岱山建设网站新手网站设计看哪本书
一、创建数据库实例
1.点击“开始” -> “Oracle -OraDb11g_home1” -> “Database Configuration Assistant”
2.点击“下一步”
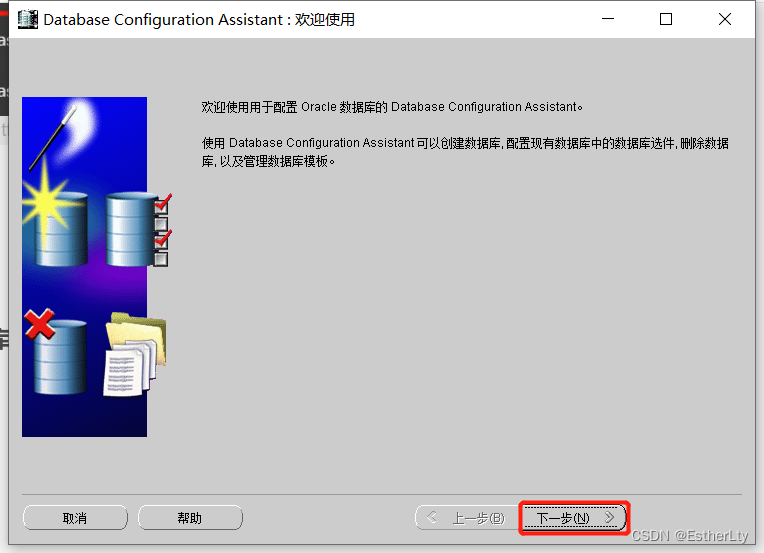
3.选择“创建数据库”,点击“下一步”
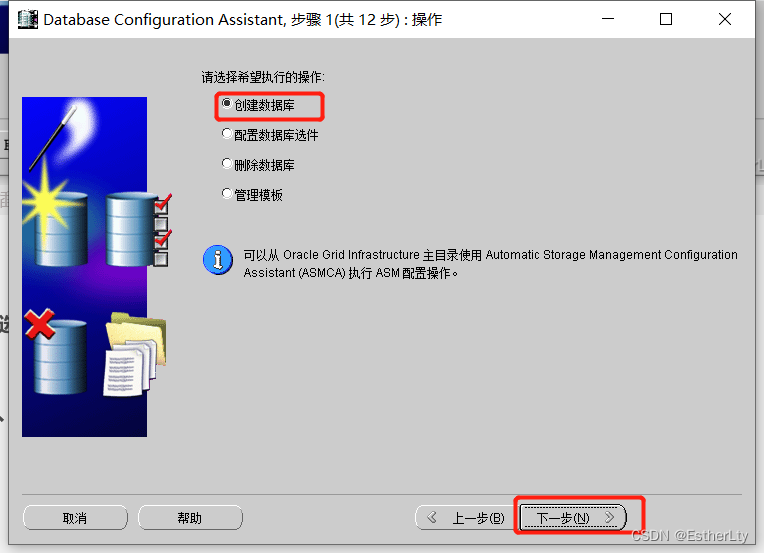
4.默认设置,不用更改,直接点击“下一步”
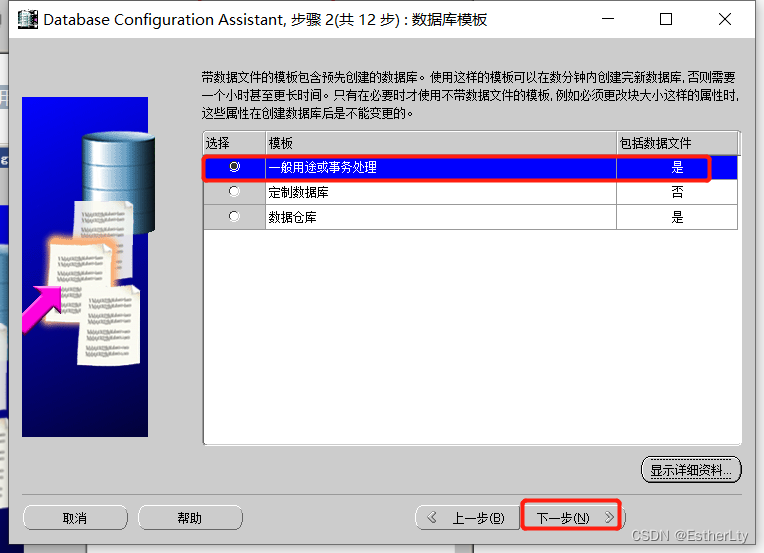
5.填写要创建的“实例名”(根据自己需要的来命名),点击“下一步”
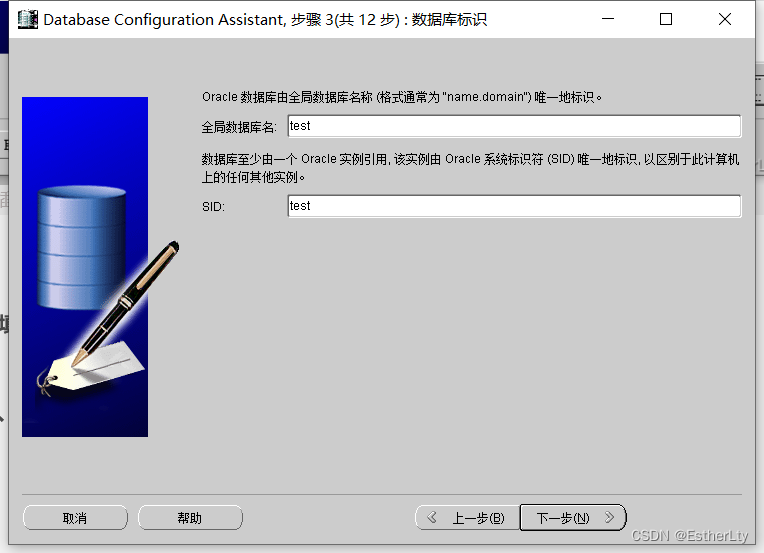
6.默认设置,不用更改,直接点击“下一步”
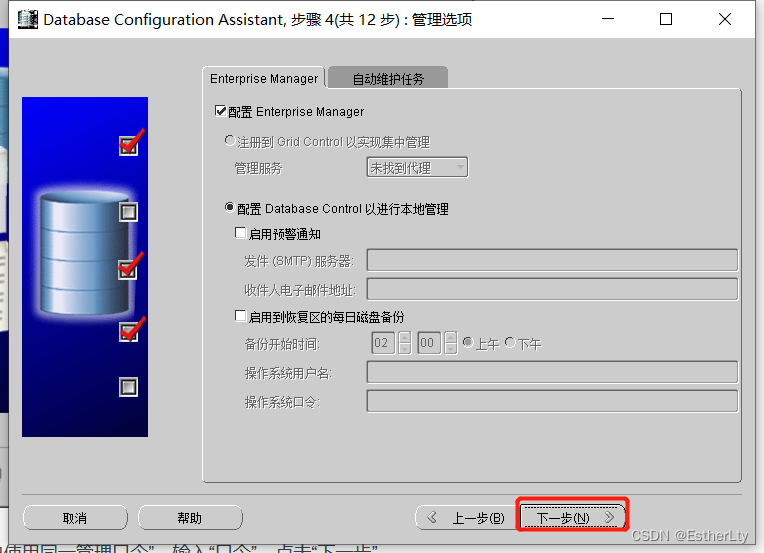
7.选择“所有账户使用同一管理口令”,输入“口令”(口令至少8个字符,包含一个大写一个小写和数字),点击“下一步”
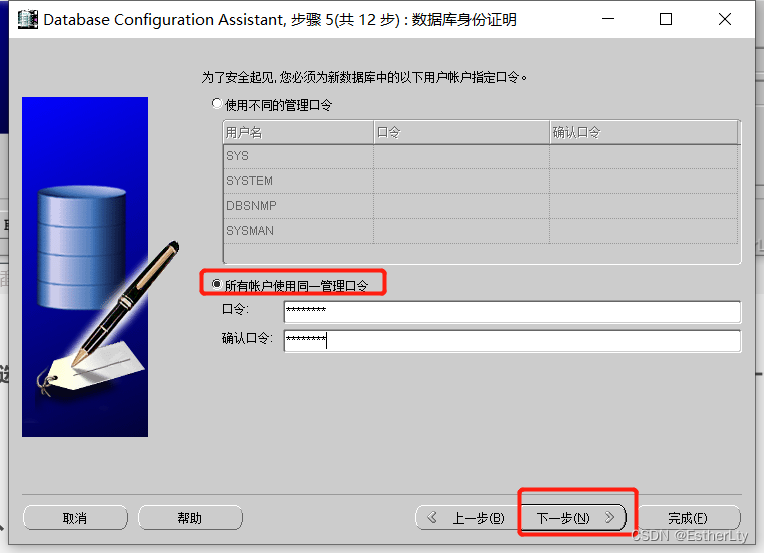
8.默认设置,不用更改,直接点击“下一步”
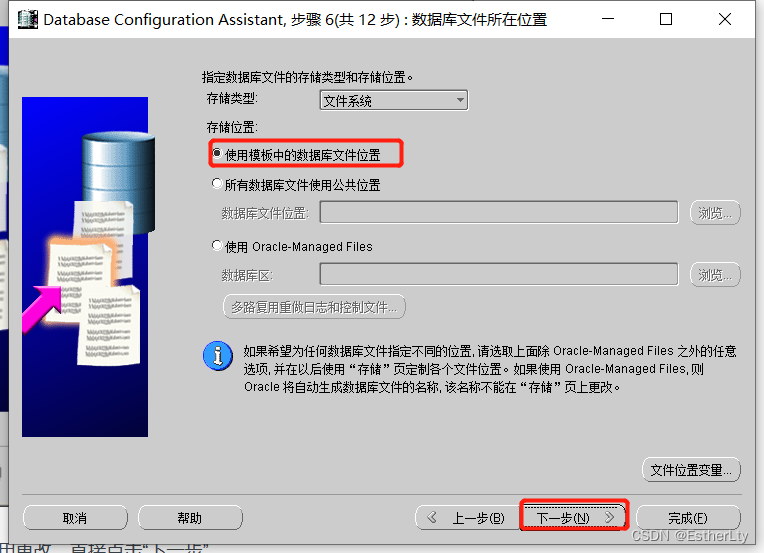
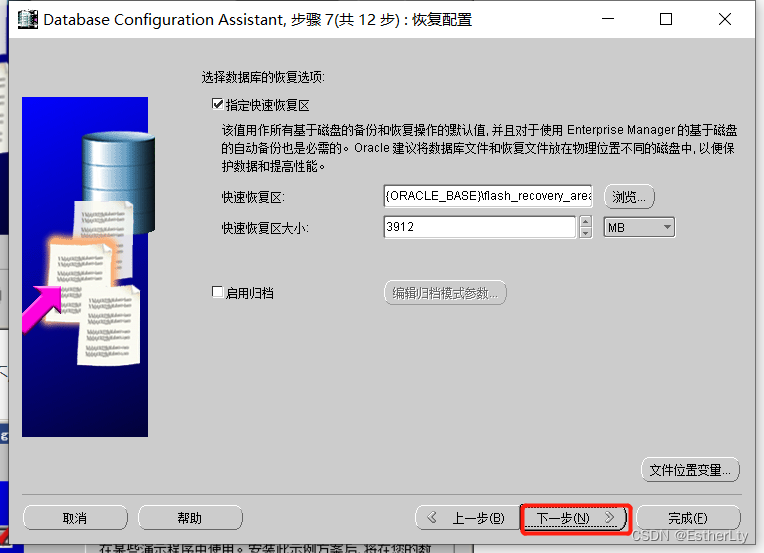
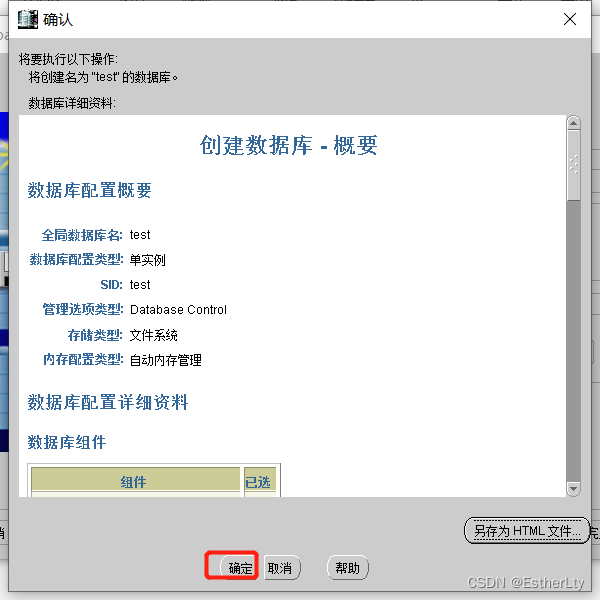
9.检查确认创建“实例”的属性,没有问题,点击“确定”
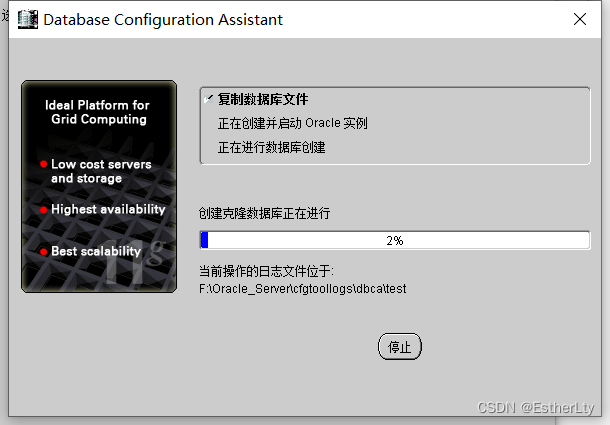
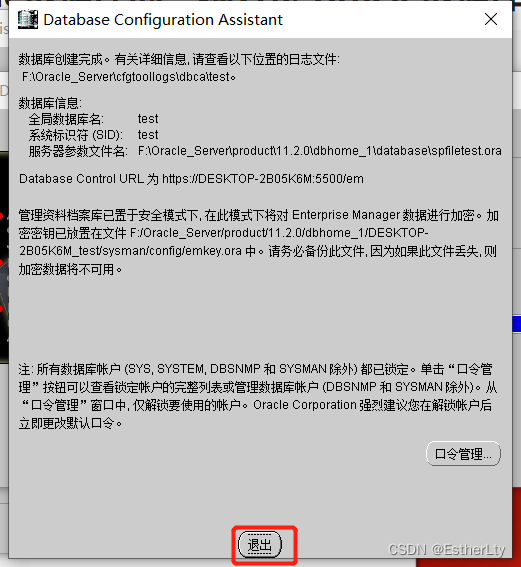
10.创建完成,点击“退出”
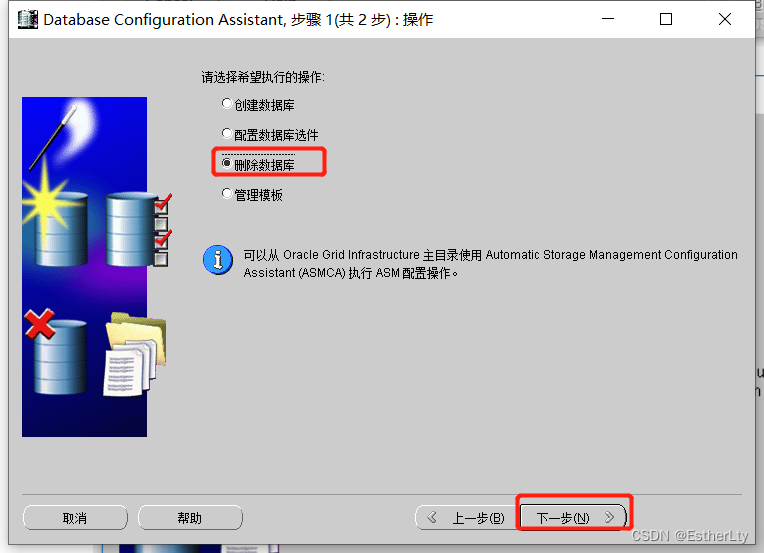
二、删除数据库实例
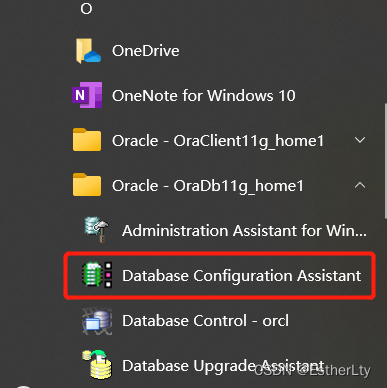
1.点击“开始” -> “Oracle -OraDb11g_home1” -> “Database Configuration Assistant”
2.点击“下一步”
3.选择“删除数据库”,点击“下一步”
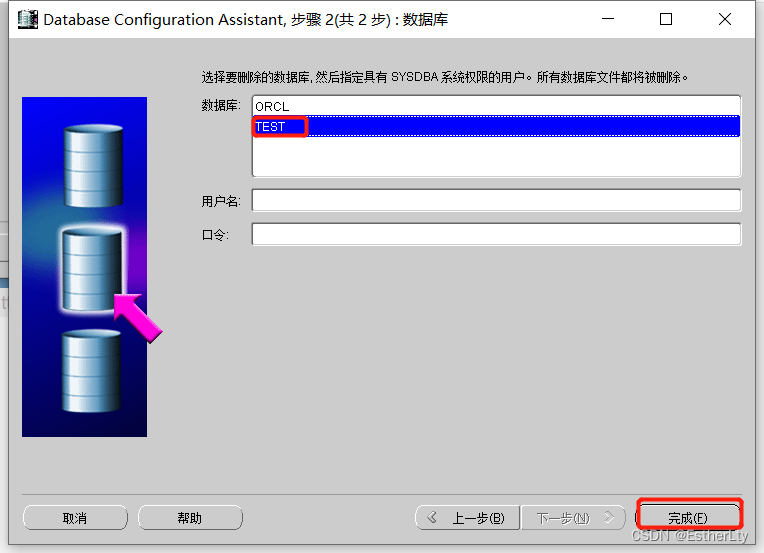
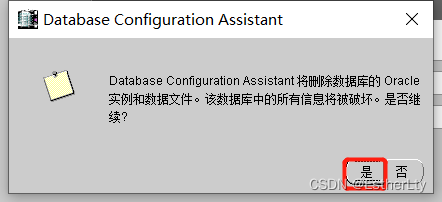
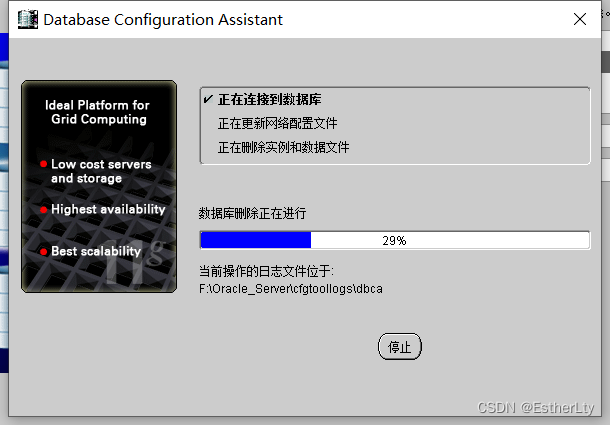
4.选择要删除的数据库,点击“完成”