪系统领域,ART公司凭借其先进的技术和卓越的产品性能,一直受到市场的广泛关注。ARTTrack6/M、ARTTrack5和ART AT7-80作为ART公司的三款代表性产品,各自在不同的应用场景中发挥着重要作用。本文将对这三款产品进行纵向对比,帮助用户更好地理解它们的应用方向、特点和优势。

一、应用场景与跟踪范围
ARTTrack6/M

ARTTrack6/M以其小巧且功能强大的特点,适用于中小型跟踪区域和有限空间内的跟踪。无论是汽车工业的发展还是模拟和培训市场,这款小巧的摄像机都能轻松应对。它的跟踪范围在30厘米以下至5米之间,非常适合安装在狭窄的空间内,如车内、飞机驾驶舱等。

ARTTrack5

ARTTrack5是一款适用于大型空间内的动作跟踪系统。它的被动标记可达5.5米,主动标记更是可达10米,使得它在工业环境、虚拟现实环境、工业仿真、科研教育等人体动作捕获领域有着广泛的应用。无论是高速运动的捕捉还是静态场景的记录,ARTTrack5都能提供准确可靠的数据。
ART AT7-80
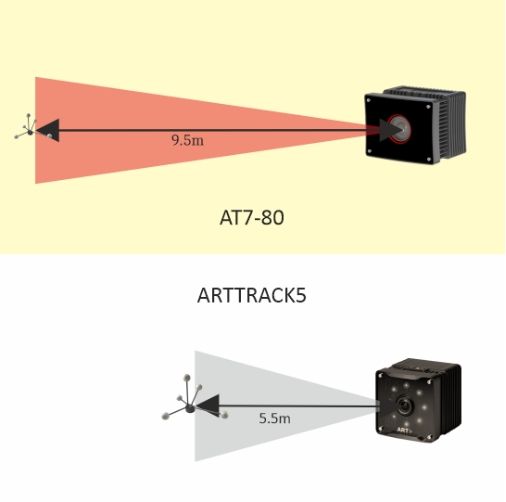
ART AT7-80作为ARTTRACK产品线中最新的顶级跟踪相机,其跟踪范围更远,能够支持更大规模的跟踪区域。这使得在同一跟踪区域内,使用更少的摄像头就能实现全面的跟踪覆盖。同时,它还能追踪更小的标记,提高了跟踪的精确度和灵活性。
二、帧率与精度
ARTTrack6/M

在帧率方面,ARTTrack6/M以其高达500Hz的帧速率脱颖而出,能够轻松捕捉快速移动物体的动态轨迹。这使得它在虚拟现实体验、工业仿真等领域具有极高的应用价值。
ARTTrack5
ARTTrack5的帧率虽然稍逊一筹,但也达到了300Hz的高水平。这样的帧率足以满足大多数动态场景的捕捉需求,确保数据的准确性和可靠性。同时,ARTTrack5的精度可达亚毫米级别,进一步提升了数据的精确性。
ART AT7-80

ART AT7-80的帧率在180Hz至480Hz之间可变,用户可以根据实际需求调整帧率。在降低追踪范围时,它甚至可以达到最高的480Hz帧率。这样的设计使得ART AT7-80在精确大规模跟踪应用的同时,还能保持高水准的精确度和稳定性。
三、尺寸与安装
ARTTrack6/M

ARTTrack6/M以其紧凑的尺寸和轻便的重量,成为了狭小空间内跟踪的首选。它的设计使得安装过程更加简单快捷,减少了安装时间和成本。
ARTTrack5与ART AT7-80

ARTTrack5和ART AT7-80在尺寸和重量上可能相对较大,但它们的性能也更加出色。同时,这两款产品都支持单电缆解决方案,进一步简化了安装过程。
四、详细参数横向对比
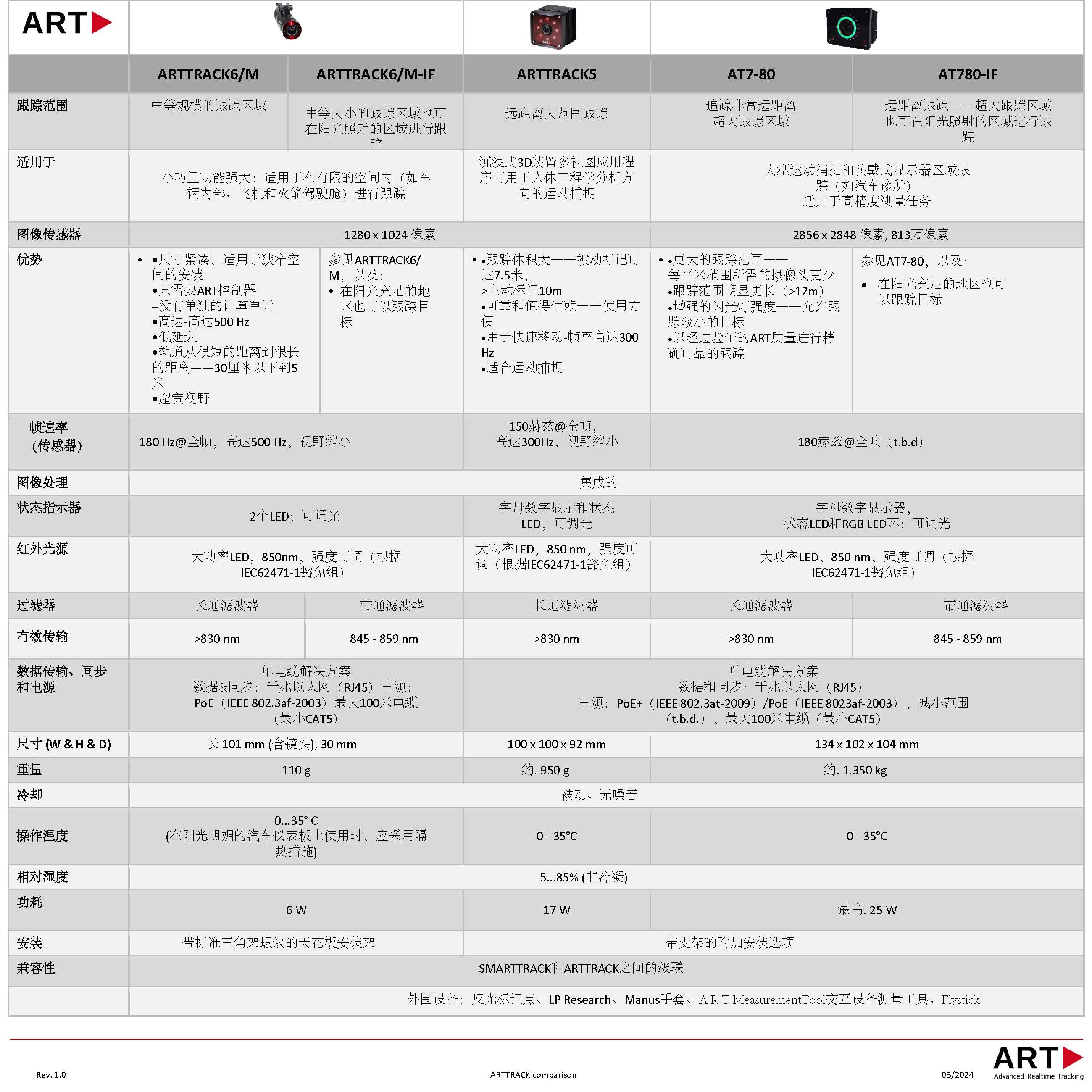
ARTTrack6/M、ARTTrack5和ART AT7-80作为ART公司的三款代表性产品,各自在不同的应用场景中发挥着重要作用。用户可以根据实际需求选择最适合自己的产品来实现最佳的应用效果。无论是小巧轻便的ARTTrack6/M、性能卓越的ARTTrack5还是顶级精准的ART AT7-80,它们都将为用户提供卓越的光学跟踪体验。