汕头汽车网站建设ui设计学校
这是本系列文章的第一篇,旨在通过动手实践,帮助大家学习亚马逊云科技的生成式AI相关技能。通过这些文章,大家将掌握如何利用亚马逊云科技的各类服务来应用AI技术。
那么让我们开始今天的内容吧!
介绍
什么是Amazon Rekognition?
Amazon Rekognition是基于云的计算机视觉平台,提供软件即服务(SaaS)。
通过经过验证的高度可扩展的深度学习技术,Amazon Rekognition可以轻松地将图像和视频分析功能添加到您的应用程序中,而无需具备机器学习的专业知识。
它提供高度精确的面部分析和面部搜索功能,您可以利用这些功能进行用户身份验证、人数统计和公共安全等多种场景的检测、分析和比较。
服务功能:
- 标签识别
- 自定义标签
- 内容审核
- 文本检测
- 面部检测与分析
- 面部搜索与验证
- 名人识别
- 个人防护装备(PPE)检测
Amazon Lambda
- AWS Lambda是一种无服务器计算服务。
- 它无需任何服务器管理,允许我们执行任意类型的应用程序代码。
- 开发人员无需担心启动或管理AWS资源的步骤。
- 任务的配置以代码形式完成,实施在Lambda中,并在执行时运行。
- Lambda函数负责处理资源的预置和管理。
- AWS Lambda支持的编程语言包括Node.js、Python、C#、Java和Go。
- 它允许我们响应其他AWS服务的事件来运行代码。
- 根据工作负载的大小,Lambda自动进行扩展。
- Lambda代码通过来自AWS资源的触发器执行。
- AWS Lambda的成本非常低,费用取决于多个因素。它会按每100毫秒的运行时间以及代码的执行次数收费。
- Lambda函数的可允许运行时间在100毫秒到15分钟之间。
- 它提供从128MB内存到10GB内存的可变资源。
IAM角色
- IAM角色是AWS IAM身份(可以在我们的AWS账户中创建),具有特定的权限。
- 它类似于IAM用户,决定该身份在AWS中可以执行或无法执行的操作。
- 与直接将角色分配给特定用户或组不同,它可以被分配给任何需要它的人。
- 拥有角色的好处是我们不需要关联标准的长期凭证,如密码或访问密钥。
- 当资源承担某个特定角色时,它会为我们的角色会话提供临时安全凭证。
- 我们可以使用角色来访问没有权限访问AWS资源的用户、应用程序或服务。
- 根据我们的需求,可以为角色附加一个或多个策略。
- 例如,我们可以创建一个具有S3完全访问权限的角色,并将其分配给EC2实例,以便访问S3存储桶。
简单存储服务(S3)
- Amazon S3是一种简单的存储服务,我们可以随时、随地通过网络存储和检索任意数量的数据。
- 它为开发人员和用户提供高度可扩展、可靠、快速、廉价的数据存储基础设施。
- S3保证99.9%的可用性。
- S3设计用于存储最多5TB的数据。
- S3是全球化的,这意味着您可以在任何地区创建存储桶,并从任何地方访问它。因此,存储桶的名称必须是唯一的。
- 用户可以随时删除S3存储桶及其对象。
- 我们可以通过为不同用户授予不同权限来限制对存储桶的访问。
- S3还提供额外功能,如版本控制、静态网站托管、服务器访问日志记录、对象存储生命周期策略等。
架构图
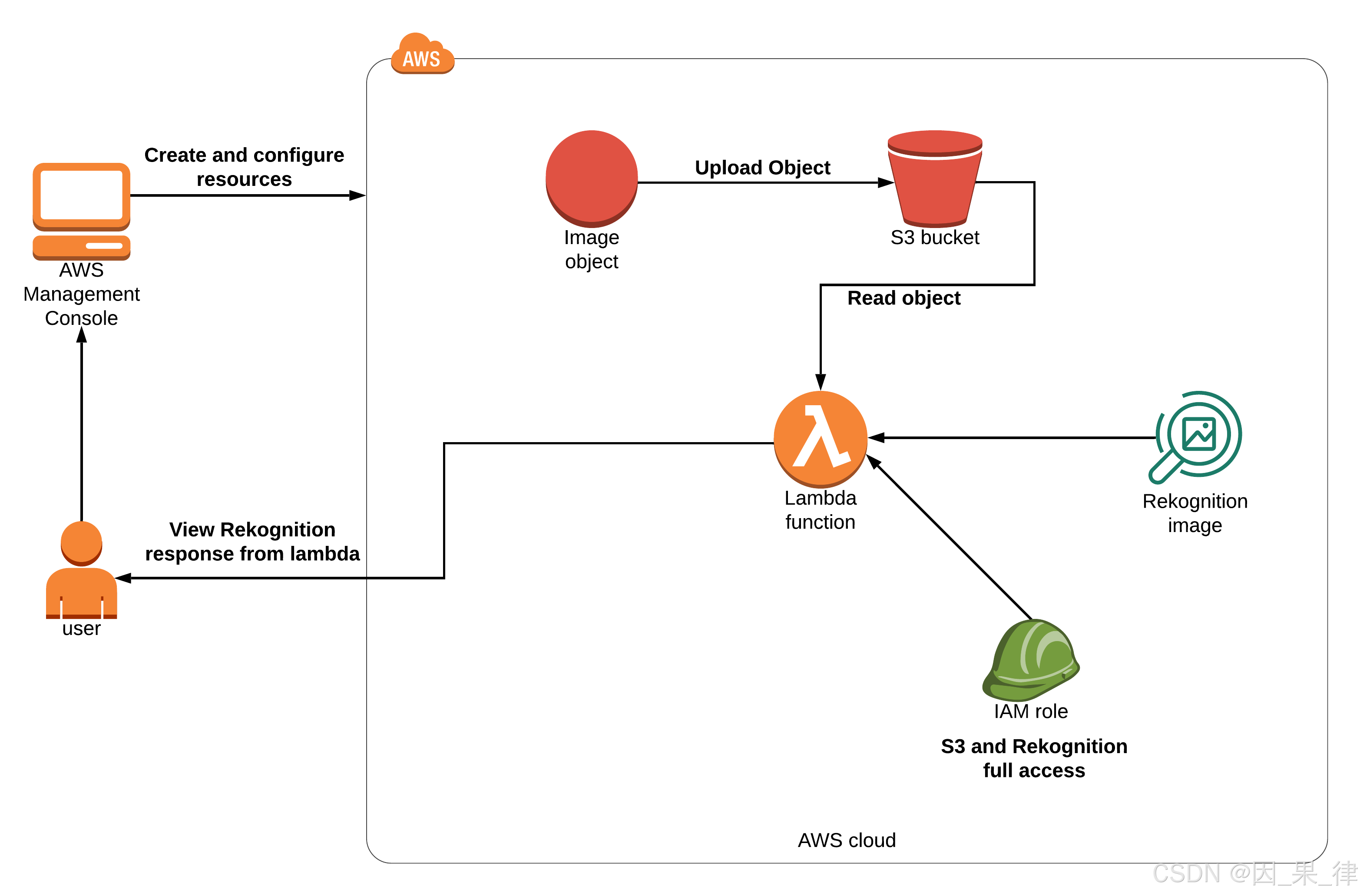
任务详情
-
创建S3存储桶并上传图
-
创建Lambda函
-
测试Lambda函数
任务1:创建S3存储桶并上传图像
在此任务中,我们将通过提供所需的配置来创建一个S3存储桶,并将图像上传到该存储桶。
- 导航到顶部的“服务”菜单,然后在“存储”部分点击S3。
- 在左侧菜单中选择“存储桶”,点击“创建存储桶”按钮并填写存储桶的详细信息。
-
存储桶名称: 输入
labs.rekognition.23
注意: 存储桶名称必须在Amazon S3中所有现有存储桶名称中是唯一的。如果您收到存储桶名称已存在的错误,请将存储桶名称的最后两位数字更改为任意随机数字。 -
区域: 选择 美国东部(弗吉尼亚北部)us-east-1
-
对象所有权: 选择 禁用ACL(推荐) 选项
-
阻止公共访问的存储桶设置: 取消选中“阻止所有公共访问”选项,并勾选“确认”复选框。
- 其他设置保持默认。
- 点击“创建存储桶”按钮。
3.现在您的S3存储桶已经创建好了。

4.点击您的存储桶名称。
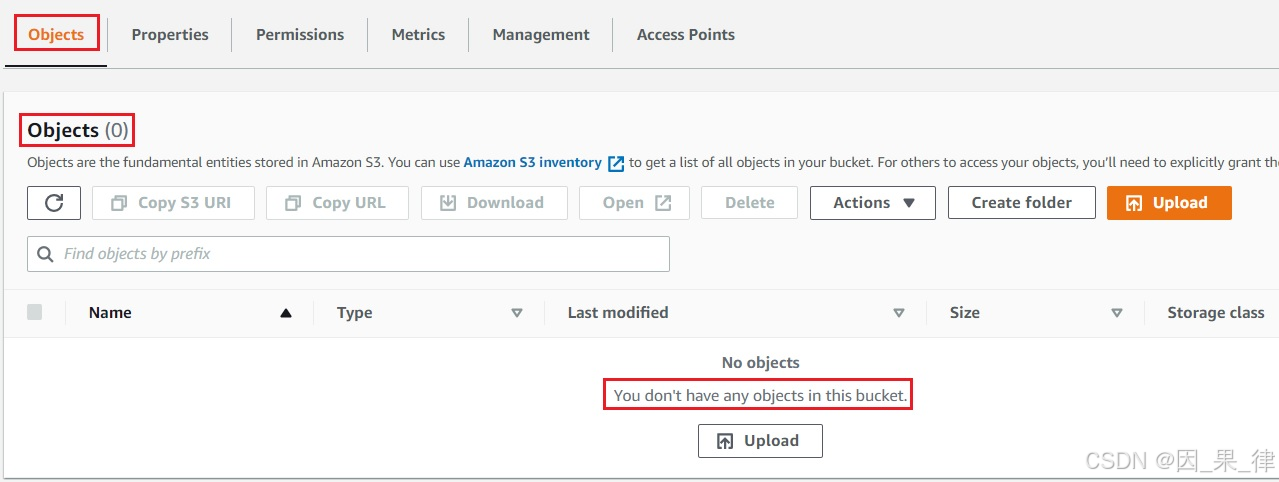
5.在“概览”中,您会看到以下消息:
"此存储桶中没有任何对象。"
6.注意:本实验室仅支持使用jpg、jpeg和PNG文件格式。其他格式不支持。
7.您可以从本地存储上传任何图像,或者从此链接下载示例图像:Download Me。
8.如果图像在新标签页中打开,请右键点击并将图像保存到您的本地机器上。保存后可以关闭该标签页。
9.上传文件到S3存储桶的步骤:
- 点击“上传”按钮。
- 点击“添加文件”按钮。
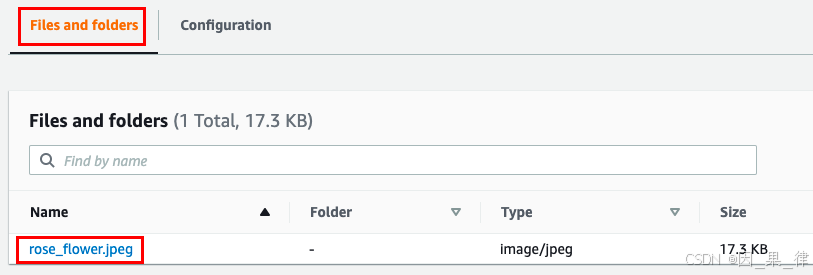
- 浏览本地图像文件,或选择下载的图像文件,文件名为:
rose_flower_54_11.jpeg。 - 点击“上传”按钮。
- 您可以在屏幕底部的传输面板中查看上传进度。
- 文件上传完成后,它将显示在存储桶中。
10.现在,点击屏幕右上角的“关闭”按钮。
任务2:创建Lambda函数
在此任务中,我们将通过提供名称、运行时、权限和代码等所需配置来创建一个Lambda函数。
- 确保您所在的区域是美国东部(弗吉尼亚北部)。
- 通过点击顶部的“服务”菜单导航到Lambda,然后在“计算”部分点击Lambda。
- 点击“创建函数”按钮。
- 选择“从头开始创建”按钮。
- 函数名称:输入
my_rekognition_Lambda。 - 运行时:选择
Python 3.8。 - 权限:点击“更改默认执行角色”,选择“使用现有角色”。
- 现有角色:从下拉列表中选择
Whiz_policy_role_<RANDOM_NUMBER>。 - 点击“创建函数”按钮。
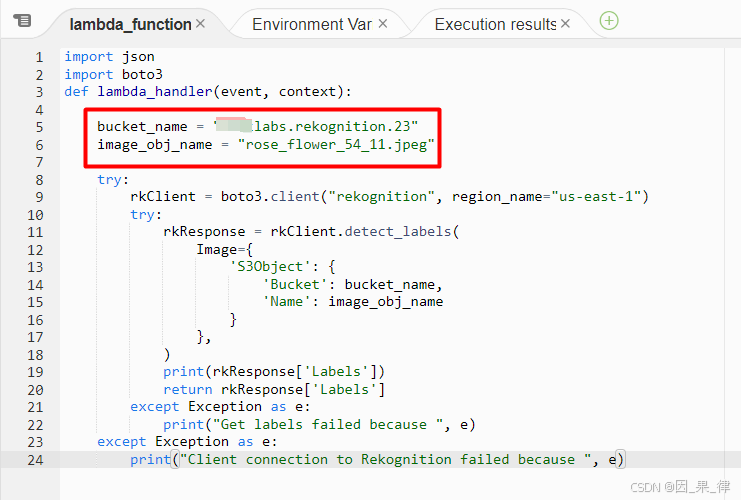
 4.在“代码”选项卡下,找到“代码源”部分,双击
4.在“代码”选项卡下,找到“代码源”部分,双击 lambda_function.py文件,然后将现有代码替换为以下代码。
import json
import boto3
def lambda_handler(event, context):bucket_name = "labs.rekognition.23"image_obj_name = "rose_flower_54_11.jpeg"try:rkClient = boto3.client("rekognition", region_name="us-east-1")try:rkResponse = rkClient.detect_labels(Image={'S3Object': {'Bucket': bucket_name,'Name': image_obj_name}},)print(rkResponse['Labels'])return rkResponse['Labels']except Exception as e:print("Get labels failed because ", e)except Exception as e:print("Client connection to Rekognition failed because ", e)注意:请将代码中的存储桶名称和对象名称替换为您自己的名称。
5.注意:如果您创建的存储桶名称不同或上传的对象与实验室中的不一致,输出/结果可能会有所不同。
6.点击“部署”按钮以保存函数。
任务3:测试Lambda函数
- 注意:请确保第6行和第7行的存储桶名称和对象名称与您的S3数据一致。
- 点击“测试”按钮,事件名称:输入
LambdaTest,然后点击“保存”按钮。 - 再次点击“测试”按钮。
- 现在,在Lambda的执行结果中,Rekognition将根据图像返回标签。
- 它将以JSON格式提供数据,包含标签名称以及它对从图像中检测到该标签的置信度。
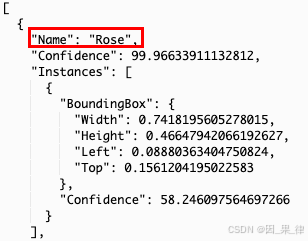

6.这就是我们使用Amazon Rekognition服务来检测图像中标签的方式。
结语
通过本次实验室操作,我们成功创建了一个S3存储桶并上传了图像,配置并部署了Lambda函数,同时利用Amazon Rekognition服务实现了对图像标签的自动检测。通过这一步步的实践,我们不仅了解了如何将Amazon Rekognition与AWS Lambda集成,还掌握了如何高效地处理图像分析任务。这种无服务器架构为应用程序的扩展性和自动化提供了强大的支持,是实现AI功能的有效途径。
lab内容参考自whizlabs平台的lab实验,如需想要完整练习上面内容推荐去相关平台进行学习。