怎样做彩票网站公司网站自己可以学习优化吗
CI/CD是持续集成,持续部署,集成就是开发人员通过自动化编译,发布,测试的手段集成软件,在开发的测试环境上测试发现自己的错误;持续部署是自动化构建,部署,通常也是在测试环境上进行,方便开发人员查看效果。
生产环境的话要谨慎很多,在测试环境上由测试人员测试好后开始上生产环境,生产环境集成Jenkins要确保整个流程相当完善,形成一套pipeline,后续迭代更新也由Jenkins来做自动化更新,一键更新生产环境。
听同事说有的C语言的项目,只是编译就要好几个钟头,如果项目集成比较耗费时间,运行在master上会消耗过多资源,影响其他项目集成,这时候就需要建立多台设备,配置slave机器来为master提供负载服务,类似于zabbix分布式监控,这种构建方式叫做分布式构建。
文章目录
- Pipeline介绍
- Pipeline示例
- 一、声明式
- 二、脚本式
- Pipeline项目
- 一、项目内部写Pipeline
- 二、代码内部写Pipeline
- 分布式构建
Pipeline介绍
Pipeline就是运行在Jenkins上的工作流,把单个节点的任务连接起来,实现单个任务难以完成的复杂发布流程。它的实现方式是Groovy的脚本,它支持从代码段中读取脚本,实现了Pipeline与代码的融合。
Pipeline是用户定义的部署的流程,包含构建,测试,发布等步骤,有一些代码块需要我们去关注,比如Node,是一个机器,是Jenkins环境的一部分,可以执行Pipeline;还有Stage,Stage块定义在整个Pipeline中执行的概念上的不同的任务子集,例如,构建,测试,部署等,很多插件都通过这个代码块去做可视化,呈现Jenkins管道状态、进度;Step是一项任务,是一个步骤,告诉Jenkins在特定时间点,需要做什么,例如sh step:sh 'make’可以执行make这个shell命令。
Pipeline示例
Pipeline分为声明式和脚本式,两者相差不是很大,注意不要混淆,建议用声明式
一、声明式
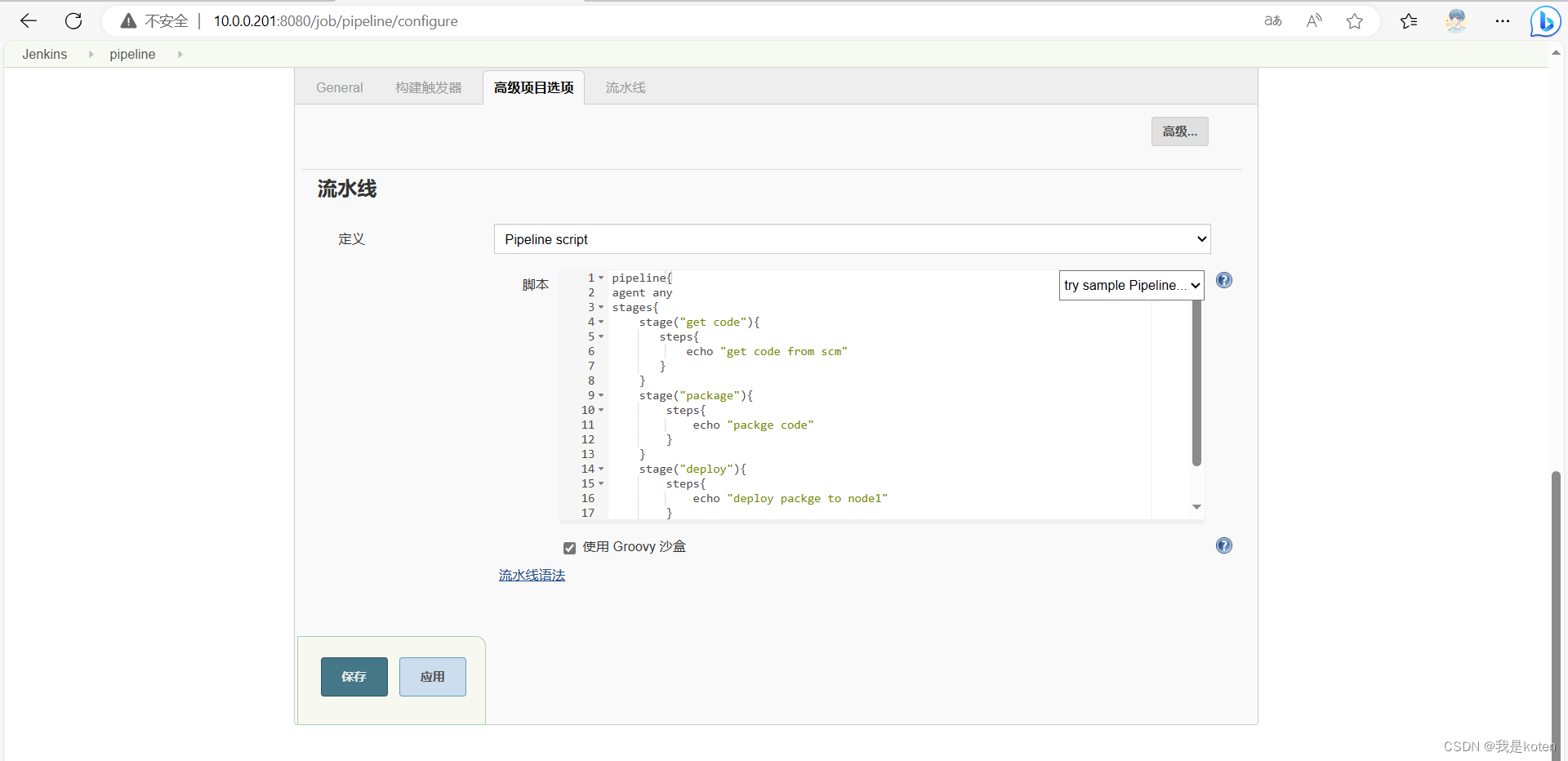
pipeline{
agent any
stages{stage("get code"){steps{echo "get code from scm"}}stage("package"){steps{echo "packge code"}}stage("deploy"){steps{echo "deploy packge to node1"}}
}
}
二、脚本式
node {stage('Build') {echo 'Build'}stage('Test') {echo 'Test'}stage('Deploy') {echo 'Deploy'}
}
Pipeline项目
一、项目内部写Pipeline
1、新建一个pipeline项目

2、粘贴声明式脚本
二、代码内部写Pipeline
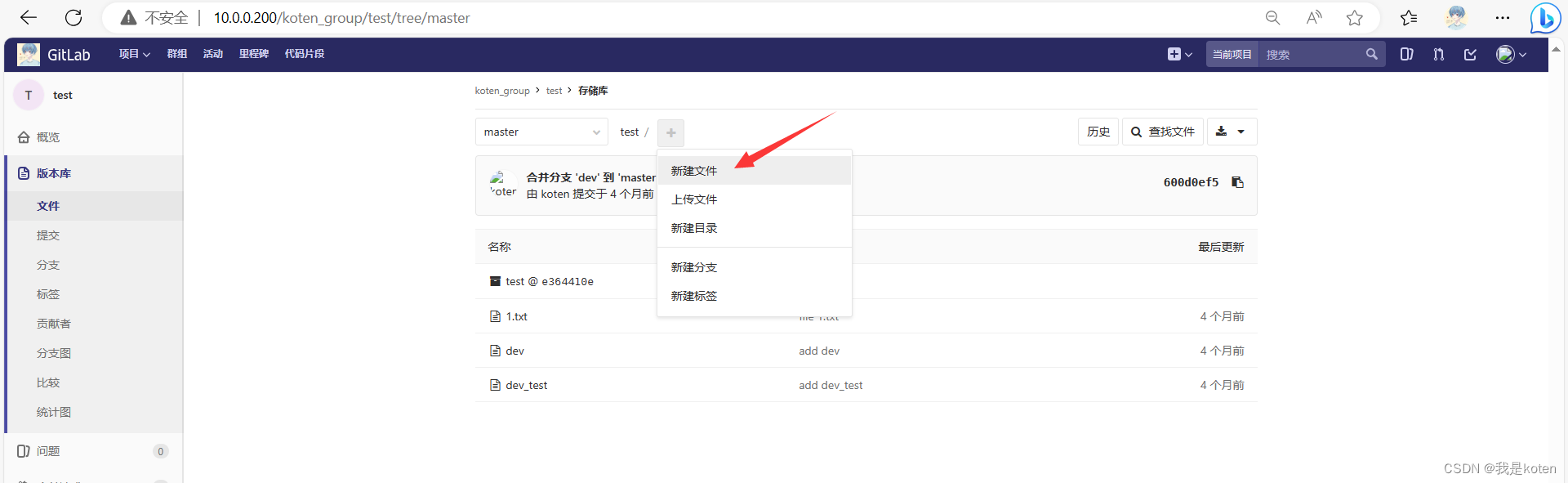
在代码仓库里新建个文件去写即可
pipeline{
agent any
// agent { label 'node1' }
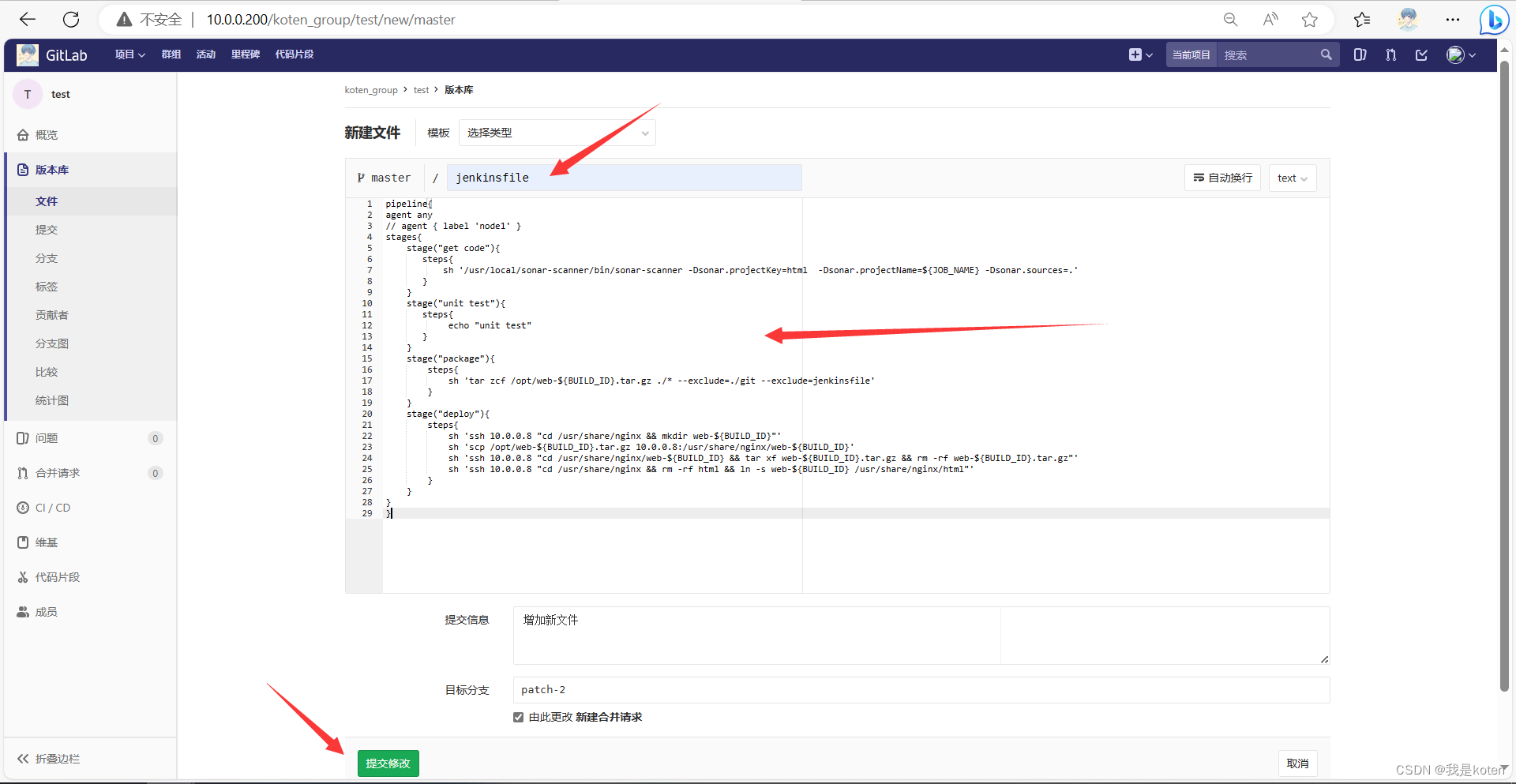
stages{stage("get code"){steps{sh '/usr/local/sonar-scanner/bin/sonar-scanner -Dsonar.projectKey=html -Dsonar.projectName=${JOB_NAME} -Dsonar.sources=.'}}stage("unit test"){steps{echo "unit test"}}stage("package"){steps{sh 'tar zcf /opt/web-${BUILD_ID}.tar.gz ./* --exclude=./git --exclude=jenkinsfile'}}stage("deploy"){steps{sh 'ssh 10.0.0.8 "cd /usr/share/nginx && mkdir web-${BUILD_ID}"'sh 'scp /opt/web-${BUILD_ID}.tar.gz 10.0.0.8:/usr/share/nginx/web-${BUILD_ID}'sh 'ssh 10.0.0.8 "cd /usr/share/nginx/web-${BUILD_ID} && tar xf web-${BUILD_ID}.tar.gz && rm -rf web-${BUILD_ID}.tar.gz"'sh 'ssh 10.0.0.8 "cd /usr/share/nginx && rm -rf html && ln -s web-${BUILD_ID} /usr/share/nginx/html"'}}
}
}
这里用的是开发人员用户创建的jenkinsfile,申请合并到了master分支,又用root用户去同意合并了一下。
在Jenkins端测试获取
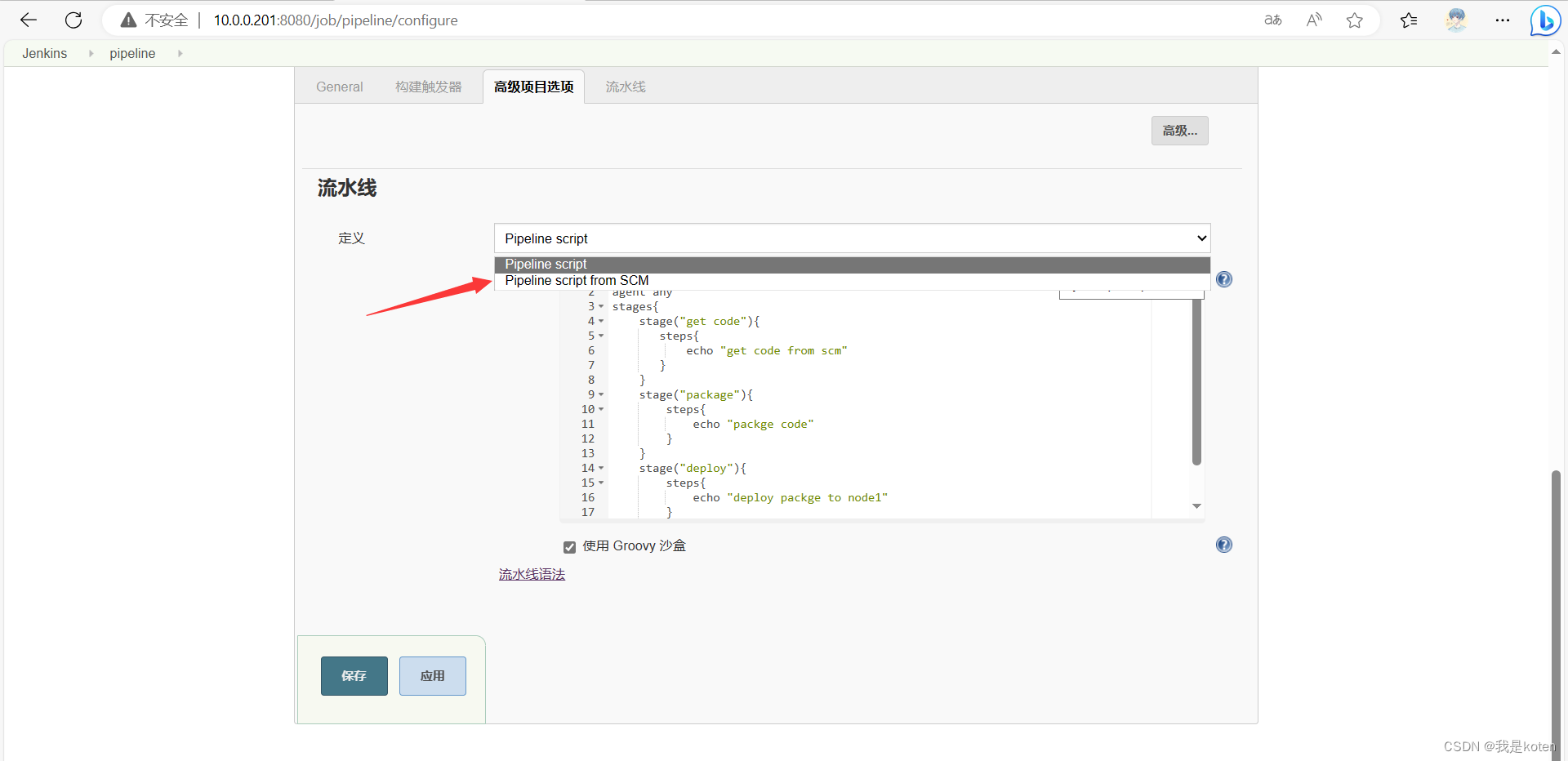
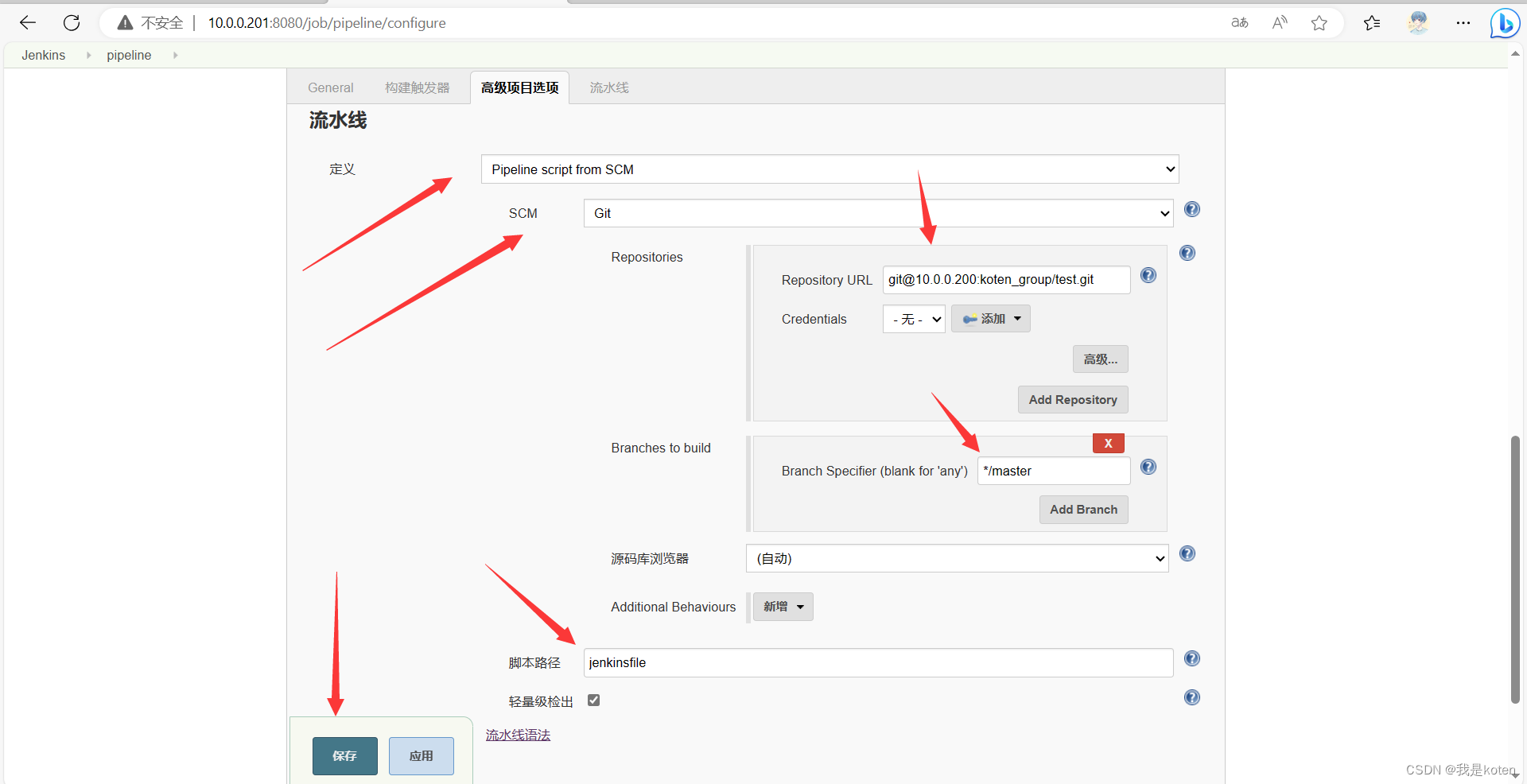
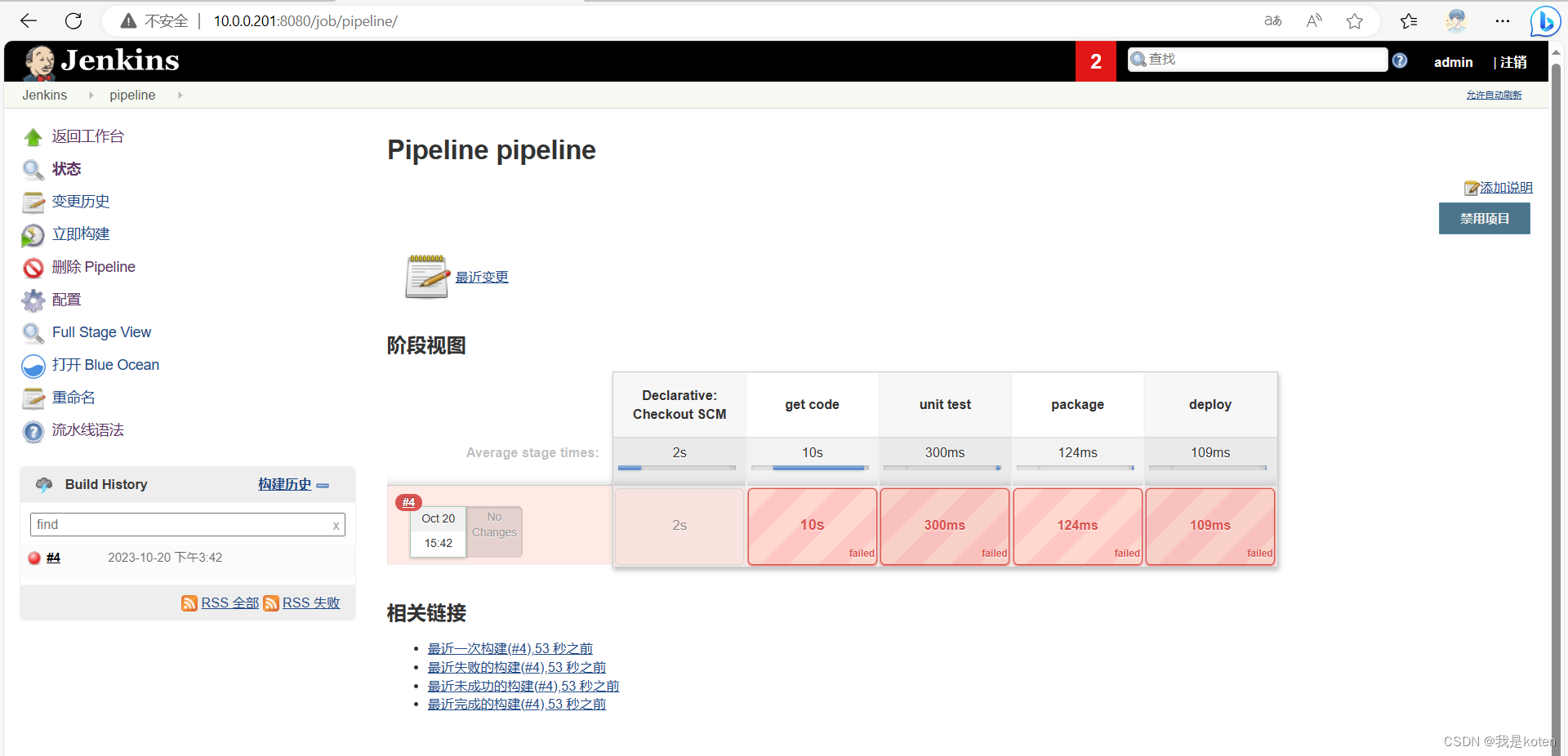
点击构建测试,jenkinsfile是取到了但是构建失败了,因为我jenkinsfile的原因,这里大家根据业务需求去写自己的jenkinsfile就行,我这里只是把流程给大家跑通了。
分布式构建
如果你的项目在集成的时候很耗费性能,那你千万不要可着一台机器去折腾,你可以配置一些slave机器为master机器提供负载服务。
接下来我们部署一台slave服务器。
1、在sonar上安装java,git。
[root@Sonar ~]# yum -y install java git
2、把以及配置好的sonar和maven的客户端,scp到sonar主机。
[root@Jenkins ~]# scp -r /usr/local/sonar-scanner 10.0.0.203:/usr/local/
[root@Jenkins ~]# scp -r /usr/local/maven 10.0.0.203:/usr/local/[root@Sonar ~]# mkdir -p /server/scripts[root@Jenkins ~]# scp /var/lib/jenkins/workspace/git_version/deploy_rollback.sh 10.0.0.203:/server/scripts/
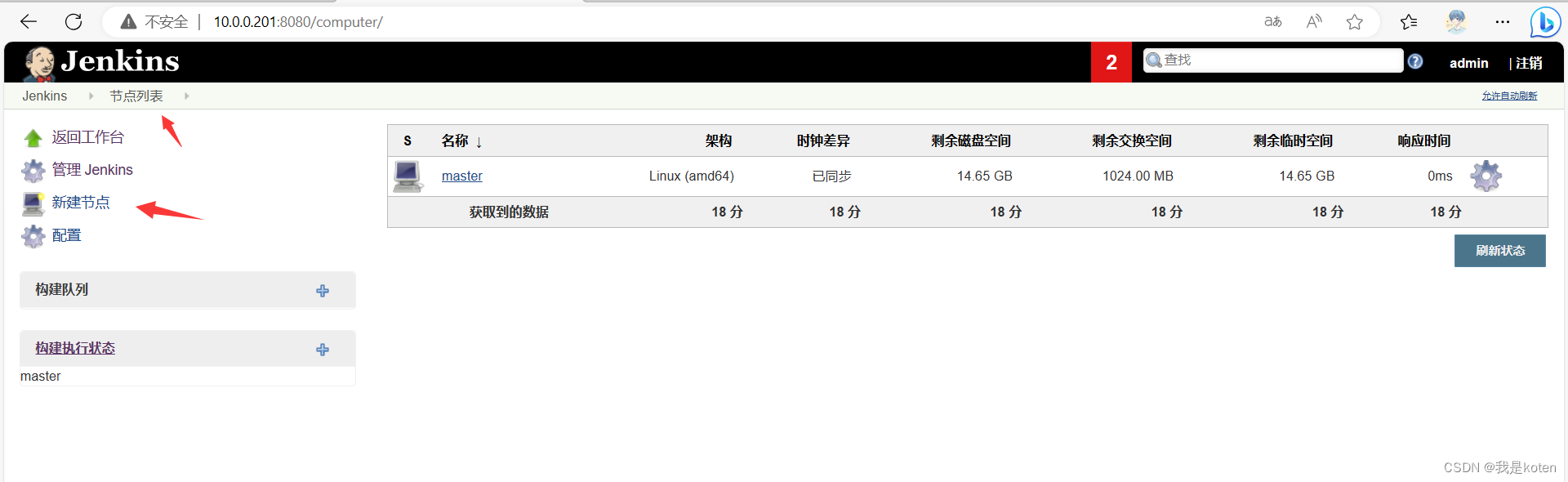
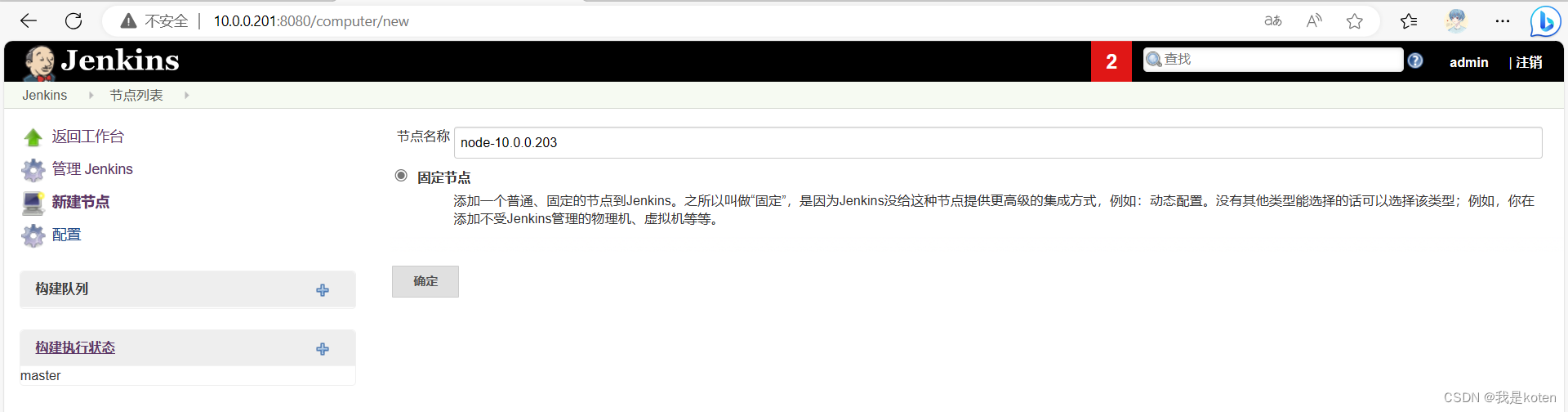
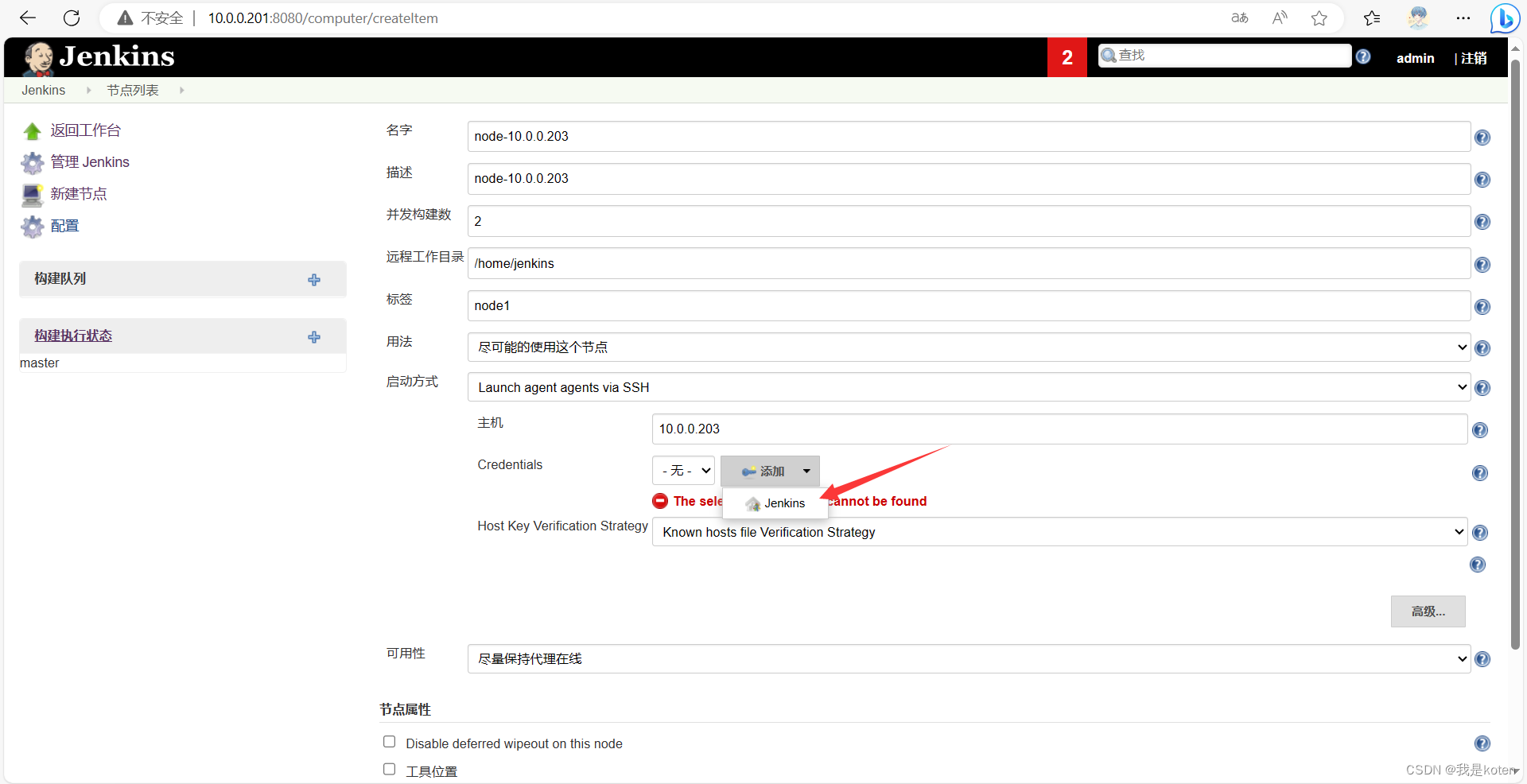
3、在Jenkins上创建节点
系统管理,节点管理,新建节点。
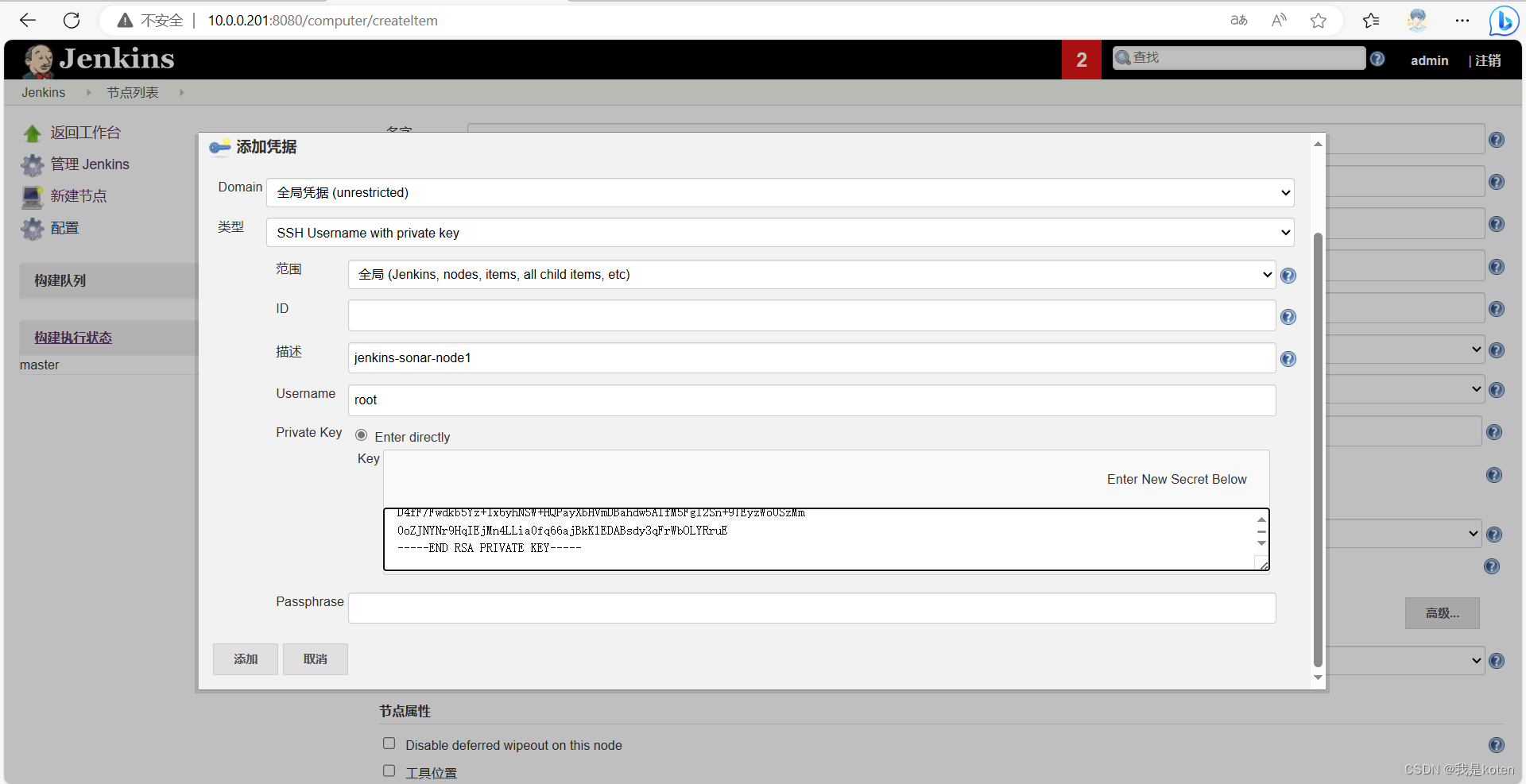
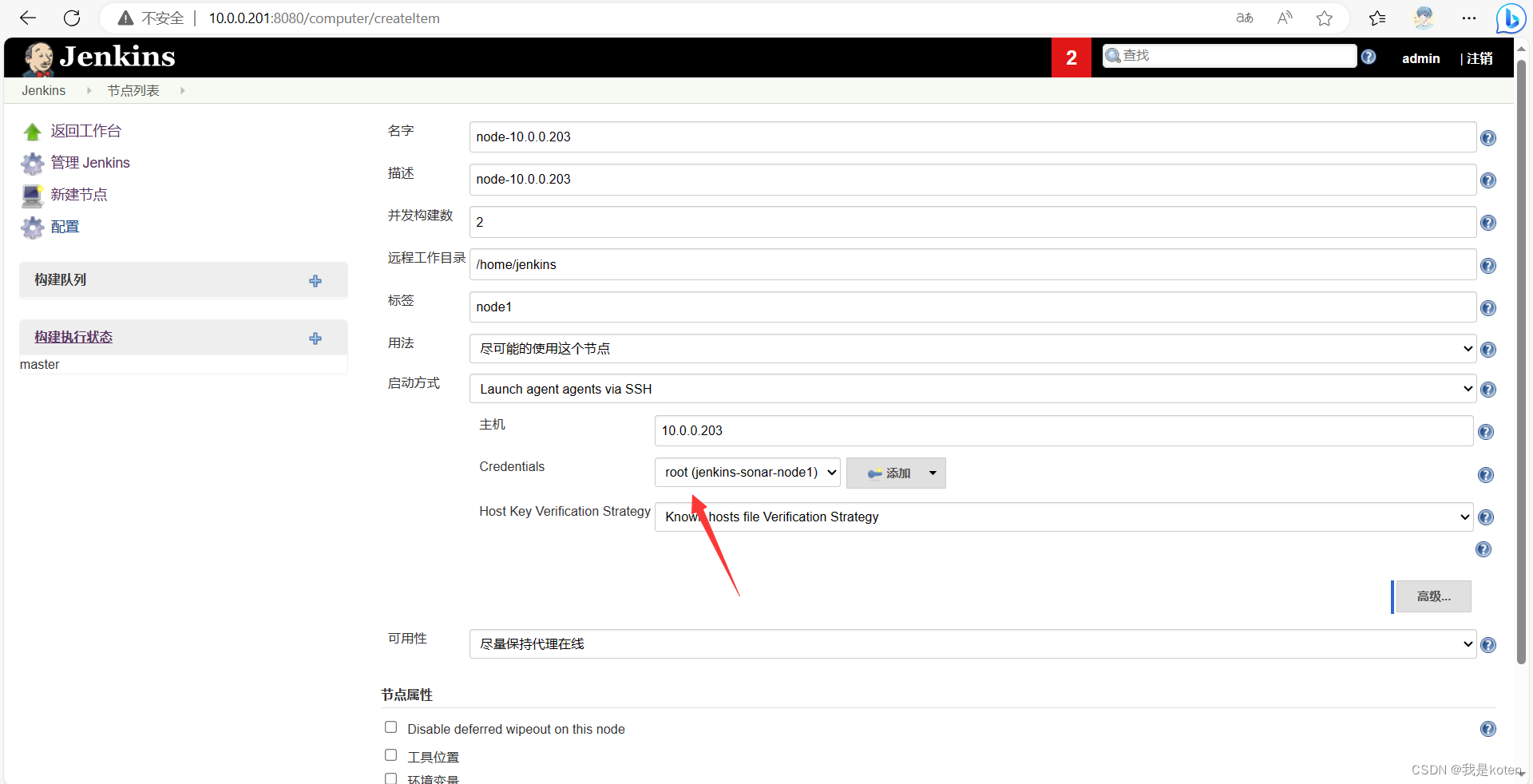
做免秘钥认证拷贝jenkins公钥到slave,私钥配置到jenkins
ssh-copy-id -i .ssh/id_rsa.pub 10.0.0.203
[root@Jenkins ~]# cat .ssh/id_rsa
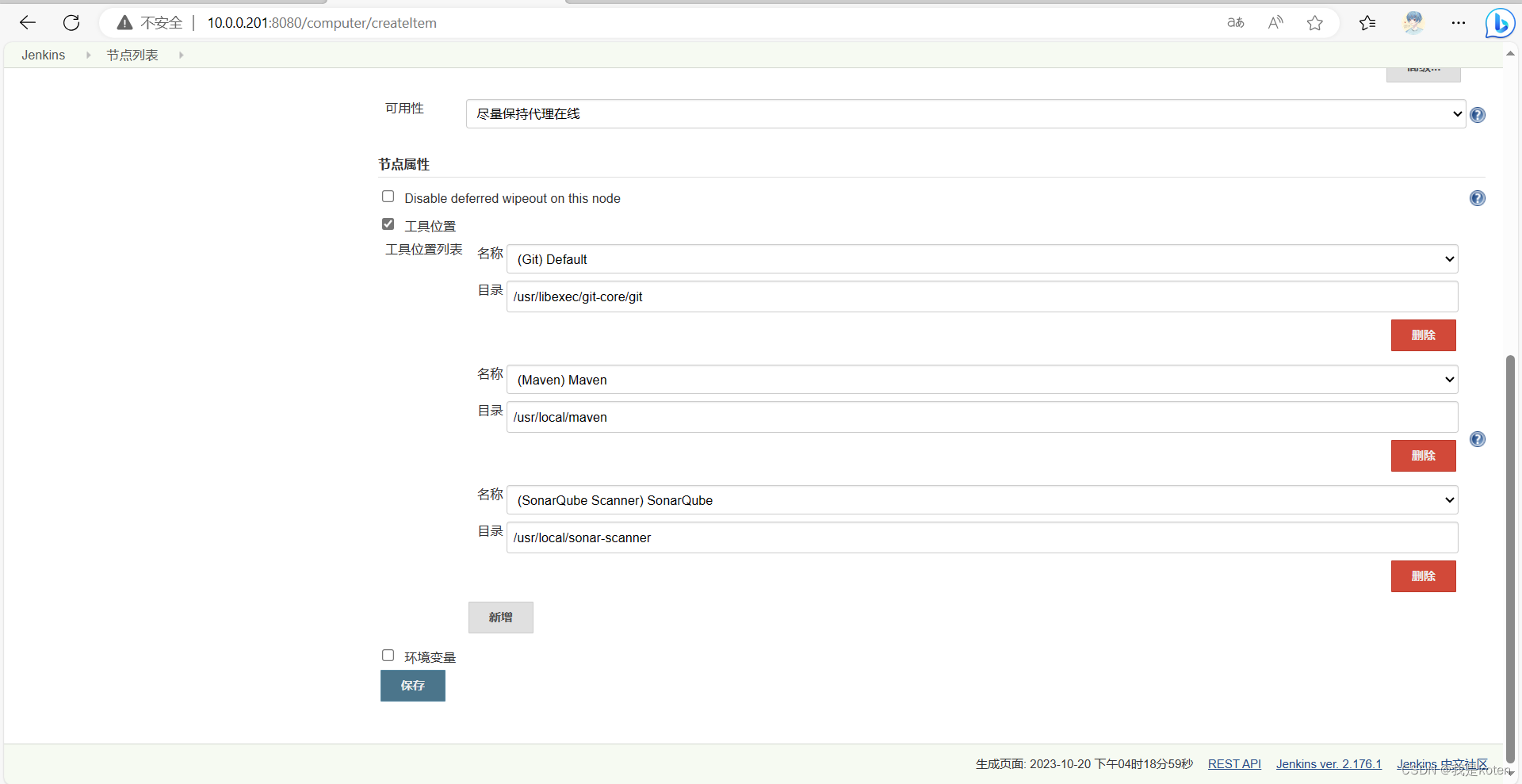
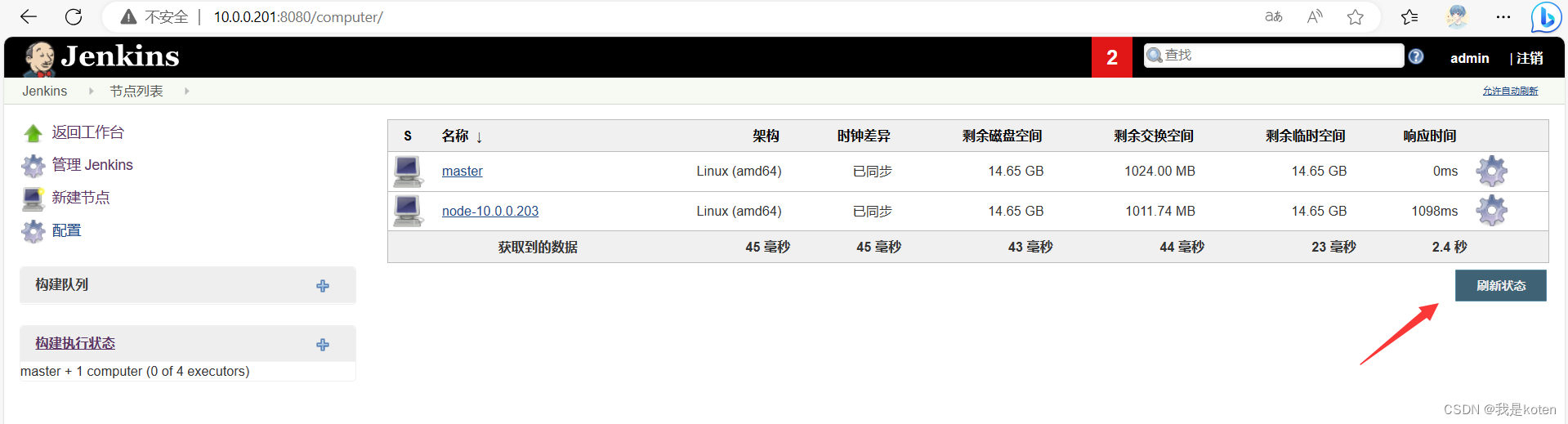
slave服务器上还需要做连接web的免秘钥认证,方便去推送代码,总之是把各个流程都打通,做这个前可以画个图按照图去操作。
[root@Sonar ~]# ssh-keygen
[root@Sonar ~]# ssh-copy-id -i .ssh/id_rsa.pub 10.0.0.7
当构建任务超过2时,会分配给slave节点去构建,可能是我用的这个Jenkins版本太老了,好多功能都无法复现的很好,还有一些bug,推荐大家用新版本。

我是koten,10年运维经验,持续分享运维干货,感谢大家的阅读和关注!