大濮网最新濮阳消息新闻类网站怎么做seo
1.打开PyCharm,选择File--Settings
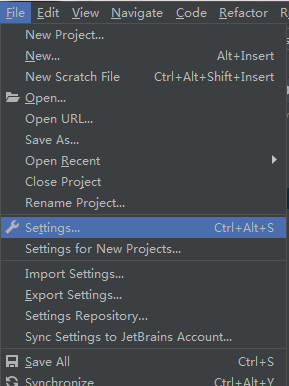
2.依次选择Editor---Code Style-- File and Code Templates---Python Script

3..添加头部内容
可以根据需要添加相应的信息
#!/usr/bin/python3可用的预定义文件模板变量为:$ {PROJECT_NAME} - 当前项目的名称。$ {NAME} - 在文件创建过程中在“新建文件”对话框中指定的新文件的名称。$ {USER} - 当前用户的登录名。$ {DATE} - 当前的系统日期。$ {TIME} - 当前系统时间。$ {YEAR} - 今年。$ {MONTH} - 当月。$ {DAY} - 当月的当天。$ {HOUR} - 目前的小时。$ {MINUTE} - 当前分钟。$ {PRODUCT_NAME} - 将在其中创建文件的IDE的名称。$ {MONTH_NAME_SHORT} - 月份名称的前3个字母。 示例:1月,2月等$ {MONTH_NAME_FULL} - 一个月的全名。 示例:1月,2月等
例如:

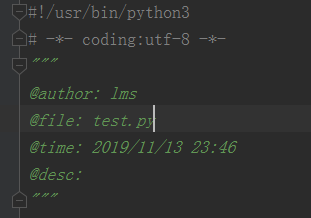
#!/usr/bin/python3
# -*- coding:utf-8 -*-
"""
@author:
@file: ${NAME}.py
@time: ${DATE} ${TIME}
@desc:
"""
显示如下: