深圳做自适应网站设计设计网站排行榜前十名
一、前言
本章主要讲述,如何获取设备名称以及guid,采集设备的采集格式识别,设备的插拔
设备列表以及属性的获取使用的directshow(后续的MediaFoundation无法获取OBS摄像头)
设备的插拔使用的是QT 捕获系统消息,捕获到设备插拔后,重新获取下设备列表(这里并没有动态的添加或者删除,考虑的主要是维护UI显示时 设备顺序的一致性)
二、设备列表的获取
ICreateDevEnum 接口,创建特定的类(如视频捕获设备,音频捕获设备,视频压缩等)的一个枚举器 ,可以使用CLSID_SystemDeviceEnum来得到该指针。
CreateDevEnum::CreateClassEnumerator(
REFCLSID clsidDeviceClass, //设备类别
IEnumMoniker **ppEnumMoniker, //输出参数,IEnumMoniker ××
DWORD dwFlags
);IEnumMoniker 接口, 表示特定的设备枚举类
IMoniker::Enum 方法获取指向 IEnumMoniker 实现的指针,该实现可以通过名字对象的组件向前或向后枚举。
IRunningObjectTable::EnumRunning 方法返回一个指向 IEnumMoniker 实现的指针,该实现可以枚举在运行对象表中注册的名字对象。
IEnumMoniker::Next 此方法检索枚举序列中下一个设备是否存在
struct CameraDevice
{int nIndex; // indexstd::string uid; // 硬件层uniqueId mac中为BuiltInMicrophoneDevice std::string name; // 设备名称
};std::map<std::string, CameraDevice> VideoCoreDevice::getVideoDeviceList()
{if(!m_pDevEnum){::CoCreateInstance(CLSID_SystemDeviceEnum, NULL, CLSCTX_INPROC, IID_ICreateDevEnum, (void**)&m_pDevEnum);}std::map<std::string, CameraDevice> devices;if (!m_bCoUninitializeIsRequired){goto END;}HRESULT hr = m_pDevEnum->CreateClassEnumerator(CLSID_VideoInputDeviceCategory, &m_pMonikerDevEnum, 0);if (hr != NOERROR){std::cout << "CreateClassEnumerator failed" << std::endl;goto END;}m_pMonikerDevEnum->Reset();ULONG cFetched;IMoniker* pM;int index = 0;while (S_OK == m_pMonikerDevEnum->Next(1, &pM, &cFetched)) {IPropertyBag* pBag;hr = pM->BindToStorage(0, 0, IID_IPropertyBag, (void**)&pBag);if (S_OK == hr) {// Find the description or friendly name.VARIANT varName;VariantInit(&varName);hr = pBag->Read(L"Description", &varName, 0);if (FAILED(hr)) {hr = pBag->Read(L"FriendlyName", &varName, 0);}if (SUCCEEDED(hr)) {// ignore all VFW driversif ((wcsstr(varName.bstrVal, (L"(VFW)")) == NULL) &&(_wcsnicmp(varName.bstrVal, (L"Google Camera Adapter"), 21) != 0)) {// Found a valid device.{char device_name[256] = { 0 };char unique_name[256] = { 0 };char product_name[256] = { 0 };int convResult = WideCharToMultiByte(CP_UTF8, 0, varName.bstrVal, -1, (char*)device_name, sizeof(device_name), NULL, NULL);if (convResult == 0){std::cout << "WideCharToMultiByte failed" << std::endl;goto END;}hr = pBag->Read(L"DevicePath", &varName, 0);if (FAILED(hr)){strncpy_s((char*)unique_name, sizeof(unique_name),(char*)device_name, convResult);}else{convResult = WideCharToMultiByte(CP_UTF8, 0, varName.bstrVal, -1, (char*)unique_name, sizeof(unique_name), NULL, NULL);if (convResult == 0){std::cout << "WideCharToMultiByte failed" << std::endl;goto END;}}GetProductId(unique_name, product_name, sizeof(product_name));CameraDevice camera;camera.nIndex = index;camera.name = device_name;camera.uid = unique_name;devices.insert(std::make_pair(camera.uid, camera));}++index; // increase the number of valid devices}}VariantClear(&varName);pBag->Release();pM->Release();}}END:return devices;
}// 不同获取方式得到的ID不一致,通过处理得到相同的ID
void GetProductId(const char* devicePath, char* productUniqueIdUTF8, uint32_t productUniqueIdUTF8Length)
{*productUniqueIdUTF8 = '\0';char* startPos = strstr((char*)devicePath, "\\\\?\\");if (!startPos) {strncpy_s((char*)productUniqueIdUTF8, productUniqueIdUTF8Length, "", 1);std::cout << "Failed to get the product Id" << std::endl;return;}startPos += 4;char* pos = strchr(startPos, '&');if (!pos || pos >= (char*)devicePath + strlen((char*)devicePath)) {strncpy_s((char*)productUniqueIdUTF8, productUniqueIdUTF8Length, "", 1);std::cout << "Failed to get the product Id" << std::endl;return;}// Find the second occurrence.pos = strchr(pos + 1, '&');uint32_t bytesToCopy = (uint32_t)(pos - startPos);if (pos && (bytesToCopy < productUniqueIdUTF8Length) &&bytesToCopy <= kVideoCaptureProductIdLength) {strncpy_s((char*)productUniqueIdUTF8, productUniqueIdUTF8Length,(char*)startPos, bytesToCopy);}else{strncpy_s((char*)productUniqueIdUTF8, productUniqueIdUTF8Length, "", 1);std::cout << "Failed to get the product Id" << std::endl;}
}
三、设备的插拔检测
目前使用的是Qt::nativeEventFilter 过滤设备插拔信息,然后去响应设备列表
// 头文件
#pragma once
#include <QWidget>
#include <QUuid>
#include <QAbstractNativeEventFilter>
#include <Windows.h>
#include <QHash>class VideoNotificationClient : public QAbstractNativeEventFilter, public QWidget
{
public:class Listener{public:virtual void onDeviceAdded(const std::string& uid) = 0;virtual void onDeviceRemoved(const std::string& uid) = 0;};public:void initialized();void uninstallFilter();bool nativeEventFilter(const QByteArray& eventType, void* message, long* result) override;public:VideoNotificationClient(VideoNotificationClient::Listener* listener);~VideoNotificationClient();private:bool m_bInitialized;QHash<QUuid, HDEVNOTIFY> m_hSevNotifys;VideoNotificationClient::Listener* m_pListener;
};//源文件
#include "VideoNotificationClient.h"
#include <QDebug>
#include <iostream>
#include <Windows.h>
#include <Dbt.h>
#include <devguid.h>
//具体的设备guid如usbiodef需要initguid
#include <initguid.h>
//USB设备
//GUID_DEVINTERFACE_USB_DEVICE
#include <usbiodef.h>
//HID人机交互设备-鼠标键盘等
#include <hidclass.h>
//GUID_DEVINTERFACE_KEYBOARD
#include <ntddkbd.h>
//GUID_DEVINTERFACE_MOUSE
#include <ntddmou.h>
#include <QCoreApplication>
#pragma comment(lib, "user32.lib")
#pragma comment(lib, "setupapi.lib")static const GUID GUID_DEVINTERFACE_LIST[] =
{// GUID_DEVINTERFACE_CAMERA_DEVICE { 0x65E8773D, 0x8F56, 0x11D0, { 0xA3, 0xB9, 0x00, 0xA0, 0xC9, 0x22, 0x31, 0x96 } },// GUID_DEVINTERFACE_USB_DEVICE { 0xA5DCBF10, 0x6530, 0x11D2, { 0x90, 0x1F, 0x00, 0xC0, 0x4F, 0xB9, 0x51, 0xED } },// GUID_DEVINTERFACE_DISK { 0x53f56307, 0xb6bf, 0x11d0, { 0x94, 0xf2, 0x00, 0xa0, 0xc9, 0x1e, 0xfb, 0x8b } },// GUID_DEVINTERFACE_HID, { 0x4D1E55B2, 0xF16F, 0x11CF, { 0x88, 0xCB, 0x00, 0x11, 0x11, 0x00, 0x00, 0x30 } },// GUID_NDIS_LAN_CLASS { 0xad498944, 0x762f, 0x11d0, { 0x8d, 0xcb, 0x00, 0xc0, 0x4f, 0xc3, 0x35, 0x8c } },// GUID_DEVINTERFACE_COMPORT{ 0x86e0d1e0, 0x8089, 0x11d0, { 0x9c, 0xe4, 0x08, 0x00, 0x3e, 0x30, 0x1f, 0x73 } },// GUID_DEVINTERFACE_SERENUM_BUS_ENUMERATOR{ 0x4D36E978, 0xE325, 0x11CE, { 0xBF, 0xC1, 0x08, 0x00, 0x2B, 0xE1, 0x03, 0x18 } },// GUID_DEVINTERFACE_PARALLEL{ 0x97F76EF0, 0xF883, 0x11D0, { 0xAF, 0x1F, 0x00, 0x00, 0xF8, 0x00, 0x84, 0x5C } },// GUID_DEVINTERFACE_PARCLASS{ 0x811FC6A5, 0xF728, 0x11D0, { 0xA5, 0x37, 0x00, 0x00, 0xF8, 0x75, 0x3E, 0xD1 } }
};VideoNotificationClient::VideoNotificationClient(VideoNotificationClient::Listener *listener): QWidget(nullptr), m_bInitialized(false), m_pListener(listener)
{this->hide();qApp->installNativeEventFilter(this);
}VideoNotificationClient::~VideoNotificationClient()
{uninstallFilter();qApp->removeNativeEventFilter(this);
} void VideoNotificationClient::initialized()
{HANDLE winid = (HANDLE)this->winId();if (!winid){return;}//注册插拔事件HDEVNOTIFY hDevNotify;DEV_BROADCAST_DEVICEINTERFACE NotifacationFiler;ZeroMemory(&NotifacationFiler, sizeof(DEV_BROADCAST_DEVICEINTERFACE));NotifacationFiler.dbcc_size = sizeof(DEV_BROADCAST_DEVICEINTERFACE);NotifacationFiler.dbcc_devicetype = DBT_DEVTYP_DEVICEINTERFACE;for (int i = 0; i < sizeof(GUID_DEVINTERFACE_LIST) / sizeof(GUID); i++){NotifacationFiler.dbcc_classguid = GUID_DEVINTERFACE_LIST[i];hDevNotify = RegisterDeviceNotification(winid, &NotifacationFiler, DEVICE_NOTIFY_WINDOW_HANDLE);if (!hDevNotify){qDebug() << "注册失败" << endl;m_bInitialized = false;return;}m_hSevNotifys.insert(QUuid(NotifacationFiler.dbcc_classguid), hDevNotify);}m_bInitialized = true;}void VideoNotificationClient::uninstallFilter()
{for (HDEVNOTIFY handle : qAsConst(m_hSevNotifys)){::UnregisterDeviceNotification(handle);}m_hSevNotifys.clear();
}bool VideoNotificationClient::nativeEventFilter(const QByteArray& eventType, void* message, long* result)
{Q_UNUSED(result);MSG* msg = reinterpret_cast<MSG*>(message);int msgType = msg->message;if (msgType == WM_DEVICECHANGE){PDEV_BROADCAST_HDR lpdb = (PDEV_BROADCAST_HDR)msg->lParam;switch (msg->wParam) {case DBT_DEVICEARRIVAL:if (lpdb->dbch_devicetype = DBT_DEVTYP_DEVICEINTERFACE){PDEV_BROADCAST_DEVICEINTERFACE pDevInf = (PDEV_BROADCAST_DEVICEINTERFACE)lpdb;GUID cameraGuid = { 0x65E8773D, 0x8F56, 0x11D0, { 0xA3, 0xB9, 0x00, 0xA0, 0xC9, 0x22, 0x31, 0x96 } };if (cameraGuid == pDevInf->dbcc_classguid){QString devicePath = QString::fromWCharArray(pDevInf->dbcc_name);QStringList parts = devicePath.split('#');if (parts.length() != 4){qDebug() << "camera logic error";return false;}QString usbPortStr = parts[2];QStringList usbPortParts = usbPortStr.split('&');if (usbPortParts.length() != 4){qDebug() << "camera logic error";return false;} if ("0000" != usbPortParts[3]){return false;}devicePath = devicePath.toLower();m_pListener->onDeviceAdded(devicePath.toStdString());//emit cameraPlugged(true, devicePath);}}break;case DBT_DEVICEREMOVECOMPLETE:if (lpdb->dbch_devicetype = DBT_DEVTYP_DEVICEINTERFACE){PDEV_BROADCAST_DEVICEINTERFACE pDevInf = (PDEV_BROADCAST_DEVICEINTERFACE)lpdb;GUID cameraGuid = { 0x65E8773D, 0x8F56, 0x11D0, { 0xA3, 0xB9, 0x00, 0xA0, 0xC9, 0x22, 0x31, 0x96 } };if (cameraGuid == pDevInf->dbcc_classguid){// USB拔出马上触发QString devicePath = QString::fromWCharArray(pDevInf->dbcc_name);QStringList parts = devicePath.split('#');if (parts.length() != 4){qDebug() << "camera logic error";return false;}QString usbPortStr = parts[2];QStringList usbPortParts = usbPortStr.split('&');if (usbPortParts.length() != 4){qDebug() << "camera logic error";return false;}if ("0000" != usbPortParts[3]){return false;}devicePath = devicePath.toLower();m_pListener->onDeviceRemoved(devicePath.toStdString());}}break;}}return false;
}
四、设备插拔库设计
项目完整代码,在后续的文章中给出
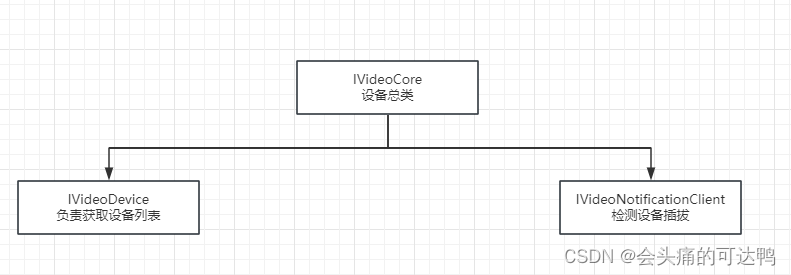
// camra
struct CameraDevice
{int nIndex = 0; // indexstd::string uid = ""; // 硬件层uniqueId mac中为BuiltInMicrophoneDevice std::string name = ""; // 设备名称
};// IVideoCore
class VIDEODEVICE_SHARED_EXPORT IVideoCore
{
public:static IVideoCore* getInstance();virtual void addListener(IVideoDeviceListner* listner) = 0;virtual void removeListener(IVideoDeviceListner* listner) = 0;virtual std::map<std::string, CameraDevice> getVideoDevicesList() = 0;
};// IVideoDevice
class VIDEODEVICE_SHARED_EXPORT IVideoDevice
{
public:virtual bool initlized() = 0;virtual std::map<std::string, CameraDevice> getVideoDevicesList() = 0;virtual void addListener(IVideoDeviceListner* listener) = 0;virtual void removeListener(IVideoDeviceListner* listener) = 0;};// IVideoDeviceListner
class VIDEODEVICE_SHARED_EXPORT IVideoDeviceListner
{
public:virtual void onDeviceAdded(CameraDevice device) = 0;virtual void onDeviceRemoved(CameraDevice device) = 0;virtual void onDeviceListUpdate(std::map<std::string, CameraDevice> cameraList) = 0;
};class VideoNotificationClient
{
public:class Listener{public:virtual void onDeviceAdded(const std::string& uid) = 0;virtual void onDeviceRemoved(const std::string& uid) = 0;};
}