如何建一个网站关于建设设计院公司网站的建议
今天上班开早会就是新人见面仪式,听说来了个很厉害的大佬,年纪还不大,是上家公司离职过来的,薪资已经达到中高等水平,很多人都好奇不已,能拿到这个薪资应该人不简单,果然,自我介绍的时候都惊讶到我们了,让我见识到了什么叫真正的测试天花板…
了解过后这大佬是有5年的测试开发经验,不仅有熟练测试业务能力,而且还会编程,测试框架,测试工具开发,还能全面掌握数据库等方面的技能,甚至熟悉分布式组件等高级技能。在上家公司也是管理一个项目的组长。果然人有能力就是不一样,在哪里都发光!!!

这两天和朋友说起这件事情,感叹现在的年轻人都这么优秀,说到底,软件测试行业还是属于技术岗位,随着不断地转行人员以及毕业的大学生疯狂地涌入软件测试行业,行业天花板也在逐渐升高,曾经那些只会点点点的测试员们越来越难在行业立足,逐渐会被自动化测试工程师和测试开发工程师所取代。
想到自己也深有感触,当初也是时常怕“被淘汰、被取代”的恐惧折磨。不论是面试哪个级别的测试工程师,面试官都会问一句“会编程吗?有没有自动化测试的相关经验?”
我的软件测试职业大多数测试人员一样,一开始在一家电商公司做软件功能测试,也就是点点点。一开始觉得很轻松,工作难度比较低,但是做了几个月之后,就感觉把人机械化了,没有一点点技术的提升,毕竟每天都是在做同样的事情,对同一张页面反复点点点。让我产生了对自我价值和岗位意义的困惑。薪资也得不到提升,看着身边的人不断涨薪,或者跳槽去了更好的公司,特别觉得自己跌落谷底,碌碌无为…

不得已开始思考怎么去改变现状,自己的内心也不满足于只做功能测试,那时候正是脚本语言开始流行起来,因为当时项目的原因跟Python结缘,开始用Python和Selenium来尝试做自动化测试。
在入门阶段,要有很强的自制力,平常比较好学,平常没什么事情的时候都会自己在网上找资源报班学习,学敲代码,每天下班回来就抽出一个小时看视频做笔记,慢慢地也懂了一些测试开发方面的知识。
怀着这份野心,先是花小半年时间学习了UI自动化,需要学的内容有很多。学习过程中所有的知识都是零散的,想要组合起来对一个小白来说确实不容易。有了UI自动化学习经验,学习接口自动化基本没有费什么功夫。
UI自动化,接口自动化学完了,因为工作需要又去学了性能,后来发现性能真的是个无底洞,需要了解开发知识、服务器架构、操作系统、测试监控工具、容器知识等等。知识面太广,现在还在苦苦挣扎。在性能测试过程中,也去学了一些开发知识,之前做UI/接口自动化或者功能测试时只能从黑盒/灰盒层面去判断BUG原因,学了开发知识后,大概就知道这个bug是如何产生了。
因为自己的功能测试经验丰富,接口自动化,UI自动化也非常熟练,机缘巧合,朋友推荐我去一家金融公司做测试开发,负责开发公司定制化的测试质量平台。到岗后就是顶住压力,不断的学习测试开发技能,而且学以致用。技术架构采用的是前后端分享,包括Python的后端开发框架Flask,前端框架vue,elementUI组件等,这对我自己的测试生涯也算是有了一个提高。薪资方面也有了一个大的突破!
作为一个过来人,对学习过程中的困难深有体会。
如果你也在往自动化测试开发方向发展,在适当的年龄,选择适当的岗位,将自己的优势都发挥出来!
我的自动化测试之路,一路走来都离不每个阶段的计划,因为自己喜欢规划和收集总结,所以,我和朋友特意花了一段时间整理编写了下面的《自动化测试工程师学习路线》,也整理了不少【网盘资源】,需要的朋友可以点击下方小卡片获取网盘链接。希望会给你带来帮助和方向。
1、Python编程语言

2、自动化测试框架
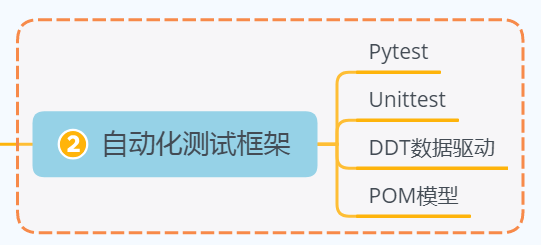
3、接口自动化测试

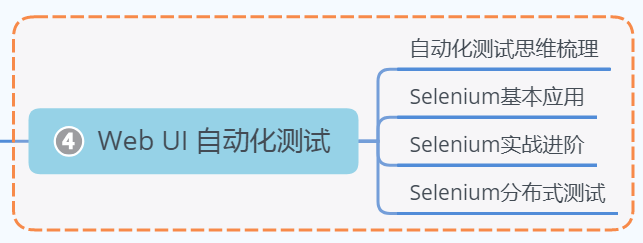
4、web/UI自动化测试
5、持续集成

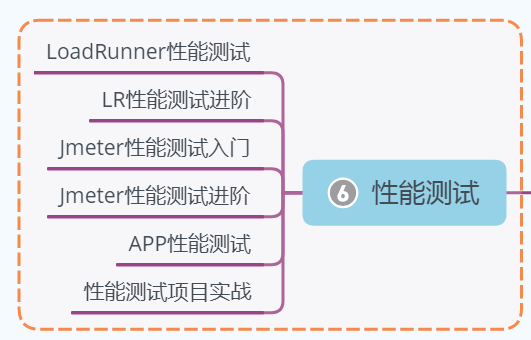
6、性能测试
7、web安全测试

8、测试开发

希望大家根据这个学习架构路线,不断地去摸索与提升,突破技术的瓶颈,可以说,这个过程会让你痛不欲生,但只要你熬过去了。以后的生活就轻松很多。正所谓万事开头难,只要迈出了第一步,你就已经成功了一半,等到完成之后再回顾这一段路程的时候,你肯定会感慨良多。
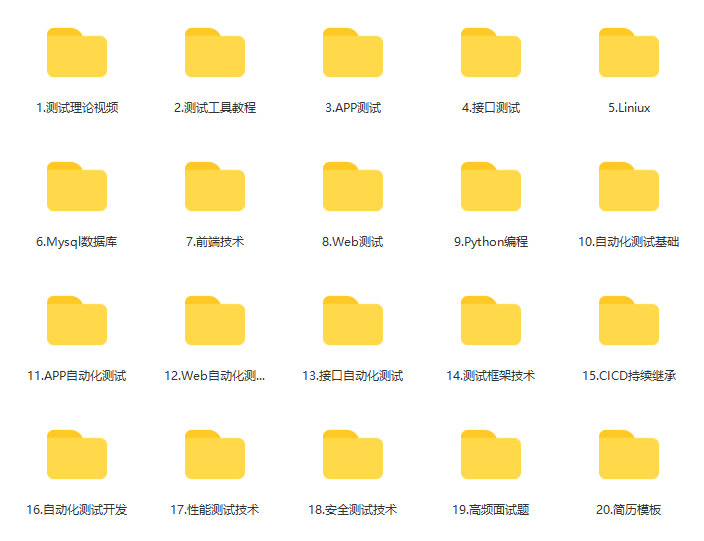
这些资料,以及上方的自动化测试进阶线路详细讲解,对于想进阶测试的朋友来说应该是最全面最完整的备战仓库,这个仓库也陪伴我走过了最艰难的路程,希望也能帮助到你!凡事要趁早,特别是技术行业,一定要提升技术功底。希望对大家有所帮助…….
