网上手机网站建设计划书长春谁家做网站
进程概念
ps -elf:查看操作系统的所有进程(Linux命令)
ctrl + z:把进程切换到后台
crtl + c:结束进程
fg:把进程切换到前台
获取进程进程号和父进程号
函数原型:
pid_t getpid(void); //pid_t,它是一个有符号整数类型。
pid_t getppid(void);
例子:
#include <stdio.h>
#include <sys/types.h>
#include <unistd.h>int main()
{pid_t pid = getpid();printf("当前进程的进程号为:%d\n", pid);pid_t ppid = getppid();printf("当前进程的父进程为:%d\n", ppid);while(1);return 0;
}
fork
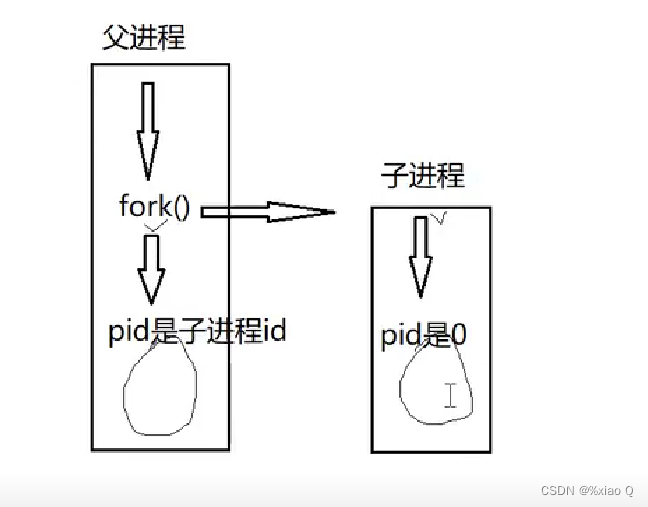
概念:fork() 是一个在操作系统编程中常用的函数,用于创建一个新的进程。它通过复制调用进程(称为父进程)来创建一个新的进程(称为子进程)。子进程是父进程的副本,它从 fork() 函数返回的地方开始执行。
以下是 fork() 函数的原型:
#include <sys/types.h>
#include <unistd.h>
pid_t fork(void);
fork() 函数没有参数,它返回一个 pid_t 类型的值,表示进程的状态。返回值有以下几种情况:
- 如果返回值是负数(-1),则表示创建子进程失败。
- 如果返回值是零(0),则表示当前代码正在子进程中执行。
- 如果返回值是正数,则表示当前代码正在父进程中执行,返回值是新创建子进程的PID。
例子:
#include <stdio.h>
#include <sys/types.h>
#include <unistd.h>
#include <stdlib.h>int main()
{ pid_t pid = fork();if(pid == -1){perror("fork");exit(1);}else if(pid == 0){ printf("child pid=%d, getpid=%d, getppid=%d\n", pid, getpid(), getppid());
// while(1)
// {printf("child\n");sleep(1);
// }}else { printf("parent pid=%d, getpid=%d, getppid=%d\n", pid, getpid(), getppid());
// while(1)
// {printf("parent\n");sleep(2);
// }}printf("helloworld\n");//会输出两次return 0;
}
fork笔试题
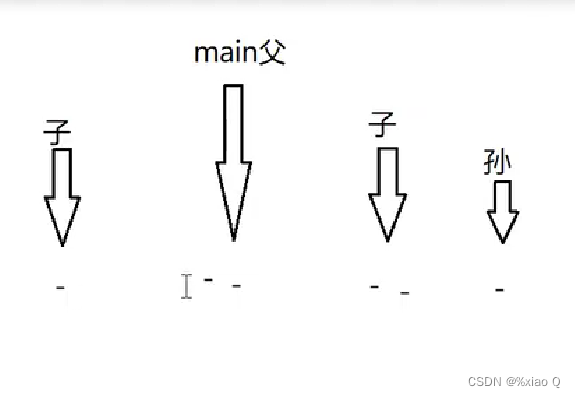
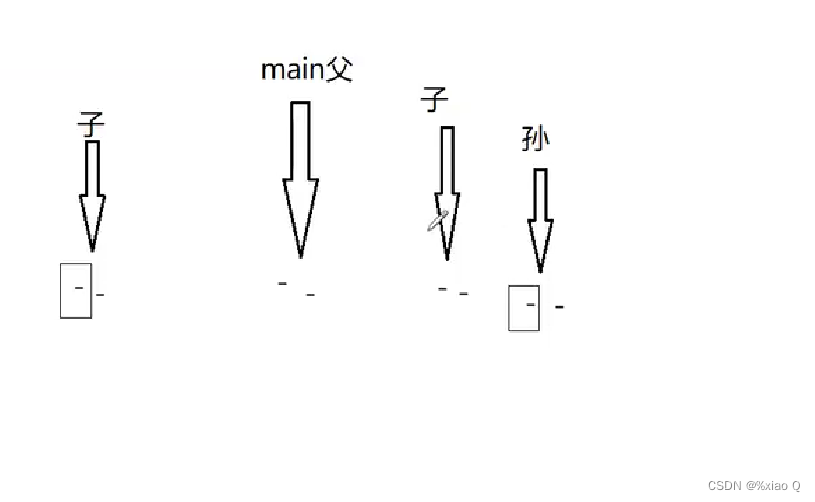
详情看下述代码:
#include <stdio.h>
#include <sys/types.h>
#include <unistd.h>int main()
{for(int i = 0; i < 2; i++){ fork();// printf("-\n"); //6个"-",换行符会输出缓冲区里的的数据printf("-"); // 8个"-",子进程会复制父进程输出缓冲区的数据} return 0;
}
fork原理
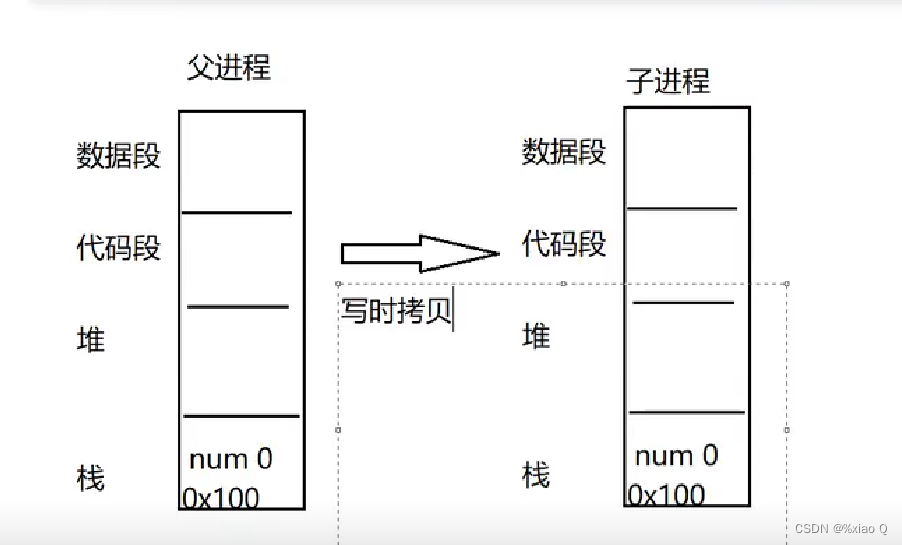
下面输出都为1的原因是,父子进程在不同的空间
#include <stdio.h>
#include <sys/types.h>
#include <unistd.h>int main()
{ int num = 0;if(fork() == 0){ num++;printf("child %d\n", num);} else{ num++;printf("parent %d\n", num);}/*输出为:child 1parent 1*/return 0;}
多进程读写
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <stdlib.h>
#include <unistd.h>
#include <string.h>void child_write(int fd)
{char buf[128] = {0};while(1){scanf("%s", buf);if(write(fd, buf, strlen(buf)) == -1){perror("write");break;}lseek(fd, -1 * strlen(buf), SEEK_CUR);if(!strcmp(buf, "bye"))break;memset(buf, 0, 128);}//i lseek(fd, -1 * strlen(buf), _CUR);}void parent_read(int fd)
{char buf[128] = {0};while(1){int ret = read(fd, buf, sizeof(buf));if(ret == -1){perror("read");break;}else if(ret == 0)continue;if(!strcmp(buf, "bye"))break;printf("child get: %s\n", buf);memset(buf, 0, sizeof(buf));}
}int main()
{int fd = open("hello.txt", O_CREAT | O_RDWR, 00400 | 00200);if(-1 == fd){perror("open");exit(1);}if(fork() == 0){child_write(fd);}else{parent_read(fd);}close(fd);return 0;
}