学校网站的服务器许昌市网站建设
文章目录
- 预备 数据和执行语句
- Expand
- 第一次HashAggregate
- Shuffle and Second HashAggregate
- 最后结果
- 性能
- 原文
预备 数据和执行语句
SELECT COUNT(*), SUM(items), COUNT(DISTINCT product), COUNT(DISTINCT category)
FROM orders;
假设源数据分布在两个1核的结点上,数据就8行

Expand
spark把count distinct操作转换成count操作。
第一步是对每个要count distinct的列,生成新的行(这里是product和category列),当然原来不需要distinct聚合的列也在。
原来items列不需要distinct,product和category列要distinct,所以数据膨胀了2倍。原来8条数据,现在是8*(1+2)=24条
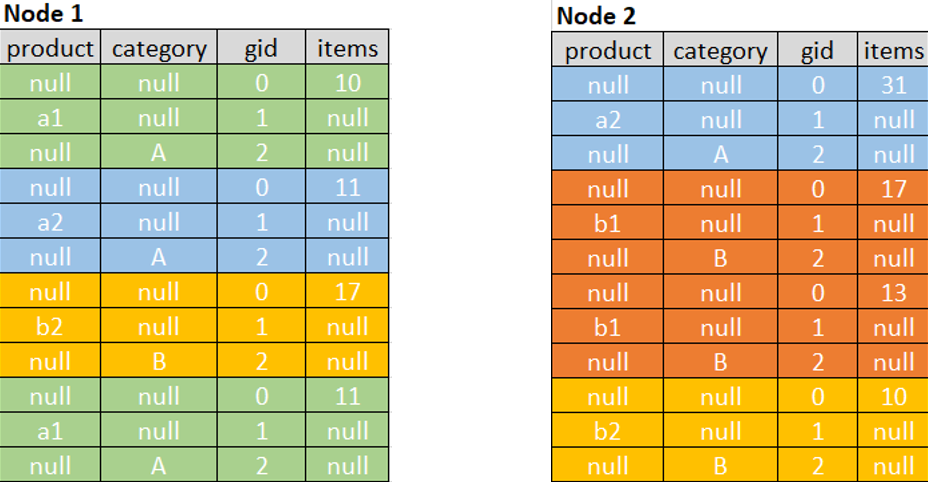
spark加了gid这一列,值为0代表所有非distinct聚合(这里是count(*)和sum(items)),值为1和2分别代表其他distinct聚合(这里1代表product,2代表category)。
NULL是怎么赋值的:对输入列来说,每行只有1个非空值。在spark的物理执行计划中,可以看到操作是这样的
ExpandInput: [product, category, items]Arguments: [[null, null, 0, items],[product, null, 1, null],[null, category, 2, null]]
第一次HashAggregate
Spark使用所有count distinct的列和gid作为关键字(product、category和gid)对行进行局部散列,并对非distinct的聚合(count(*)和SUM(items))执行局部局部聚合:
相当于执行了select product,category,gid,count(*) cnt,sum(items) items from 膨胀后的表 group by product,category,gid
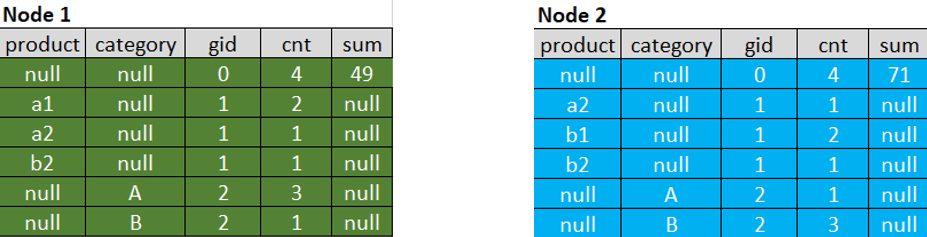
这可以使得膨胀后的数据变小。
如果不同值的数量比较少,减少的数据是相当可观的,最终结果可能比原始数据还要少。
可以看到原来每个结点上有4行,膨胀后是12行,局部聚合后变成了6行。
Shuffle and Second HashAggregate
在每个结点内部HashAggregate后,经过shuffle后变成这样

重新再每个结点做局部shuffle,得到
(相当于执行了select product,category,gid,count(*) cnt,sum(items) items from 膨胀后的表 group by product,category,gid)

这一步使得所有键都变成了唯一的。
最后结果
现在所有行可以合并成一个partition,再次HashAggregation,但这次不用group by product, category和gid
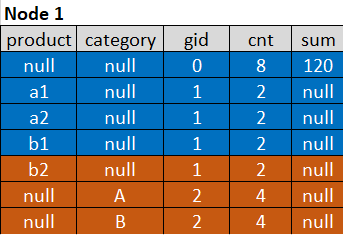
现在再也没有重复值了,简单的count和根据gid筛选就可以得到想要的count distinct结果
cnt FILTER (WHERE gid = 0),sum FILTER (WHERE gid = 0),COUNT(product) FILTER (WHERE gid = 1),COUNT(category) FILTER (WHERE gid = 2)Result:
COUNT(*): 8SUM(items): 120COUNT(DISTINCT product): 4COUNT(DISTINCT category): 2
性能
- 如果不同值的数量比较少,那么即使膨胀后,最后要shuffle的行也很少,这样因为spark局部聚合的原因,count distinct是相对比较快的
- 如果不同值的数量很多,并且你在一个语句中使用多个count distinct对不同的列。那么要shuffle行因为膨胀会很多,局部聚合也不能有效遏制数据的膨胀,那么要让查询语句成功执行需要消耗更多的executor内存。
原文
Distributed COUNT DISTINCT – How it Works in Spark, Multiple COUNT DISTINCT, Transform to COUNT with Expand, Exploded Shuffle, Partial Aggregations – Large-Scale Data Engineering in Cloud (cloudsqale.com)