元氏县城有做网站广告的吗成都好玩还是重庆好玩
幻兽帕鲁是一款非常受欢迎的游戏,最近在社区中呈现了爆火的趋势,在线人数已经突破了百万级别。由于社区的热度不断上升,官方服务器开始出现了不稳定和卡人闪退的情况。搭建一个私人服务器可能是一个最稳定而舒适的解决方案。通过搭建私人服务器,玩家可以获得更好的游戏体验,避免官方服务器的不稳定问题。搭建私人服务器可以提供更稳定的游戏环境,并且你可以自由地设置规则和玩法,与朋友一起畅玩游戏,今天教大家10s部署一个自己的专属私服!!!
1.点击链接:一键部署幻兽帕鲁私服
2.设置管理员密码,点击部署:
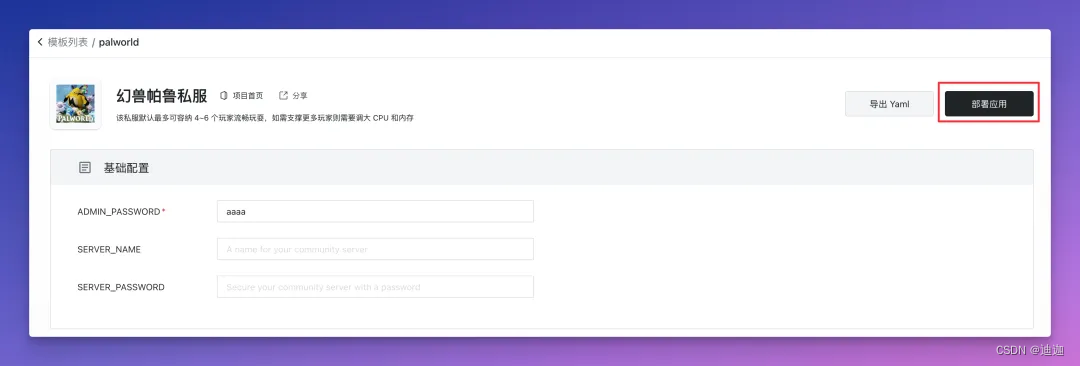
3. 还看什么 ? 然后就没有然后了,启动不会超过 40 秒,天下无敌 enjoy~

*转于 sealos公众号