学校网站改版wordpress怎么添加手机验证码
这是一篇关于学习方法的思考探索,当然我不会大篇文章介绍什么学习方法(因为我也不是这方面的专家?),这个只是总结一下我是如何学习GEE以及在学习中遇到问题时如何解决问题的。我写这篇文章的目的就是在和一些学习GEE的新同学接触的过程发现了很多问题,比如:
-
初学GEE的很多同学不知道为什么打不开GEE官方网址
-
很多学习GEE很久的人竟然不知道GEE有官方文档
-
使用GEE却不知道怎么查询GEE有哪些数据
-
运行报错不知道如何查找错误
-
很多人连互联网基本搜索功能都不会使用
-
等等
下面我就结合我自己学习和使用GEE的亲身经历,对比上述描述的一些问题来做一些简单的总结,希望大家可以从这些总结中可以获得一些灵感启发。
第一步、基本搜索能力
这里我简单说一下如何查找内容,因为后面无论哪一步我们都需要使用搜索。可能有人会反驳我,我们从小到大在学校接受的多年教育一直在强调的一件事情:“遇到问题要勤学多问,要虚心请教别人。”。这里我可能需要纠正很多刚从学校毕业或者是刚刚迈入职场的新人的思想,请教别人或许可以解决你的问题,但是过分依赖别人只能说你这个人非常不成熟,完全没有独自解决问题的能力,用现在比较流行的话叫做是一个“社会巨婴”。社会是非常现实的的社会,和学校是完全不同的,要记住还有一句老话:“教会徒弟,饿死师傅”,现实就是这么残酷,想要学习新的东西只能靠自己努力,想要完全依赖别人那纯粹是白日做梦。
接着说我们在国内可以使用的搜索引擎
(1)百度:百度一下,你就知道,虽然都说百度各种烂、不靠谱,但是人家的搜索能力还是摆在那里,目前国内还真没有几个能和百度叫嚣搜索能力的(仅限国内的公司,国际上的搜索引擎不算呀?)。不要老抱怨工具烂之类的话,合理使用工具才是最重要的。

(2)必应:必应,很多人可能在国内压根没有听说过这个搜索引擎,它是微软开发的一款搜索引擎,搜索能力还是非常棒的,只不过受限于用户比较少。

国际上的搜索引擎,这个不必说了大家都明白是谁了。但是使用这个需要会科学上网(这个怎么做自己去查资料)
(3)Google:https://www.google.com,搜索能力?。
我们学习所有的新的东西几乎都离不开常用的这三个搜索引擎,当然会有其他的搜索引擎比如搜狗之类的,但是我觉大部分人可能只会用百度或者Google。
第二步、了解背景知识
我们学习新的知识内容来源可能有很多,比如老师讲解、朋友介绍、看书籍查资料看到等等,无论哪种途径其实我们可以对我们要了解学习的内容有一个大概的了解。比如这个知识是做什么的、官方名字叫什么、去哪里可以查找到之类的。以GEE为例,当我们第一次听说它的时候,可能我们会问这是什么东西?全名叫什么?官方地址是什么?别人可能会告诉你GEE的全称叫做Google Earth Engine,是用来做遥感图像处理的在线工具,是Google做的。剩下的东西可能就需要我们自己搜索,比如使用不同引擎:
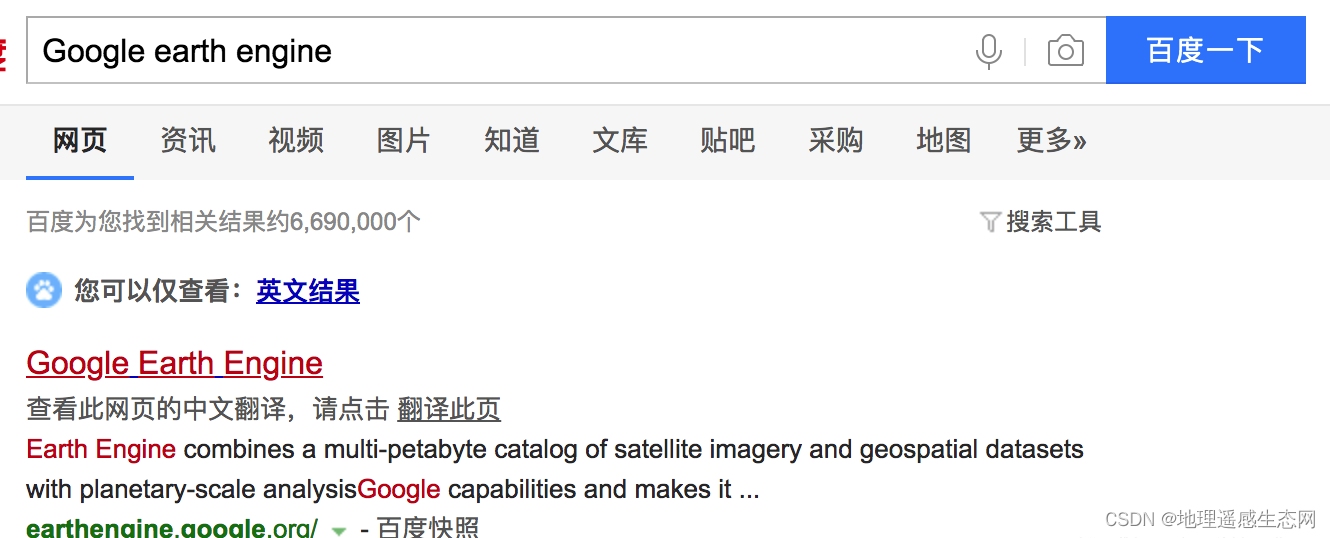
(1)百度,这次竟然是排在第一位,不可思议?,我们可以查看
(2)必应,输入关键词我们可以使用国际版或者国内版查询 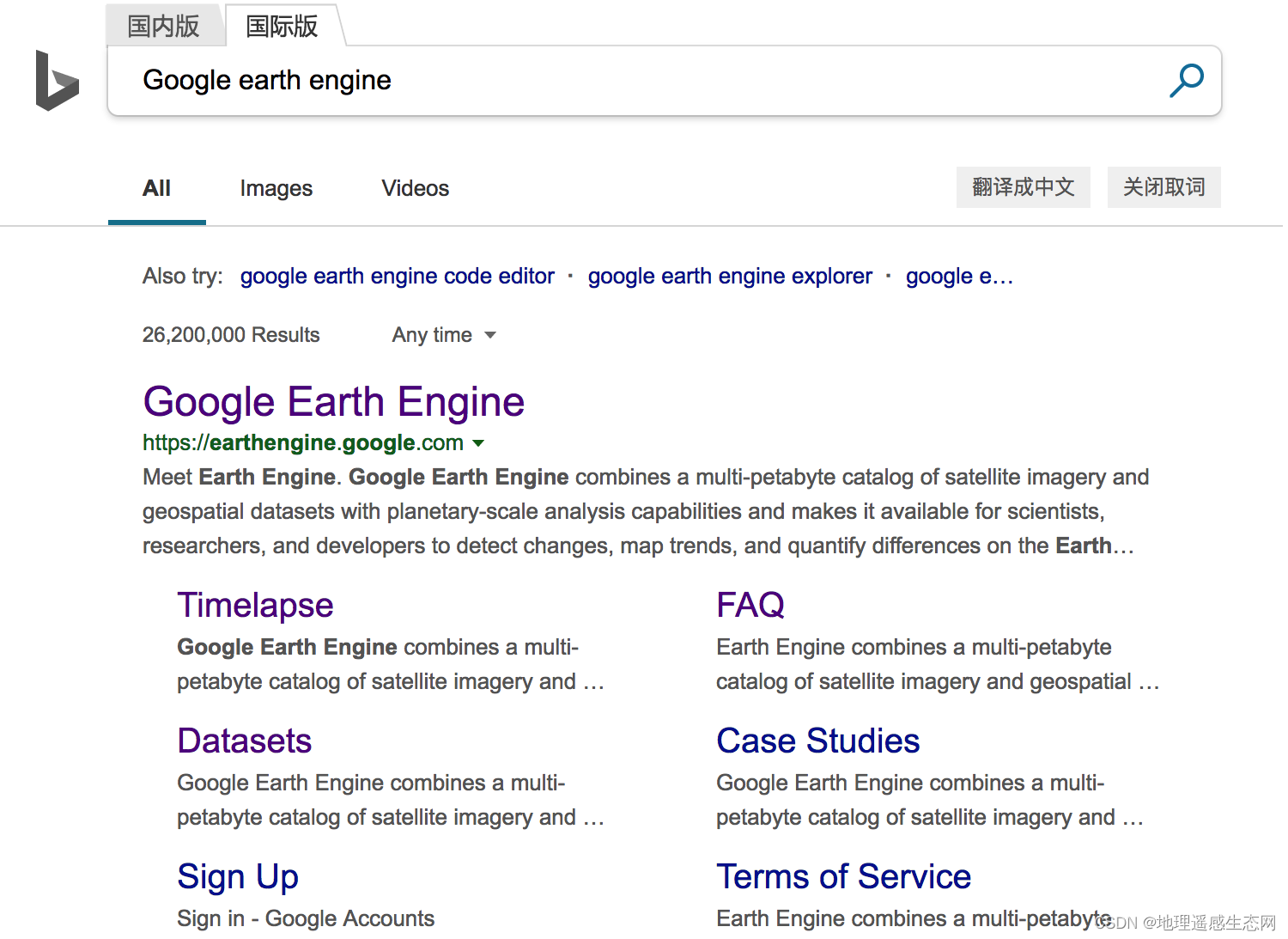
(3)Google
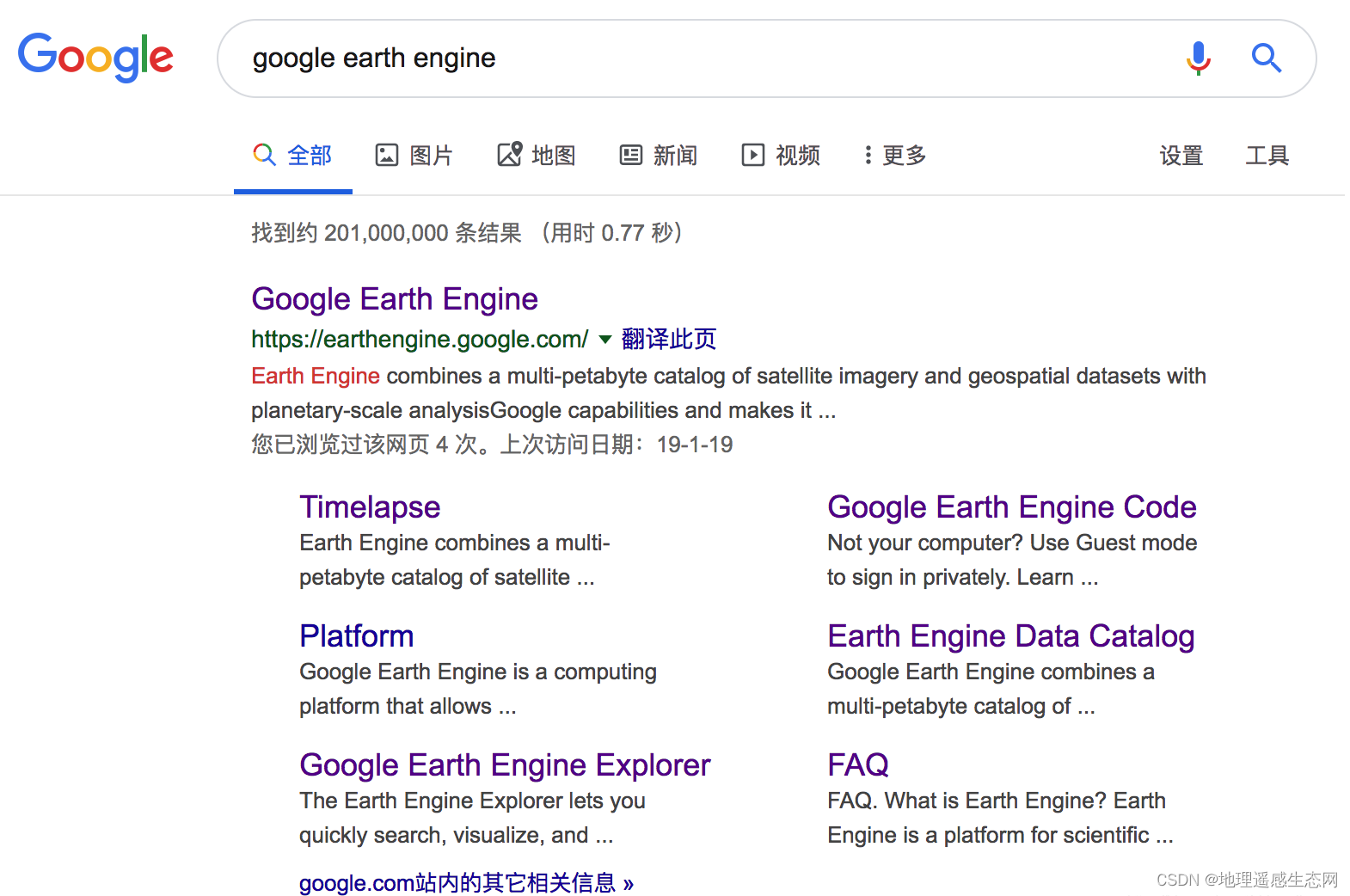
无论哪种搜索引擎,我们都可以找到GEE的官方网址是:http://earthengine.google.org/。这里需要注意的一点是我们直接是打不开这个网址的,这是Google开发的工具,所以我们无法直接登录,具体该怎么做自己找解决方案。只要找到官方网址,其实剩下的东西就非常简单,首先我们观察官方网站都是包括哪些内容:
![]()
从上面可以看到这里面包括了:数据介绍、常见问题、事例、学习资料、博客、注册流程等等非常详细的内容,大家从这里可以学习到GEE几乎官方所有的内容。知道了这些内容,下一步就是正式学习。
第三步、学习官方文档
无论是学习什么新的知识,我们第一步就是要查看这些新的知识、技能有没有官方的文档,官方的文档才是最权威的解释。GEE的官方文档:https://developers.google.com/earth-engine/

第四步、实际上手实践
一代老革命家说的非常好:“实践是检验真理的唯一标准!”,学习任何新的知识都是需要我们不断的实践才能逐渐掌握理解,所以要在编辑器:https://code.earthengine.google.com/中不断反复实践敲打我们学习的内容。
上面说的是如何学习GEE,那么在实践中我们会遇到各种各样的问题,遇到这些问题该如何做?下面以一些具体的例子来说明一下。
第一个例子,GEE上有没有Sentinel-2做过的大气校正数据?
类似这种问题其实就是在找GEE中有哪些数据,这个我们一种方式可以通过GEE提供的官方数据网站来查询,另外就是通过GEE编辑器中的搜索框来搜索。这里搜索也是有一定的技巧,我们不知道在GEE中是否有Sentinel-2大气校正数据,那么我们可以换种思路可以查找GEE中有哪些Sentinel-2数据。结果如下图:
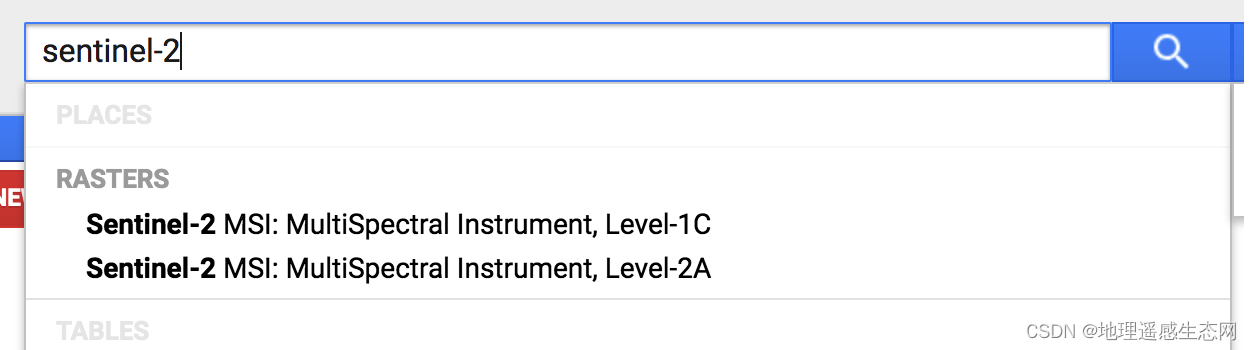
依次点开查看,我们发现Level-2A就是我们想要找的数据。遇到我们不熟悉的数据我们要善于利用搜索,包括GEE内部的搜索还是Google搜索等。
第二个例子,为什么我选择的地区没有Sentinel-2大气校正数据?
紧接上一个问题,如果我们查看Sentinel-2的SR数据介绍会发现如下内容:

这个数据是2017开始到现在的,那么我们做如下测试:
-
var roi = /* color: #d63000 */ee.Geometry.Point([116.13300781249995, 39.25326779648414]);
-
var s2_sr = ee.ImageCollection("COPERNICUS/S2_SR");
-
Map.centerObject(roi, 7);
-
Map.addLayer(roi, {color: "red"}, "roi");
-
var scol = s2_sr.filterBounds(roi)
-
.sort("system:time_start");
-
print(scol);
查看输出
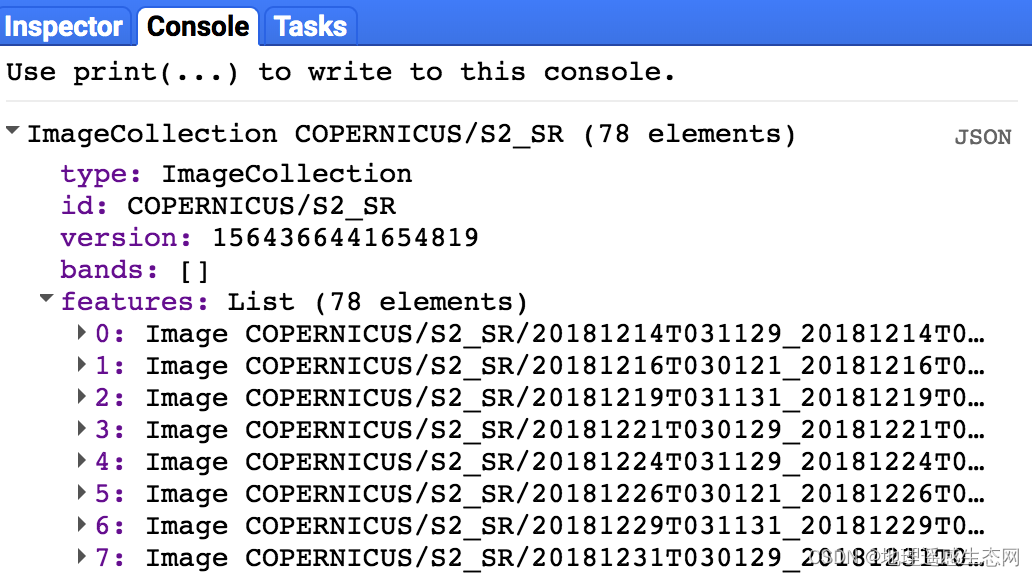
很多人没有看出问题,但是如果仔细观察会发现SR数据只有2018年12份之后的,这个并不是我们代码的错误,只是是GEE官方文档中关于SR数据说明没有写明白。它全部的数据是从2017年开始的,但是目前GEE还没有完全将这个SR数据导入进来。这个在使用时间筛选的时候一定要注意,还有就是GEE的文档也不能保证100%的正确,我们需要从多渠道来确认相关数据。
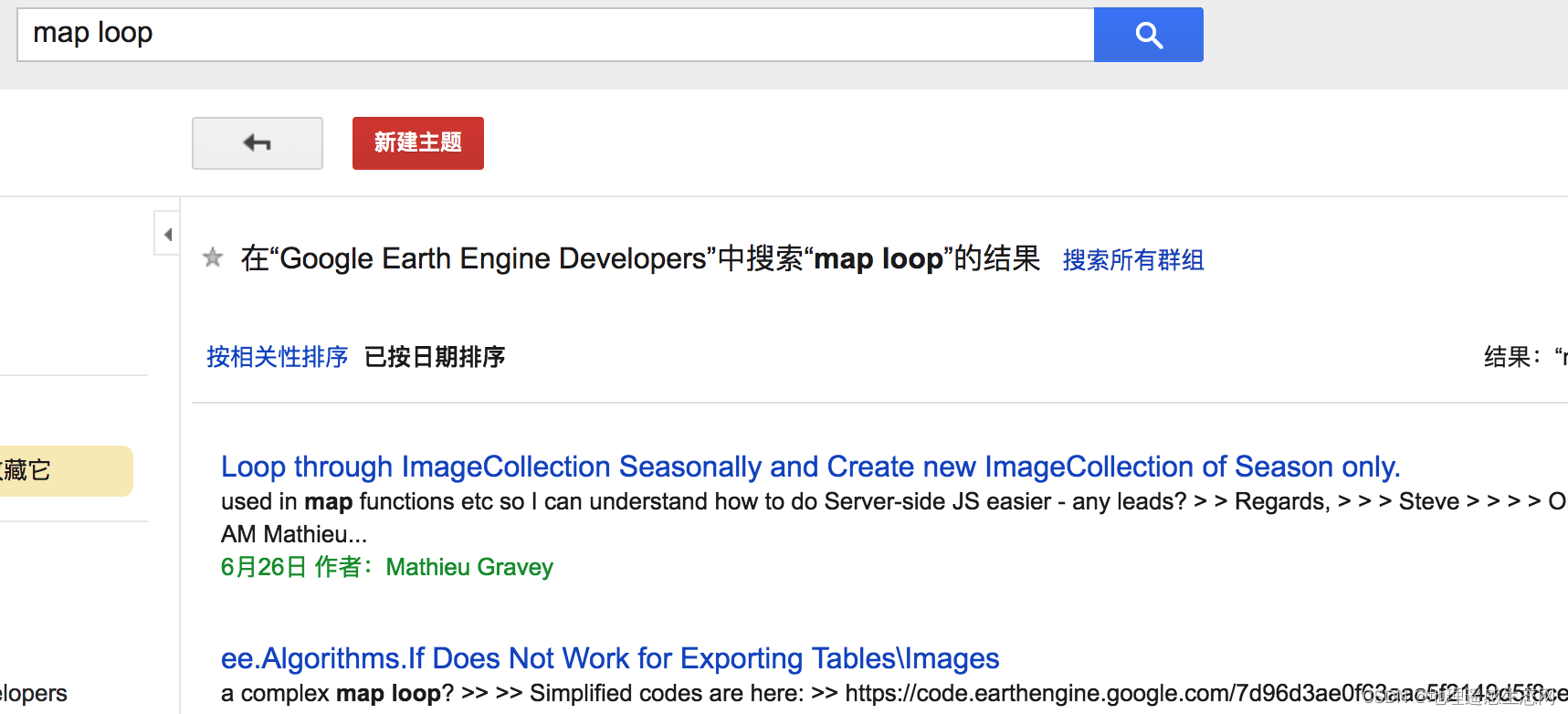
第三个例子,不会做map循环怎么办?
类似这种我们我们可以直接到官方文档中查看相关例子,或者到论坛中查找(https://groups.google.com/forum/#!forum/google-earth-engine-developers)。就以这个为例,我们在搜索框输入map loop这种关键字,那么就可以搜索GEE论坛的相关帖子。
第四个例子,GEE做的北京地区的平均海拔和已知的数据不匹配?
类似这种问题比较有意思,而且这个问题也是小伙伴问过我的一个问题,能遇到类似问题说明这个小伙伴也是经过了自己思考,然后查询了相关数据才问的,我这里简单说一下我是如何处理这个问题的。
(1)先计算北京地区的平均海拔是多少
-
var province = ee.FeatureCollection("users/wangweihappy0/shape/china_albers_province");
-
var srtm = ee.Image("USGS/SRTMGL1_003");
-
var roi = province.filter(ee.Filter.eq("ad2004", 110000));
-
Map.addLayer(roi, {color: "red"}, "roi");
-
var image = srtm.clip(roi);
-
Map.addLayer(image, {min:0, max:500}, "image");
-
var dict = image.reduceRegion({
-
reducer: ee.Reducer.mean(),
-
geometry: roi.geometry().bounds(),
-
scale: 30,
-
maxPixels: 1e13,
-
tileScale: 16
-
});
-
print(dict);
运行结果:
计算结果:
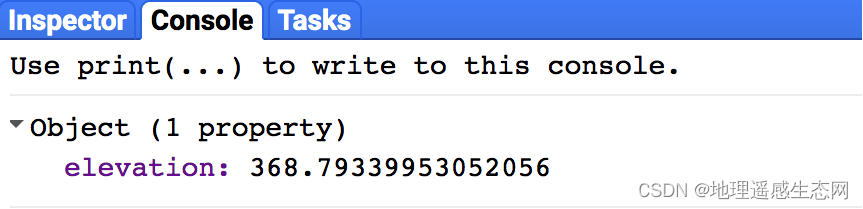
(2)查询资料,来源于维基百科(和百度百科中的数据一致)

(3)数据分析
我们使用GEE计算的平均海拔是300多米,这里显示平均海拔只有43.5米。问题出在哪里?具体哪个数据是对的?我们在仔细看一下维基百科中的描述是“北京市”,并不是北京地区,而且后面还说了一个“平原”和“山地”(查询百度百科可以知道平原占32%,山地占68%)。问题就在这里我们使用GEE计算的是北京地区包括整个地区,而百科中写的只是“北京市”也就是北京的平原有人居住的地区平均海拔,因此这两个平均值肯定不一样。
来源请引用:地理遥感生态网科学数据注册与出版系统。