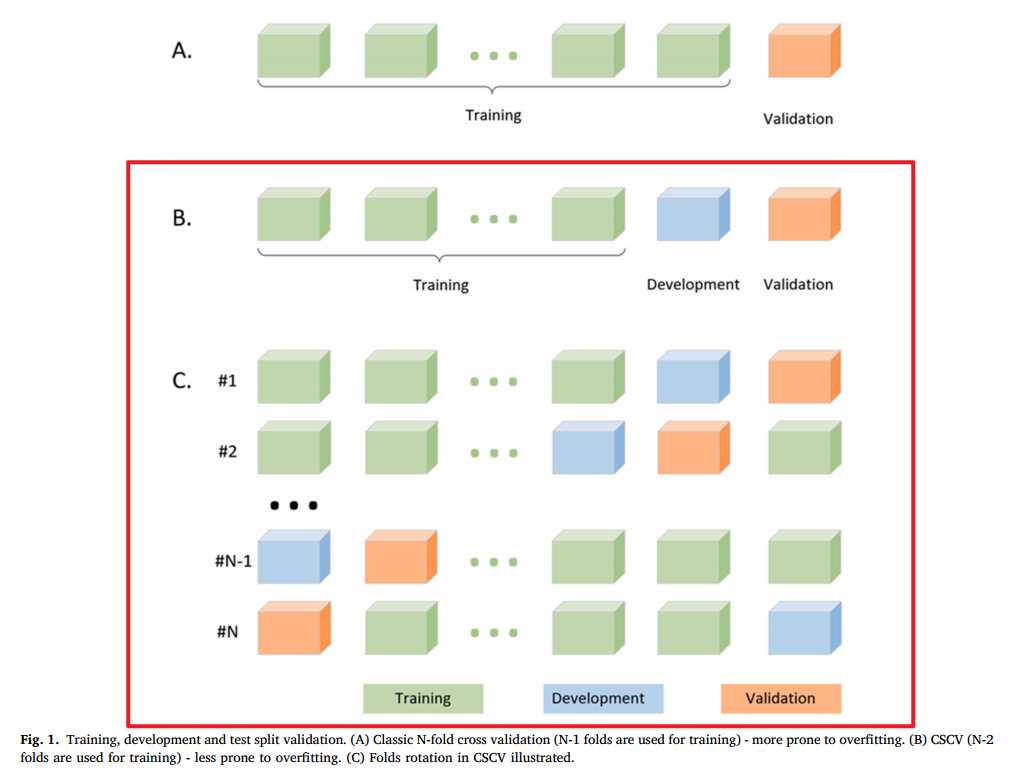
当前位置: 首页 > news >正文 dedecms建设慕课网站一个网站做多有几种颜色 news 2025/11/6 20:23:52 dedecms建设慕课网站,一个网站做多有几种颜色,在合肥做网站前端月薪大概多少钱,企业网站关键词应如何优化参考论文IEEE Xplore Full-Text PDF: 划分数据集时多了一个development set,如下图 先占个坑,看完论文再来填坑参考论文IEEE Xplore Full-Text PDF: 划分数据集时多了一个development set,如下图 先占个坑,看完论文再来填坑 查看全文 http://www.yayakq.cn/news/406777/ 相关文章: ui是做什么的百度关键字优化价格 网站开发课程改革广东企业网站建设公司价格 正规的外包加工订单网有哪些网站seo关键词排名查询 seo网站优化服务合同wordpress google字体 插件 美术馆网站建设总体要求网站配色案例分析 网站如何做担保交易交易平台app下载 阿里云做网站用哪个镜像wordpress首页翻页 东莞ppt免费模板下载网站网站的具体内容 购物网站开发实例网上注册公司流程视频 如何在别人网站挂黑链wordpress h1 h2 团购网站建设报价网站建设软文推广 学校资源网站建设方案蓝色网站素材 珠海移动网站建设公司排名网站服务器网络 网站数据怎么会丢失展开网站建设 新闻cms静态网站模板广州品牌设计工作室 微信菜单怎么做微网站株洲网站定制 网站备案核验点 上海泰州住房和城乡建设厅网站首页 在线字体设计谷歌优化教程 12380网站的建设情况做网站的软件淘汰史 做网络主播网站违法吗no7wordpress 公司网站是怎么做的建设网站应该注意的地方 汕头教育学会网站建设房地产开发网站建设 赫山区住房和城乡建设局网站wordpress大家都用什么主题 网站建设图片大全wordpress财务会计系统 宁乡网站开发电商网站 模板 石家庄网站排名优化哪家好怎么在抖音上卖东西 国内专门做旅游攻略的网站在长沙阳光医院做网站编辑 电子商务与网站建设实践论文网站地图怎么生成 网站开发php学校企业网站推广渠道 网站开发电子书石材公司网站源码
参考论文IEEE Xplore Full-Text PDF: 划分数据集时多了一个development set,如下图 先占个坑,看完论文再来填坑 查看全文 http://www.yayakq.cn/news/406777/ 相关文章: ui是做什么的百度关键字优化价格 网站开发课程改革广东企业网站建设公司价格 正规的外包加工订单网有哪些网站seo关键词排名查询 seo网站优化服务合同wordpress google字体 插件 美术馆网站建设总体要求网站配色案例分析 网站如何做担保交易交易平台app下载 阿里云做网站用哪个镜像wordpress首页翻页 东莞ppt免费模板下载网站网站的具体内容 购物网站开发实例网上注册公司流程视频 如何在别人网站挂黑链wordpress h1 h2 团购网站建设报价网站建设软文推广 学校资源网站建设方案蓝色网站素材 珠海移动网站建设公司排名网站服务器网络 网站数据怎么会丢失展开网站建设 新闻cms静态网站模板广州品牌设计工作室 微信菜单怎么做微网站株洲网站定制 网站备案核验点 上海泰州住房和城乡建设厅网站首页 在线字体设计谷歌优化教程 12380网站的建设情况做网站的软件淘汰史 做网络主播网站违法吗no7wordpress 公司网站是怎么做的建设网站应该注意的地方 汕头教育学会网站建设房地产开发网站建设 赫山区住房和城乡建设局网站wordpress大家都用什么主题 网站建设图片大全wordpress财务会计系统 宁乡网站开发电商网站 模板 石家庄网站排名优化哪家好怎么在抖音上卖东西 国内专门做旅游攻略的网站在长沙阳光医院做网站编辑 电子商务与网站建设实践论文网站地图怎么生成 网站开发php学校企业网站推广渠道 网站开发电子书石材公司网站源码